企业级智能体推荐|Token消耗理论归零,九科信息bit-Agent正在创造“免费数字员工”
2026-06-02 10:18:50AI云资讯1619
如果说当前用户对各类智能体产品还能达成什么共识,那么这个共识大概率只有一个:
贵。
这里的“贵”并不一定意味着模型价格高昂,而是指Agent在实际运行过程中持续产生的Token消耗。当Agent真正进入业务流程,开始承担数据处理、运营执行、财税服务等生产任务时,Token成本会随着任务规模扩大而快速累积。

任务量越大,调用次数越多;调用次数越多,Token成本越高。
对于企业和个人用户而言,Agent不仅要能够完成任务,更要能够以可控的成本持续完成任务。否则,再优秀的能力也很难支撑大规模应用。
但小九想进一步追问:
Agent的成本,真的只能随着任务量增长而不断增长吗?
一、Agent的Token为什么居高不下?
要理解Token消耗的问题,首先需要理解当前主流Agent的运行方式。
目前,大多数Agent采用的是“感知—规划—执行”的工作模式。每当接收到一个任务,系统都会重新感知环境、分析当前状态、理解任务目标、制定执行计划,并根据执行结果持续调整后续动作。
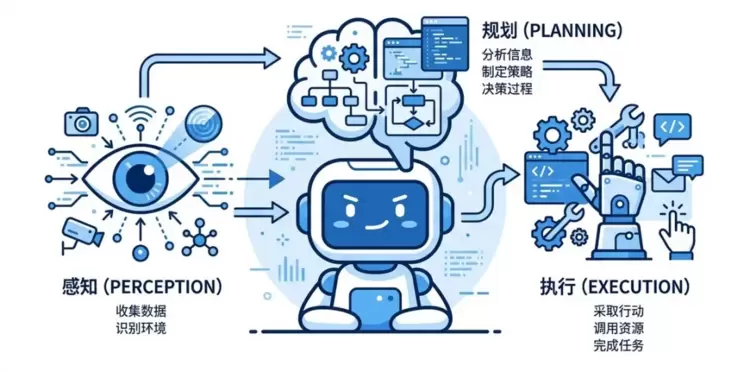
主流Agent工作模式——“感知—规划—执行”
这种架构具有很强的通用性,能够应对复杂、多变的任务场景,因此成为行业主流方案。但与此同时,它也带来了一个天然的问题:Agent会不断重复已经完成过的思考。
即便面对完全相同的任务,即便昨天刚刚执行成功过,Agent今天依然需要重新理解页面、重新分析流程、重新规划步骤,然后才能开始执行。
从结果上看,消耗的是Token;从本质上看,消耗的是重复推理。
对于开放环境中的未知任务而言,这种模式是必要的,因为系统需要依靠实时推理能力应对各种变化。但企业场景往往具有明显不同的特征。大量业务流程具有稳定的规则和重复性。例如财税申报、数据录入、系统巡检、运营管理等工作,执行逻辑相对固定,同类任务会被持续重复执行。
对于这些场景来说,企业真正需要的并不是一个每次都重新思考的Agent,而是一个能够积累经验、复用经验的Agent。
换句话说,出于对成本的考量,我们需要的不只是推理能力,更需要能力沉淀能力。
bit-Agent:从“执行一次消耗一次”到“探索一次、复用多次”
基于这一思考,九科信息在设计bit-Agent时,并没有将优化重点放在简单的上下文压缩或提示词优化上,而是从Agent的能力成长机制入手,提出了“探索+固化”的技术路线。

图源:甲子光年《2026企业级智能体白皮书》
在首次接触某项任务时,bit-Agent会进入探索阶段。
这一阶段与传统Agent类似。系统需要理解环境、分析页面结构、识别关键元素、规划执行路径,并在执行过程中不断验证操作结果。大模型负责完成推理与决策,因此会产生一定的Token消耗。
当探索成功后,系统会将已经验证有效的执行过程进行结构化沉淀,把操作路径、页面特征、业务规则以及工具调用逻辑等信息转化为可复用能力。
这一过程被称为“固化”。
固化后的能力不再依赖实时推理,而是成为系统自身的一部分。当Agent再次遇到相同或相似任务时,可以直接调用已经沉淀完成的能力模块完成执行,而无需重新经历完整的思考和规划过程。
这意味着,Agent不再是简单地完成任务,而是在完成任务的同时不断积累经验。
从成本角度来看,这种机制带来的变化尤为明显。
传统Agent的成本模型可以理解为“执行一次,消耗一次”。任务执行次数越多,Token成本越高,两者基本呈线性增长关系。而bit-Agent的成本模型则变成了“探索一次,复用多次”。
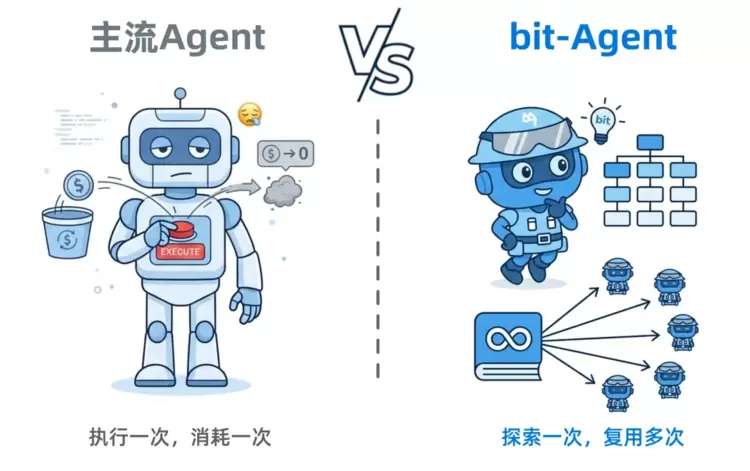
传统Agent的成本模型Vs.bit-Agent的成本模型
系统在探索阶段产生的成本,相当于学习成本;而当能力完成固化后,同类任务执行过程中对模型推理的依赖将大幅降低,部分场景甚至可以完全绕过大模型决策环节。
这意味着,同类任务执行过程中的Token消耗理论上可以降至零。
对于高频业务场景而言,这种差异会随着执行次数的增加不断放大。任务执行规模越大,能力复用带来的成本优势越明显。
从最为现实的角度出发,bit-Agent只需要付出首次探索的token成本,后续复用时消耗的只有廉价的电费,这让企业与个人用户都能够拥有专属的“免费数字员工”。
从长期运营角度来看,这不仅降低了模型调用成本,更改变了Agent的成本结构,使其具备了规模化部署的基础。
三、除了固化机制,bit-Agent还做了哪些优化?
“探索+固化”是bit-Agent降低Token消耗的核心机制,但在探索阶段以及面对全新任务时,系统仍然需要调用模型完成推理。因此,九科信息还针对Agent运行过程中的多个关键环节进行了专项优化。
首先是界面信息裁剪。
在浏览器场景下,网页往往包含大量与任务无关的信息,例如广告区域、装饰元素、重复导航以及复杂的页面结构。如果这些内容全部进入上下文,不仅增加Token消耗,也会影响模型决策效率。
bit-Agent能够对页面信息进行有效裁剪,在保证页面语义完整的前提下,过滤大量无关内容,使模型聚焦于真正与任务相关的信息,从源头降低上下文长度。
其次是动态状态注入机制。
传统Agent为了保证上下文完整性,往往会持续携带大量历史状态信息,导致上下文窗口不断膨胀。随着任务链路变长,Token消耗也会持续增加。
上下文窗口:决定模型理解范围
bit-Agent采用按需注入策略,根据当前任务阶段动态提供必要信息,避免历史状态长期占据上下文空间,在保证决策质量的同时显著降低Token开销。
针对企业场景中广泛存在的浏览器自动化需求,bit-Agent还进行了专门优化。通过对页面结构、元素识别和交互逻辑的深度处理,系统能够减少模型参与频率,让更多操作由执行层直接完成,从而进一步降低推理成本。
此外,在工具调用层面,bit-Agent也进行了大量优化工作。系统将常用工具和标准操作封装为独立能力模块,避免在每次调用时重复向模型传递工具说明和操作定义。同时,工具执行结果能够直接进入执行链路,仅在关键决策节点调用模型参与判断,有效减少了工具调用过程中的Token放大效应。
bit-Agent“能力与工具调用”模块
这些优化措施共同作用,使bit-Agent即使面对全新任务,也能够以更低的成本完成探索过程;而随着能力不断沉淀和固化,系统整体运行成本还将持续下降。
结语
随着Agent的能力边界逐渐扩大,衡量其价值的标准正在发生变化。用户开始关注系统能否在长期运行过程中保持稳定、可靠和可控的成本结构。
从这个角度来看,降低Token消耗的关键并不只是减少模型调用次数,而是减少不必要的重复推理。
当行业还在讨论如何让Agent拥有更强推理能力的时候,bit-Agent正在解决另一个更加现实的问题:如何让Agent在真实办公环境中持续学习、持续积累,并以更低的成本创造长期价值。
如果你也想拥有低成本的智能自动化办公体验,欢迎联系小九,让我们携手共进,共创数智未来!
相关文章
- 2026中国互联网大会丨中国互联网协会与中国信通院发布首批互联网智能体登记可信清单
- 2026中国互联网大会丨智能体互联网论坛在京举办
- 全球首款AI智能体手机有何不同?努比亚总裁倪飞给出官方解读
- OpenAI推出GPT-5.6,并宣布推出AI智能体ChatGPT Work
- 中兴通讯股价走高 旗下努比亚全球首款AI智能体手机将于WAIC 2026首度亮相
- 企业智能体平台推荐丨Claude“隐写术“事件后,AI选型的安全底线在哪?为什么更多企业选择九科信息bit-Agent?
- 阿里云发布AgentTeams与AgentLoop:破解企业智能体规模化落地两大难题
- 微步AI智能体安全治理方案入选《2026 AI安全产业研究报告》
- 迈沐智能完成Pre-A++轮融资,金雨茂物数千万战略投资,加速AI+制造智能体多赛道布局
- 影智XBOT发布通用餐饮服务机器人矩阵与“一脑多形”具身智能体系,率先跑通商业落地闭环
- GSMA Intelligence发布Agentic Core白皮书,定义智能体化核心网演进新范式
- 汇智聚力智启新程!智能体产业主题论坛在京举办
- 企业级智能体推荐丨九科信息bit-Agent让“流程思维”真正落地,低成本转化为智能化生产力
- 中国信通院权威发布:网易四项成果入选国家级智能体创新汇编
- 联想天禧入选中国AI智能体领航者榜单,智能体贯通个人、企业与赛事
- 全球前三!中国电信网络大模型及智能体 斩获GSMA多项国际权威认证
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


