亿铸科技为AI大算力芯片发展注入新动能
2023-07-17 17:37:03AI云资讯1633
亿铸科技于算力创新发展及应用赋能论坛演讲回顾
2023年,注定是人类AI技术发展进程中里程碑式的一年。上半年,ChatGPT风靡全球,大模型百花齐放,AI应用进入了2.0时代;下半年,AI算力芯片的技术迎来突破,存算一体开启AI算力第二增长曲线,亿铸科技基于新型忆阻器的存算一体AI大算力芯片工程验证芯片将回片点亮,打破存储墙,基于传统工艺制程可实现500-1000T单卡算力。
2023年7月5日,由全球数字经济大会组委会主办、中国信息通信研究院(以下简称“中国信通院”)承办、开放数据中心委员会(ODCC)协办的“2023全球数字经济大会—算力创新发展及应用赋能论坛”举办。数字经济已成为重组全球要素资源和影响全球竞争格局的关键力量,算力作为支撑产业数字化和数字产业化的重要因素,正在数字经济发展中扮演越来越重要的角色。

亿铸科技创始人、董事长兼CEO熊大鹏博士在会上发表了题为《存算一体超异构为AI大算力芯片发展注入新动能》的演讲。
熊大鹏博士表示,AI应用2.0时代的到来将会促进更行各业的发展,许多过去只存在于想象中的应用场景也会迎来落地。
对于大模型的参数量未来的发展趋势,熊博士认为未来可能会有两种发展方向:一种趋势是模型将会越来越大,向着TB级以上的趋势发展;而另一种则是模型在具体的垂直领域被优化、“蒸馏”到一定规模,比如3-9个GB的大小。
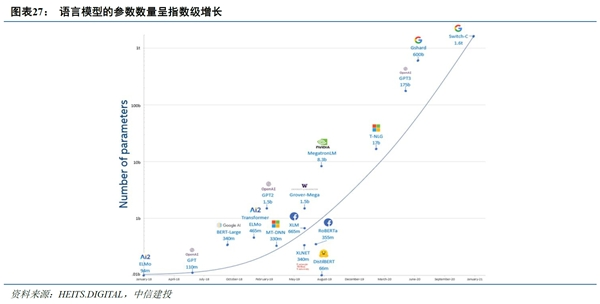
大模型成为“三超”大户,算力需求、能耗、成本狂飙
目前的大模型呈现出“三超”的特点,即:超费电、超费钱、超聪明。
AMD全球CEO Lisa Su在ISSCC 2023的主题演讲中提到,根据目前计算效率每两年提升2.2倍的规律,预计到2035年,一个超级计算机需要的功率可达500MW,相当于半个核电站能产生的功率。
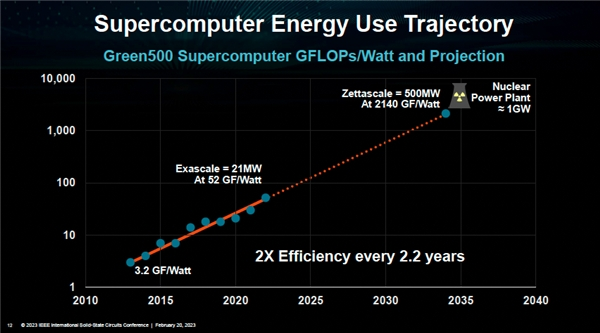
同时,大模型由于参数量大、计算量大,需要更大体量的数据和更高的算力支撑,因此对芯片用量的更大需求、芯片规格的更高要求,已经成为明显趋势。
从技术环境来讲,未来数据量越来越大、模型算法越来越复杂,而支撑底层算力的摩尔定律却几近终结。巨大的剪刀差落在AI大算力芯片企业产业链的肩上,就带来了巨大的压力——有效算力的增长率、软件的编译、数据的带宽、存储的成本、能效比、生产工艺……
AI芯片经历了几代技术架构更迭,从最早的ASIC包括DSA,再到GPGPU,而即便产业使出浑身解数,不断优化架构、工艺制程卷到5nm甚至更低、再用上先进封装技术……对大模型来说,还是不够用。
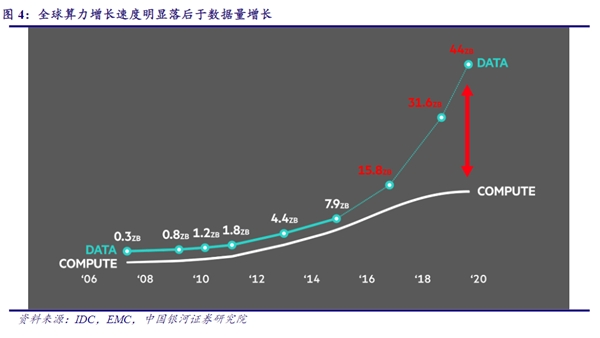
AI2.0时代的“战役”才刚刚打响,就发现没有“子弹”。必须探索新的架构与技术,让算力不仅提升2、3倍,未来还能得到数量级的提升。
传统的冯·诺伊曼架构存在存储墙等挑战。在冯·诺伊曼架构之下,芯片的存储和计算区域分离。计算时,数据需要在两个区域之间来回搬运,而随着神经网络模型层数、规模以及数据处理量的不断增长,数据面临“跑不过来”的情况,成为高效能计算性能和功耗的瓶颈。面对存储墙带来的诸多挑战,存算一体是公认的最佳解决方案。

阿姆达尔定律是硬件加速设计的基本定律。这个定律包括两个因子,一个是加速器规模α,可以用先进的工艺或者优化设计去提升其工作频率,叠加之后就形成了 “裸算力”;而另一个因子F则是在计算周期里数据访存所占的百分比。某国际知名AI算法头部企业的科学家最近研究发现,F值达到了90%以上。这意味着即使现在用5nm,将来做到0.5nm;现在花1亿做一颗芯片,将来花10亿去做一颗芯片,可以提升的性能空间也只有10%。
那么,如何减小F值呢?近存储计算是一种途径。例如,特斯拉的Dojo D1用近存储计算,如果能将F值降到0.2、0.3,这意味着即使工艺还是7nm,性能也会提升3-4倍。
亿铸科技希望通过存算一体把F值降低到0.1以下,如此一来,未来芯片的性能提升将主要取决于工艺的提升和设计的优化。
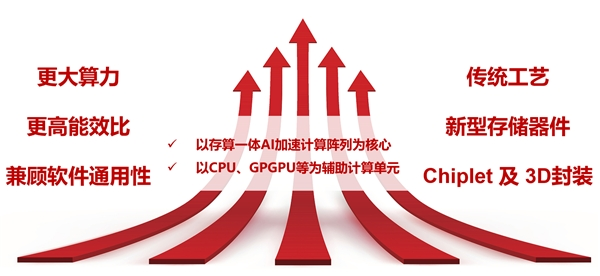
亿铸科技的存算一体超异构芯片以存算一体(CIM)AI加速计算阵列为核心,将基于传统工艺与新型忆阻器技术,结合Chiplet与3D封装,实现更大算力、更高能效比,同时兼顾软件通用性的AI大算力芯片,开启一条换道发展之路。
相关文章
- 阳台储能开创者疆海科技完成数亿元 B 轮融资,押注 AI 时代的家庭能源中心
- 开源!鲸智百应升级,浩鲸科技重新定义企业AI原生
- 万兆AI惠商 联通美好未来 ——中国联通东莞市分公司5・17 电信日暨联通客户日活动圆满举行
- 中国联通在北京地区携手华为发布3000M宽带新产品,全光臻宽带矩阵为“双万兆AI提质行动”添砖加瓦
- 超显商城整合核心GLED显示技术,开启显示设备AI定制新模式
- 博大数据荣膺“全球AI生态基石大奖”,夯实融合算力基础设施服务商领先地位
- 全国人工智能发展大会 AI HANGZHOU 2026中国(杭州)国际人工智能展览会
- 酷开发布企业AI操作系统 开启硅基管理新时代
- 酷开AIOS:定义“企业AI操作系统”的野心与挑战
- 华为超千兆新品亮相山西!三频Wi-Fi 7+AI 焕新智慧家庭新生活
- 辽宁与华为联合发布超千兆三频Wi-Fi 7+AI 新品,共筑辽沈智慧家庭新生活
- 亿达科创亮相国际人工智能展再获AI大奖
- 花旗银行报告称,台积电在AI领域的主导地位不会受到英特尔威胁
- 华为云创想者大会主题论坛议程公布:释放Agentic AI新布局
- 与AI同行 3000M助力 共创智家新生活——中国联通品牌与产品辽宁宣传推广会 全面启动联通社区惠民行系列行动
- 以创新设计重塑 AI 路由未来,MOVA LINCO X1 Pro 荣膺红点奖
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


