PAC 2025:在算力风暴中淬炼的国产力量
2025-12-01 11:15:37AI云资讯2051
2025年的夏天虽已远去,然而PAC 2025的热血余温未散:算力的涌动、屏幕的闪烁、代码的狂奔……那份拼搏与激情,仿佛仍在空气中炽烈燃烧,未曾褪色。
顶尖战队齐聚第21届CCF HPC China 2025的PAC决赛现场,展开正面交锋,将激情与实力尽数倾注 “优化” 与 “应用” 两大赛道,现场氛围燃至顶峰。
赛场的热度,不止是代码奔涌时的风扇轰鸣,更是年轻人拼尽全力时的心跳共振。正是这股激情与执着,凝聚成推动国产计算驶向未来的核心动力。终场哨响,PAC2025并行应用挑战赛圆满收官。
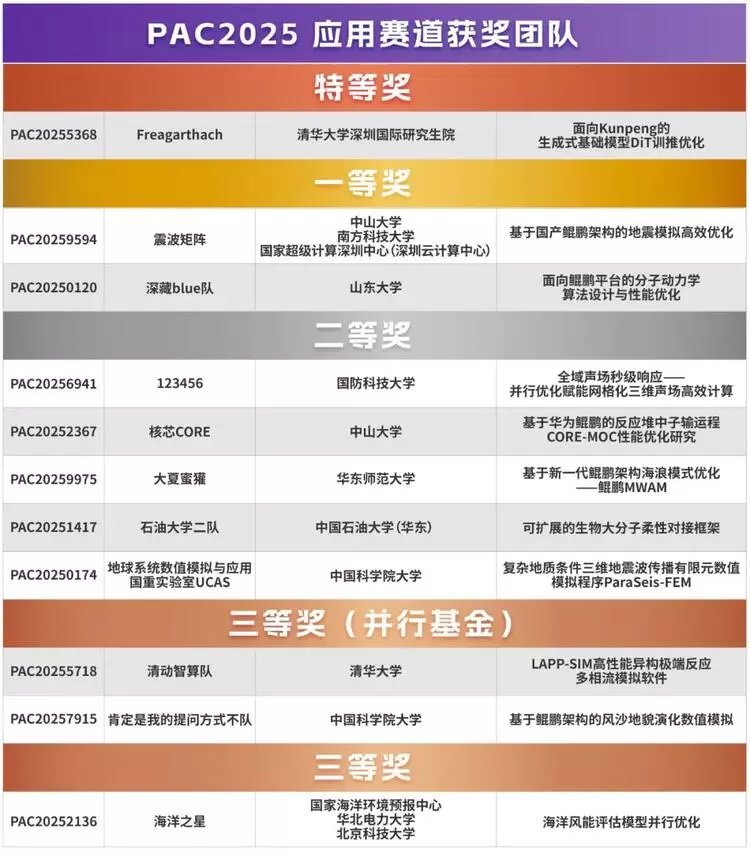
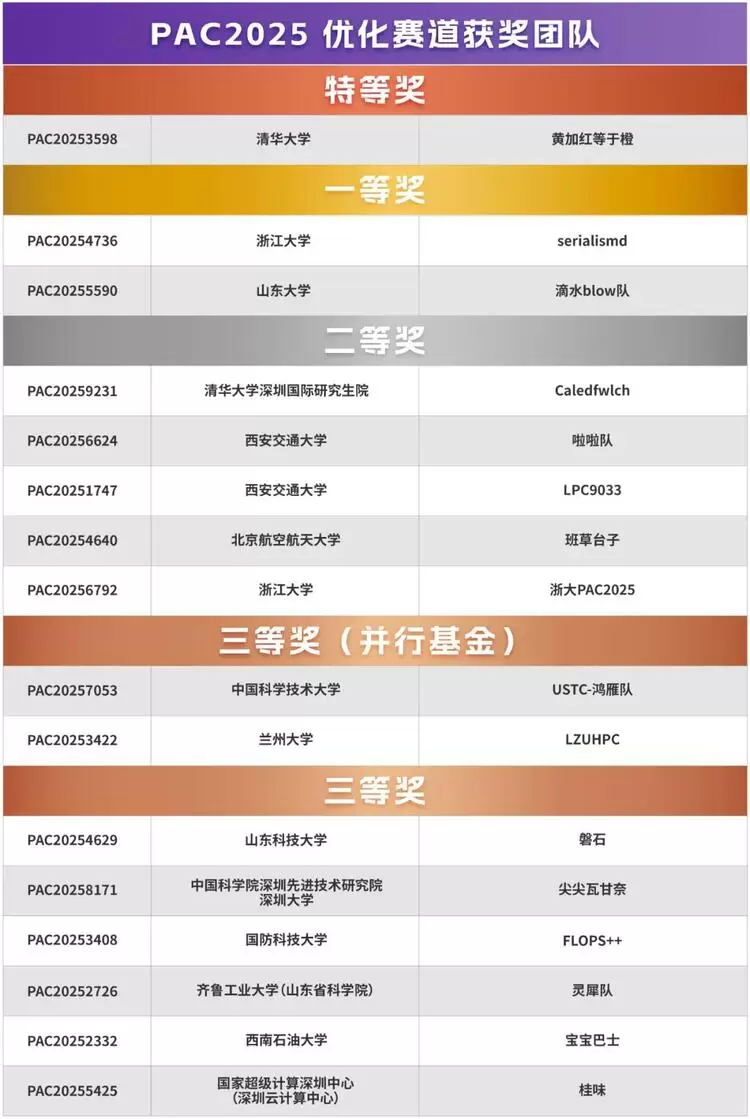
鲲鹏撑腰,满格开战
本届大赛全面采用鲲鹏计算平台作为核心硬件底座。以ARM架构为技术核心,其集成的众核架构、向量/矩阵扩展、片上内存高带宽等硬件特性,成为参赛团队挖掘极致性能的核心载体,也标志着国产CPU平台正式成为高性能计算技术探索的关键阵地。
技术亮点回顾“硬件-软件-应用”的全栈突破
硬件架构特性的深度挖掘:以鲲鹏 ARM 为核心,释放国产 CPU 潜力
ARM 技术的规模化应用:特等奖获得者清华大学深圳国际研究生院团队(简称清华团队)充分发挥矩阵运算可伸缩向量扩展的优势,通过循环重排与数据预取优化GEMM与HPCG性能,最大化鲲鹏CPU的向量计算吞吐。在INT8低精度计算与Attention算子这一核心挑战上,清华、浙大、山大团队均依托鲲鹏平台的矩阵算力,实现了“向量→矩阵”的计算单元升级。例如,清华团队利用矩阵运算单指令完成 Tile 级乘加,大幅降低指令数量与寄存器压力;浙江大学团队则验证“矩阵运算+片上内存”组合的优势,将鲲鹏CPU的带宽与矩阵吞吐拉至接近GPU量级,减少CPU与加速器的数据搬运延迟。
鲲鹏硬件优势的协同验证:山东大学团队在应用赛道中,基于鲲鹏新一代CPU的多核并行与高带宽优势,实现了 20 亿原子体系的分子动力学模拟。在弱扩展8倍、强扩展 4 倍的条件下仍保持80%并行效率,直接证明了国产CPU在超大规模科学计算中的端到端性能,已具备与GPU相当的竞争力。

PAC2025上机现场
软件优化创新:硬件特性与软件策略的深度协同
精细化内存与计算调度:清华团队采用二维 Tiling 策略,浙江大学团队针对K维度切分以充分利用HPC缓存,均将关键数据留驻L1/L2缓存,减少对内存带宽的依赖,适配鲲鹏的缓存架构设计。此外,清华基于 Pthreads 自建线程池,规避操作系统调度开销,实现鲲鹏多核间的任务均衡分配,并行效率较传统方案提升显著。
精度与性能的平衡优化:针对混合精度计算需求,浙大提出“fp32保存中间变量 + svzip 转化为 fp16”的方法,避免了纯 fp16 的指数溢出问题;山大则提出“全流程混合精度向量化”,并自研 ARM 向量化超越函数库,进一步适配鲲鹏平台的指令集特性,在保证计算正确性的前提下,效率提升 20%-30%。
算子级优化突破:山东大学团队在优化赛道中,针对 INT8GEMM 与 Attention 算子提出“数值扩展+算子融合”全栈方案——基于SVSUMOPA/SVMOPA指令实现2路/4路矩阵外积乘法,结合FlashAttention融合策略,减少中间结果访存开销与线程竞争,使大Batch训练与大模型推理的稳定性提升40%以上,为鲲鹏平台的AI算子库建设提供直接技术参考。

PAC2025答辩现场
应用落地突破:覆盖 AI 与科学计算的多领域验证
AI 计算:清华团队的矩阵运算加速与山大的算子融合成果,可直接应用于鲲鹏生态的 AI 芯片与 CPU,为大模型推理(如语音识别、视觉计算)与中小规模训练提供高性能算子支撑,有效解决国产平台“AI计算性能不足”的核心痛点。
科学计算:清华团队的 HPCG 优化与山大的分子动力学模拟,验证了鲲鹏平台在气象、天文、流体力学、药物研发等领域的适用性——如山东大学团队的成果可直接复用至新能源材料设计与复杂流体计算,为国产高性能计算的行业落地提供技术范本。

PAC的意义:从赛场到未来
PAC大赛的成果不是单点的创新打法,而是真正能走出赛场、落到产业的技术。无论是算子优化,还是大规模科学计算模拟,都已具备直接赋能科研与产业的潜力。
PAC 2025的意义,在于夯实国产算力生态,让以鲲鹏为核心的国产 CPU 走向成熟,打破“高性能依赖国外架构”的偏见;在于推动“硬件—软件—应用”的全栈融合,让协同优化成为可复制的范式;更在于将成果带入产业与人才的长远布局,既赋能 AI、大模型、分子动力学等应用场景,也培养出一批能够横跨硬件、软件与应用的青年力量。
从 ARM 架构的深度挖掘,到软硬件的协同优化,再到端到端的应用突破,PAC 2025 让国产算力不再只是“能用”,而是真正“好用”。它证明了我们不再只是被动追赶,而是已能与前沿并肩而行,正全力奔向属于中国的高性能计算未来。
相关文章
- 云工场科技成为海淀3x3超级争霸赛与无锡杯官方算力支持伙伴
- 博大数据荣膺“全球AI生态基石大奖”,夯实融合算力基础设施服务商领先地位
- 日联以纳米级洞见,守护AI算力万亿市场
- 光互联引领算力新基建,三安光电卡位全球产业新周期
- 全球首款RISC-V+AI智通融合服务器CPU,蓝芯算力重磅亮相移动云大会
- 智云洞察 | 从词元调用量1000倍增长的背后,看智能体时代算力价值的跃迁!
- 10万亿+Token:“算力育人”的全新范式/崭新样本
- 象帝先最新消息:携手软通华方,共筑国产算力全生态
- 中国移动研究院段晓东:从“AI Native”到“Token Native”,算力网络迈向发展新阶段
- 中国移动发布全国一体化算力网技术创新体系
- 聚力算力建设 深化政企协同 -- 中兴通讯助力福州数字经济高质量发展
- 国产算力×国产模型,联想开天工作站全面适配 DeepSeek V4!
- 对算力瓶颈发起总攻:新紫光亮出“全家桶”
- 海光信息亮相数字中国峰会 以硬件内生安全构筑AI算力防护体系
- 中科曙光超智融合集群接入全国一体化算力网,AI4S驶入普惠快车道
- 中科曙光超智融合算力集群,正式接入全国一体化算力网!
人工智能企业
更多>>



人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench


