汇付天下AI应用丨LLM在投诉风险管控中的应用实践
2025-05-14 09:13:49AI云资讯2015
一、前言
LLM(即Large Language Model,大语言模型)的通用能力在聊天、翻译、文本生成/分类、情感分析、图像描述等方面表现优异,例如:DeepSeek-R1擅长数学、代码和自然语言推理等复杂任务,百度文小言能支持多种方言的语音交互,Gemma3具备分析文本、图像及短视频的能力等。在数学、编程等很多领域,其知识已达到了博士水平。
但LLM的弱势在于它只是一个由历史数据预训练出来的聪明“大脑”,它可以提升终端(电脑、手机等)的智能化水平,但它不会自主学习,不具备自主迭代更新知识储备的能力,在职场上,我们需要的不是一个只会聊天的助手。因此需要给它加上控制各类工具的能力,如同给其安上“手脚”,组装成一个虚拟机器人,这种进化后的LLM在业界被称为Agent(即自主智能体),然而这只是极大地拓宽了应用边界,其主体仍是LLM。
由中国创业公司Monica发布的全球首款通用Agent产品Manus,已在业界广为流传,它具备从自主规划、思考、行动,执行全流程任务并最终输出完整成果,如:撰写产研报告并输出为pdf文件。同样的闭源智能体项目还有OpenAI的Deep Research和Operator等,而知名的开源项目有OpenManus、OWL、Deep Searcher等。
但目前的Agent仍处在成长和探索阶段,尚未出现一款完整、成熟、稳定、被广泛接受和传播的产品,在许多真实场景中仍需做定制化的二次开发,或者落地小型Agent,即让LLM在限定规则下调用少量工具。
二、LLM在风险管控方案中的设计思路
LLM在风险管控中的应用方案大致可分为两大类:封闭式方案、开放式方案。
封闭式方案:是指整体流程清晰和标准化、目标明确、有备选答案且可选项有限,追求可控、可解释、高准确率为目标的业务方案。
开放式方案:通常应用于探索未知领域,无预设答案,无既定流程,目标也可以不用提前明确,需要进行发散思考,在反复试错、验证后最终获得最优解,答案通常不唯一,样式可以灵活多样。
在支付行业风险管理的应用实践中,更多的是应用封闭式方案,从而保证“风险可控、管控合理且可解释、标准化下的高准确率”的基本要求。而开放式方案主要适用在新型风险案件出现后的探索工作,去分析和尝试个性化的策略方案。
如果方案中需加入Agent,则可通过“感知-规划-行动-决策”的链路来设计:
·通过LLM来“规划”和“决策”,当任务出现后,去识别意图、分解需求、制定/协调/分配任务、确定使用何种工具,而待信息收集完整后,则做分析判断并输出决策和结论等。
·通过工具来“感知”和“行动”,通过网络去获取现实世界中实时、最新的辅助信息,与内外部知识库、数据库做即时交互来补充所需信息等,通过工具来执行各类代码、操作各种文件、操作浏览器等。
另外,基于信息安全的基本要求,同时考虑到提示词工程下开发训练模型,需耗费巨量的token并产生不菲的费用,我们选择公司内部私有化部署LLM平台。而在选取使用哪几款LLM做私有化部署前,或者判断哪款新面世的LLM是否有必要替代已部署的LLM,则可以通过外部API方式做小规模测试评估,然后再做出决策,从而兼顾性能和成本。
而在Agent应用上,若选择私有化部署开源项目,缺点是需要较多人力做二次开发和维护,优点是可以深度融入进现有的风险管控方案中。目前国内已推出多款免费的闭源Agent项目,在网络信息采集、汇总并撰写报告方面的表现优于闭源项目,因此在这方面的工作上可以选择闭源项目。
三、LLM在投诉风险管控中的应用实践
1.与现有投诉风险管控方案的比较
在LLM加入之前,我们已经积累了很多标准化流程和成熟的应用案例,应用中使用多种机器学习算法和复杂的规则引擎。
“传统范式”是借助“多种算法”和“代码语言”来开发模型。如借助TF-IDF、TextRank等多种算法,并配上大量的代码去综合分析和挖掘关键词,再借助StructBert模型对风险提示词做评分,将多个同类评分做综合判断并输出一种风险标签,而多种投诉风险类型需对应开发多个模型,因此会产生多个子模型并行跑批。
在LLM加入之后,模型开发方面如同面临一次“范式革命”,由自动化为主的“数字化”改造,合并升级成以LLM为主的“数智化”变革。
“新范式”是借助“多个LLM”和“自然语言”来开发模型(而随着支持多模态的单个LLM逐步变强,其中“多个LLM”将降为“一个LLM”)。开发模型时,主要使用的是自己擅长的母语,并借助一个擅长文本模态的LLM来挖掘关键词。而原来的“特征工程”则转为“提示词工程”,所开发的这一个LLM投诉风险分类模型是由大量的提示词组成所需的自然语言指令。而这一个模型便可输出多种风险分类标签,因而不再需要开发多个子模型,故模型开发量大幅下降,代码量大约只需要原来的5%。
2.应用LLM的封闭式方案介绍
为保证“新范式”仍能保持风险管理所要求的高准确度和稳定性,在初期阶段,需实施“双轨制”模式,即现有的“传统范式”继续运行,“新范式”与其在同一体系内同时运行,两者同步优化迭代。
这样的模式虽然较“重”,但在“新范式”表现尚未充分时,仍是最稳妥的模式。但到后续阶段,可根据“新范式”的表现情况,逐步将其升至主导地位,直至最终可能弃用“传统范式”。
全套的“双轨制”模式如下图所示:
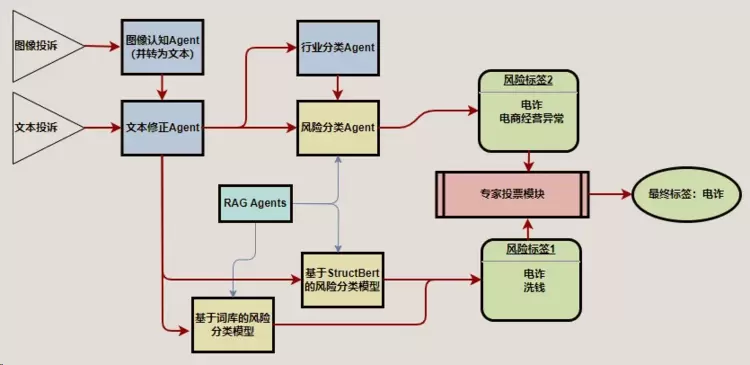
“传统范式”在图中下方的第一条轨道上运行,投诉风险分类包含2个小模型:
(1)“基于词库的风险分类模型”,由一个包含1700多条逻辑组合的规则集,对11种风险投诉进行标签判断;
(2)“基于StructBert的风险分类模型”,该模型包含11种风险对应的11个子模型,而每个子模型也是由多个提示词的评分来综合判断是否属于该类风险并标注风险标签。而这套复杂方案,会再次做综合判断并给出图中的“风险标签1”。
“新范式”在图中上方的第二条轨道上运行,做投诉风险分类的模型只用1个,即“风险分类Agent”,这一个模块即基于提示词工程开发投诉风险分类模型,它在限定规则下,调用和执行Python、SQL代码,从内部数据库采集需判断的投诉数据,完成分类后将风险标签传输回内部数据库中的指定数据表中,即产出图中的“风险标签2”。
“风险分类Agent”的提示词工程不需要从零开始构建,可从“传统范式”中提取并复用关键词,比如民族资产解冻类诈骗,已被公布的此类项目名称近上百种,可直接加进提示词,对于投诉中包含此类项目的则直接判断并标签为“民族资产解冻类诈骗”;但对于需要语义理解的情况,则可通过定义、规则限制和引导LLM来做适当地推理和判断。
因为两套方案的评判标准和开发模式有所不同,会使得判断的结论也会出现不同,如图中案例,风险标签1为“电诈、洗钱”,风险标签2为“电诈、电商经营异常”,这时通过“专家投票模块”来求同存异,留下相同的标签并最终输出标签“电诈”。
对于出现不同标签结论时,需使用“对齐机制”来保证两套方案结论的高度一致性。比如,A模型的结论更准确,则通过人工分析A模型的判断逻辑,调试和融入到B模型后,使两者输出相同结论。
本方案采用Multi-Agent框架,除了“风险分类Agent”外,还包含“RAGAgents”、“图像认知Agent”、“文本修正Agent”、“行业分类Agent”,通过LLM的能力,同时强化“传统范式”的智能化水平和模型效果。此框架为“标准框架”,实际应用中需根据不同风险投诉的特征和管控需要,对实施框架做对应的增减或调整,从而以最佳的模式去灵活应对各类风险投诉。
以下分别介绍各主要模块:
1)RAG Agents
RAG(全称为 Retrieval Argumented Generation),即检索增强生成,是为了补充并增强LLM的能力,使其尽量和现实世界对齐的一种技术路线。而“RAG Agents”则由多个检索增强生成的Agent组成,针对电诈、民族资产解冻类诈骗等,它们会定时去网络上收集、学习最新的外部信息,汇总新增风险案件、风险项目名称、关键词等做成清单,经由人工审核后,判断是否需要加入进风险分类模型的判断逻辑中,从而保证模型“与时俱进”。
2)图像认知Agent
约20%的投诉因为文本投诉内容未提供、表述不明确等原因导致无法从文本投诉来判断是否属于风险投诉,但这些投诉同时提供了照片/截图等图像信息,而从图像投诉中可以获取到作为判断风险的有用信息。因此需要“图像认知Agent”来将图像内容分析、描述并转换成文本内容,并补充进文本投诉内容中。虽然其中约95%的图像投诉属于纠纷,而非风险投诉,但这个Agent让我们可以覆盖到约20%的投诉风险管控盲区。
3)文本修正Agent
文本投诉会存在种种问题,而“图像认知Agent”传输过来的文本信息也可能需要修正,而且两块的文本内容需要有效地合并到一起,这时需要“文本修正Agent”来完成这项工作。
修正,一方面是让LLM把错别字、脏数据等进行清洗加工,比如“和网上街勺不相符,色1情视频照片引导炸骗”,如果用传统的算法,可能不一定能判断出这条投诉涉及“色情、诈骗”,因为“色情”两个字中间多了个“1”,而“诈骗”出现了错别字“炸”。经过LLM修正后,则改为“和网上介绍不相符,色情视频照片引导,是诈骗”。
修正的另一个方面,则是翻译各种语言,比如以下文本:«گۇرۇپپىدايۇقىرىپايدادەپچىقىرىلغانبىرسەرمايەقويۇشتەكلىپىنىكۆرۈپ،ئەپنىچۈشۈرۈپپۇلتۆلىدىم،كېيىنئەپئاچالمىدىۋەپۇلچىقىرالمايدىغانبولدى»
因为一个公司需要配备懂得多种语言的多名员工去选取外文投诉做人工翻译,然后才能实现对于该类语种的风险分类和管控,这样的成本和人力耗费较高,而LLM出现后则仅靠一个大语言模型就可以解决这个翻译工作,同时自动将翻译结果返回到数据库中。
这条例子,LLM的推理内容会告知这是维吾尔文,翻译后的内容是“在群里看到一个被宣传为高收益的投资建议后,我下载了该应用并支付了费用,但之后应用无法打开且钱也没有退回”。而这将帮我们捕获到一条投资理财类的诈骗投诉。
另外,还会出现投诉内容都是英文大写,没有空格或符号隔开,只有一串英文的案例:ISAWAHIGHRETURNINVESTMENTPROJECTINTHEGROUPCHATCLAIMEDTOOFFERSUBSTANTIALPROFITSSOIDOWNLOADEDTHEAPPANDMADEAPAYMENTLATERTHEAPPSTOPPEDWORKINGANDICOULDNTWITHDRAWMYFUNDS
这时就算英文再好的员工也会觉得为难,但LLM则能轻而易举的将其转换成正常的英文内容,如下:
I saw a high-return investment project in the group chat claimed to offer substantial profits. So I downloaded the app and made a payment. Later, the app stopped working and I couldn’t withdraw my funds.
然后,它会再将其翻译成中文。因为作为示例用,可见这笔投诉内容是之前那条维吾尔文投诉的英文版。
以上修正功能完成后,这个Agent可以让我们覆盖到约10%的投诉风险管控盲区。
4)行业分类Agent
因为不同行业的管控方式和力度不同,因此需要“行业分类Agent”做提前分类,从而保证投诉风险的精细化管控,而且在线下测试评估后发现,若将行业分类Agent合并到风险分类Agent中,会导致提示词过于繁多,其规则逻辑间会存在互相影响等问题,而且不易定位到导致误判的原因点在哪里,就算让LLM来帮你定位大堆提示词中的优化点,结果也不一定能尽如人意,因此不建议合并这2个Agent。
我们可以从大类开始分:线上行业、线下行业、不确定。然后再继续下钻,比如线上行业,如话费充值类诈骗案件,历史出现的风险案件主要集中在线上,因此对标签为“线上行业-话费充值”的做强管控,而“线下行业-话费充值”则做弱管控,实现区分并做差异化管控。而类似赌博、色情类风险,则均需做强管控,因此可以不用关注行业分类结果。
应用成效:
“传统范式”下的模型,其风险投诉覆盖率约70%,基于该覆盖率下的风险投诉分类准确率约97%;而今年Q1上线后的“新范式”的风险投诉覆盖率能达到约98%,较原范式可提升28%,且在这个高覆盖率下,其风险投诉分类准确率较原范式还能有所提升,能较稳定地保持在99%左右。
而基于“新范式”下覆盖的风险投诉标签,针对商户投诉风险管控所上线的风险处置类规则共86个,其中准实时规则共4个、离线规则共82个,在今年Q1的风险商户处置量共1462个,较“传统范式”提升约12%,该批处置类规则总体准确率约99%。
处置类规则准确率虽然很高,但牺牲了部分风险商户的管控覆盖,而这块商户最终表现是出险而需要被处置的。为了保证处置类规则的高准确率,此类规则的阈值设置相对偏高,这块商户在风险投诉量级和浓度未达一定程度、其他风险指标未到一定水平时,只做预警处理,因为没触达处罚标准而躲过了处置类规则的管控。若通过降低阈值来覆盖到这部分商户,则会连带误杀到优质商户。因而会通过再次开发更精细化的管控规则,或通过其他维度的策略维度来更多地覆盖到此块风险商户。
四、未来展望
LLM在“双轨制”模式和Multi-Agent的结合下,其应用成效显著,各项指标也达到了历史新高,在管控指标上可以提升的空间已经有限,但在其他方面仍有提升余地。
如“双轨制”模式下的“重”体量,使其在人工维护成本上较高,在对齐时基于更准确的A模型来同时优化B、C模型时,要耗费较多时间来让不同类型的模型输出相同结论,同时要做充分的验证,像LLM开发的分类模型,需要至少近三个月的投诉样本量做验证,才能保证该提示词工程的通用效果保持一致。
而LLM仍会出现偶尔的推理失误,多数情况是因为提示词写的不够严谨导致。而“传统范式”维护成本相对更低,样本回测方面的时效更快,比如调整判断逻辑后,让其在历史一年的投诉数据上重新全量做风险分类,耗时约3分钟,而LLM开发的模型,若一个月投诉量以20万笔计算,20个进程并行跑批也要耗费至少15个小时才能完成风险分类。因此在短期内还不能将该模式变“轻”。
LLM目前未具备自主学习能力,需要通过人工微调来优化预训练模型,而微调的工作量,以及对微调效果的验证也需耗费较高的时间和人力成本。虽然已有一些尝试性的方案出现,但并没有能够真正应用在实际方案中。在自动微调能力未出现之前,这个也是亟待解决的问题之一。
但随着技术的继续发展和各种研究的深化迭代,以上问题也会被逐个解决。而本文主要分享LLM在投诉风险管控的应用实践,我们将在未来的应用研究中,尝试在更多的风险管控场景中将LLM融入其中,同时在运营、客服、营销、法务、研发、人事、财务等方面做诸多的探索和研究。
相关文章
- 开店做生意,就用汇付天下旗下汇来米丨从“有用”到“好用”全面升级
- 共探数智融合,同筑协作生态丨吉祥航空与汇付天下共绘智慧航旅新蓝图
- 深拓行业生态,共筑湾区增长丨汇付天下举行大湾区生态共创沙龙
- 聚焦发展 共赢未来 | 汇付天下旗下汇来米2025服务商攻坚共赢峰会圆满召开
- 汇付天下旗下汇付国际与市采通达成战略合作,共拓跨境全业态支付服务新生态
- 汇付天下技术丨如何支撑海量交易的风控实时决策与灵活扩展
- 汇付天下入选《第十七批上海市重点商标保护名录》
- 十九岁 向未来出发丨汇付天下成立区块链技术实验室,多个AI项目精彩亮相
- 《非银行支付行业年度专题分析2025》发布,汇付天下数字化支付入选优秀案例
- 汇付天下荣获“2025爱分析AI Agent 最佳实践案例”
- 上海交大高金校友引擎计划 · 走进汇付天下
- 汇付天下旗下HuePay支付服务升级公告:正式接入支付宝支付
- 汇付天下技术丨移动APP跨平台技术融合演进
- 澳洲金融科技圈新动态:汇付天下旗下HuePay成功加入FinTech Australia!
- 汇付天下AI应用丨LLM在投诉风险管控中的应用实践
- 汇付天下周晔:支付的破与立 都离不开技术创新
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布


