融合创新,更懂AI|宏杉科技算力调度一体化解决方案
2025/08/08 16:27AI云资讯11995
当前,人工智能正处于快速发展阶段,算力需求呈指数级攀升,构建融通高效的算力调度中枢,对深化大模型应用、加速业务创新至关重要。宏杉科技推出算力调度一体化解决方案,一平台统筹全局算力,一站式激活AI效能,助力行业客户智胜AI时代。
三大核心挑战,制约算力价值释放
作为数据中心高效运转的关键支撑,异构计算架构通过整合不同类型的计算资源,显著提升了系统性能。然而,这一架构下的算力调度却面临着协同效率、资源效能与弹性能力的三重挑战,严重制约了算力价值的释放。
●混合调度困难
在AI应用的关键业务场景中,计算流程深度依赖于CPU和GPU的协同。若调度系统各自为战,则会陷入效率低下的困境:训练阶段GPU等待CPU预处理数据,推理阶段CPU排队拖累GPU输出,端到端延迟居高不下。
●资源效能桎梏
有限且昂贵的算力资源因“调度错配”沦为闲置:GPU被占满时,CPU因负载失衡导致请求阻塞,最终陷入“硬件空转、任务积压”的恶性循环,资源利用率大打折扣。
●弹性伸缩难题
AI大模型的最终落地涉及到训练、推理等多流程的协作,而各阶段的业务需求差异显著:推理请求可能突发峰值,任务模式呈现夜间训练与白天推理的周期性交替,仿真任务则带有间歇性特征。这些都对算力调度的灵活性提出了极致要求,传统静态分配模式已难以适配。

一体化算力中枢,实现CPU/GPU算力高效协同
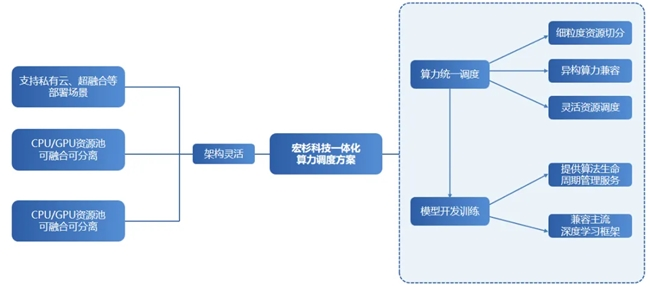
宏杉科技算力调度一体化解决方案,通过宏杉云与GPU的融合部署,打造具备异构算力协同能力的智能AI应用平台,为用户提供CPU与GPU异构算力的一体化调度能力。
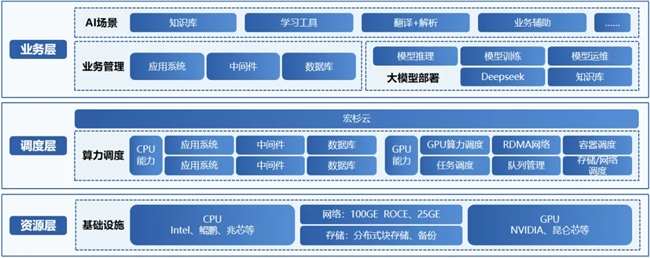
算力统一调度,激活资源潜能
方案通过构建智能算力调度引擎,实现CPU与GPU资源的精准协同与动态分配,全面释放异构计算潜力:
●细粒度资源切分:将GPU资源精准拆分为小算力单元,满足轻量推理、小规模训练多样化需求,实现闲置算力资源的充分复用。
●异构算力兼容:广泛适配 NVIDIA、昆仑芯等国内外加速卡,通过资源虚拟化技术实现异构硬件的统一调度,支持物理显卡与虚拟显卡统一管理,构建一体化异构算力资源池。
●灵活资源调度:支持RDMA网络与容器调度,为GPU集群提供低延迟、高带宽的通信支撑,结合动态任务调度策略,实现算力供需的精准匹配,系统性提升GPU利用率。
全生命周期赋能,加速大模型落地
方案提供便捷易用的算法生命周期管理服务,覆盖数据管理、模型开发、训练、推理全环节。兼容PyTorch、PaddlePaddle、TensorFlow等主流深度学习框架,助力大模型快速开发、精调与部署。
多场景灵活部署,动态匹配业务需求
●部署场景多元:兼容私有云、超融合等部署场景,CPU与GPU资源池可按需选择融合或分离部署,适配多样化基础设施环境。
●远程弹性调度:具备跨节点远程调用能力,可为虚拟机、物理机动态分配算力资源,结合弹性伸缩机制,精准应对业务的突发性、周期性波动,保障资源供给与业务需求的动态平衡。
随着AI大模型在各行各业的加速渗透,算力调度的重要性日益凸显。宏杉科技算力调度一体化解决方案通过打破资源壁垒,充分释放算力价值。未来,宏杉科技将致力以智能存储与高效计算的协同创新,持续赋能千行百业智能化升级。
相关文章
- 港城大领衔举办“未来计算.未来算力“论坛 推动量子智慧产业联盟启动
- 量子与太空:未来算力方向的探索
- 恒通股份20亿印尼产业园暗藏算力主线!踩中东南亚AI风口
- WAIC 2026|从算力底座到Agent,全栈AI基础设施赋能Token经济
- 浦新篇 AI共赢|维谛技术(Vertiv)2026合作伙伴大会共绘AI算力共赢新蓝图
- WAIC 2026 | 科华数据算力基础设施与AI芯片协同发展论坛圆满落幕!
- 全栈算力破局落地难题,超云携全新大模型推理方案亮相 WAIC2026
- 和合聚众力,开物启芯程!天数智芯 2026 算力生态峰会暨新品发布会举办
- 东方算芯亮相WAIC 2026,聚焦国产大算力芯片与系统方案
- 曦智科技成功举办WAIC首个AI光算力论坛
- MINISFORUM铭凡亮相2026WAIC:布局轻量化本地私有化算力,助力行业AI规模化落地
- 2026世界人工智能大会开幕 “小巨人”凌雄科技AI算力业务和机器人租赁业务备受关注
- 七年WAIC同行,燧原科技持续展示国产AI算力规模化落地成果,共筑Token经济时代算力底座
- MINISFORUM铭凡亮相2026WAIC:布局轻量化本地私有化算力,助力行业AI规模化落地
- 光合组织亮相WAIC 2026,以开放生态推动国产算力应用落地
- 上海交大葛冬冬:AI4S时代需要软硬协同的开放算力生态
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


