前特斯拉团队杨硕创业首作登顶 SOTA:妙动科技使机器人控制效率提升10倍
2026-04-02 12:05:56AI云资讯2198
教一个人学骑车,你可以给他看一千张骑自行车的照片——但真正让他学会的,是那一脚踩上踏板的瞬间。照片和文字教的是"认知",而骑车需要的是"物理直觉"。
机器人领域也面临同样的难题,过去两年最热门的方案是视觉-语言-动作模型(VLA):让大语言模型"看懂"场景,再接上机器人的手脚,微调一下,机器人是不是就能干活?但问题在于,GPT 等大模型吃的都是静态的图文数据:它知道"这是杯子",却不知道"杯子倒了会怎样"。要补上这些物理知识,就得靠真人戴 VR 头盔手把手地教,每个动作教上百遍,非常吃力。
那有没有一种数据,天然就包含物理动态信息,而且互联网上已经积累了海量规模?
有。视频。
妙动科技的答案:让视频生成模型当机器人的“物理老师”
这正是深圳初创机器人公司妙动科技(Mondo Robotics)新论文 DiT4DiT 的核心思路,一经发布后即获 Agility Robotics AI 负责人等多位硅谷机器人专家关注和转发。据了解,DiT4DiT 也是目前世界模型在人形机器人上首次落地的成果。
DiT4DiT 的名字直接点明了架构:两个 Diffusion Transformer(扩散变换器)串联协作,一个负责想象,一个负责执行。
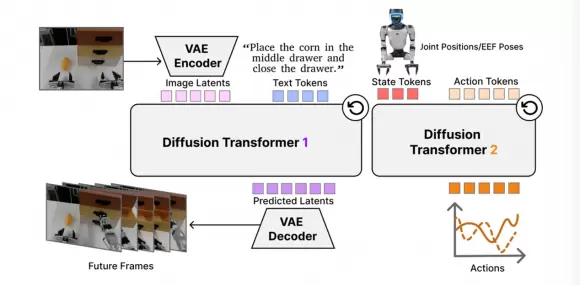
第一个 DiT 是"想象者":接收当前画面和语言指令,在内部预测接下来会发生什么,相当于让机器人先在"大脑"演练一遍任务。这一模块继承了视频生成模型的预训练权重,携带着关于物理世界的丰富隐式知识。
第二个 DiT 是"执行者":读取第一个 DiT 在去噪过程中产生的中间特征,将"想象中的动态信息"翻译成具体的机器人关节指令。
简单讲:一个负责"理解世界会怎么变",一个负责"决定手该怎么动"。视频生成模型花了海量算力学到的物理直觉,被直接注入了机器人的决策系统。
一个反直觉的发现
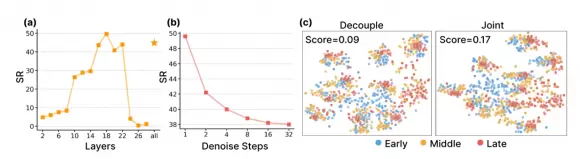
研发团队在消融实验中发现了一个违反常理的结论:从视频模型提取特征时,只需单步去噪效果最好,步数越多、太清晰,性能反而下降。提取层也有讲究,第 18 层(中间偏深层)的特征最优,达到性能峰值。
原因不难理解:对机器人动作决策而言,捕捉运动的趋势和物理规律比还原精确的像素画面更重要。粗略但充满动态信息的中间特征,比最终清晰的预测帧更有"行动力"。
这个发现带来的工程优势非常实际:整个系统在单张 RTX 4090 消费级显卡上即可实现 6Hz 实时推理,仅需单颗 RGB 相机。而同类方案 Cosmos Policy 需要 H100 专业算力卡,推理速度仅 1Hz。部署成本和速度,DiT4DiT 都领先了一个量级。
实验成绩:全面刷新 SOTA
数据是最直接的证明。
在行业权威的 LIBERO 基准上,DiT4DiT 达到 98.6% 平均成功率,超越 π0.5(96.9%)、CogVLA(97.4%)和 OpenVLA-OFT(97.1%),刷新当前 SOTA。而它使用的预训练数据量仅为同类方法的 15%,收敛速度快了 7 倍——用更少的数据、更短的时间,训练出更强的模型。
在更具挑战性的 RoboCasa-GR1 基准(24 项家庭任务)上,DiT4DiT 取得 50.8% 综合成功率,比 NVIDIA GR00T-N1.5(41.8%)高出 9 个百分点。真机实验在宇树科技 G1 人形机器人上进行,共测试 7 项任务——插花、打包、移动勺子、叠杯子、抽屉交互等,DiT4DiT 全面领先。值得一提的是,DiT4DiT 仅使用机器人头部单目相机完成所有任务,而此前业内方案多依赖头部加双手共三个相机,系统复杂度明显更高。
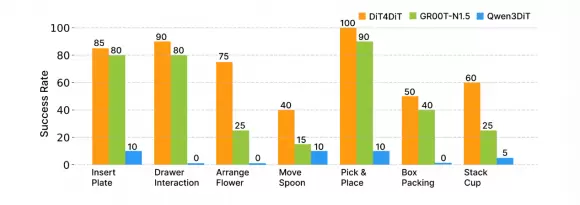
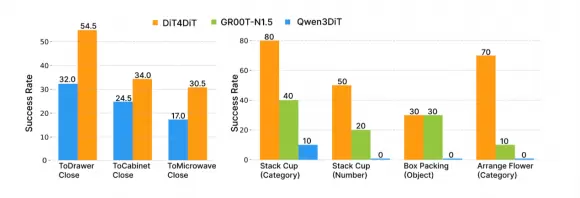
零样本泛化是该方法最突出的能力。换物体材质、换形状、换数量:面对从未见过的测试场景,DiT4DiT 仍保持 40%–70% 的成功率。对比看, Qwen3DiT 在多项泛化测试中直接归零。这一差距说明:视频生成赋予的物理直觉,确实比静态图文对齐更贴近真实世界的复杂性。
团队:前特斯拉 Optimus + 前大疆
妙动科技总部位于深圳,专注具身智能前沿研究与落地。联合创始人兼 CTO 杨硕是 CMU 博士,曾任职于特斯拉 Optimus 人形机器人团队,也是知乎机器人领域知名博主。另一位联合创始人来自大疆,曾负责供应链与 RoboMaster 机器人竞技项目。团队汇聚多名强化学习与具身智能方向的博士研究员,DiT4DiT 正是妙动科技与香港科技大学(广州)梁俊卫教授团队合作完成的研究成果。
论文项目页已公开,代码与模型权重预计后续开源。
相关文章
- 影智XBOT发布通用餐饮服务机器人矩阵与“一脑多形”具身智能体系,率先跑通商业落地闭环
- 海柔闪攀机器人全球合作规模超1万台,持续领跑仓储机器人赛道
- 视比特机器人完成亿元级B++轮融资
- 智以载身,形启新境!2026中国具身智能与人形机器人创新峰会在杭州圆满落幕
- 双产品线双向落地 翼菲科技构建机器人业务可持续增长格局
- 开放共赢筑生态 博匠机器人全球化布局引领智能建造
- 作为科技人形护理机器人全球首发,以具身智能重构护理新范式
- 重磅发布!MUNIK秒尼科参编的两项物流机器人国家标准正式落地
- 安徽硅启智元与美国Seegrid达成数据战略合作,共拓工业自主移动机器人新场景
- 有怡科技闪耀2026杭州国际机器人展会 荣获“智躯·整机标杆奖”
- 有怡科技三大核心优势 重塑通用人形机器人行业标准
- 京东五金城发布618战报 工业机器人及关键模组成交额同比增长超10倍
- 让实体工具对话空间计算,上海智位机器人 seeMote系列为Apple Vision Pro带来空间外设操控方案
- 博银合创亮相 Bosch Connected World 2026,展示工业具身智能机器人全栈解决方案
- 让科技走进日常,启元推动个人机器人迈进大众消费市场
- 越疆将发布下一代陪伴交互AI人形机器人,以自研大模型重新定义家庭具身智能
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


