获高通阿里投资后,耐能推出首颗为3D人脸识别定制的AI芯片
2019-05-17 18:26:44AI云资讯1678

区别于大陆AI芯片公司,耐能的风格自成一体,既保留了传统半导体人一贯的严谨保守,也敢于在架构创新上不拘一格。
「在没有确定市场之前我们不敢贸然流片,一定是大公司合作的形式」,耐能(Kneron)创始人兼CEO刘峻诚坦言。在他看来,一家AI芯片初创公司的经营之道在于「夹缝中求生存」——资源有限,每一分钱都要用得谨慎,不能做一颗不赚钱的芯片,做就一定要做能够赚钱的芯片。
这是一家由前高通华人工程师组建的芯片团队,成立于2015年,聚焦在终端 AI 芯片解决方案,主攻智能手机、智能安防、智能物联网等领域。公司在2017年、2018年相继完成两轮融资,投资方包含阿里巴巴创业者基金、高通、李嘉诚旗下的维港投资等硬核机构。

成立三年,推出两代六款IP,基于和高通、知名家电厂商的合作经验,两代IP的开发实战,耐能终于底气十足地踏出了关键一步,基于第二代IP标准版本推出首颗自家品牌的系统级AI芯片,同时也是市面上首颗专为3D人脸识别进行优化的终端芯片。
5月16日机器之心消息,耐能发布AI芯片KL520,专为智能物联网应用所设计,兼顾语音和图像不同数据类型处理,支持2D、3D图像识别,适用于结构光、ToF、双目视觉等3D传感技术并计算不同神经网络模型,可应用于智能门锁\/门禁、扫地机器人(15.380,-0.79,-4.89%)等智能家居场景,无人机、智能玩具、机器人等智能硬件产品线。
值得一提的是,该颗芯片目前已经量产,并且已经与中国大陆和台湾两地的数家客户达成合作。在深圳媒体沟通会现场,耐能宣布了与大唐半导体、奥比中光、蓦然认知等厂商的合作计划。
1独立优势决定市场覆盖面
作为一颗SoC级芯片,KL520采用常规的ARM核+自研IP架构,双核ARM M4 CPU+KDP 520NPU,其中KDP 520NPU为耐能自研IP,两核的ARM M4用于系统控制和协处理。采用SDRAM 32MB\/64MB 系统级封装,LPDDR2内存技术,可接外部64MB闪存。

KL520 算力峰值为0.39TOPS (300MHz) 。相比主流AI芯片的理论算力峰值 1-2TOPS,KL520 看起来并不占优势。不过由于核心利用率(MAC利用率)达到竞品的2-3倍,使其实际效果达到与1TOPS的相近水平,同时保持极低的功耗和成本。
KL520 典型功耗为0.5W,提供MIPI、DVP等视频\/音频接口,外部USB2.0、SPI等接口。
值得注意的是,KL520选用了十分成熟的40nm制程工艺,通过更低制造成本创造有竞争力的价格优势。刘峻诚表示,正是因为芯片架构和设计足够好,所以才有这样的底气。
整体而言,KL520 强调轻量化、低功耗、低成本。相比此前AI芯片明星公司的华丽参数,KL520甚至显得有些过于朴实。
但在运算架构和算法压缩上,耐能的核心技术优势却让人印象深刻。据CEO刘峻诚分析,KL520主要集成了耐能IP的三项「独门秘籍」:
1)可重组式运算架构设计:透过重构式架构,让神经网络架构中主要的卷积运算与池化运算可平行进行,以提升整体运算效率。在新的卷积层运算中,可同时支持8bits与16bits的任意切换的定点运算,让运算更有弹性。
所谓「可重组式架构」。一般情况下,不同的计算应用对应不同的神经网络,比如图像处理以CNN为主,比如ResNet、GoogleNet、VggNet;语音处理则以RNN、LSTM为主。但是耐能团队通过对同一颗芯片进行架构重组,使其同时符合语音和图像处理需求,也可以同时兼顾2D、3D图像的AI处理要求。具体到落地场景和实用性层面,则意味着将丰富芯片的使用范围,增强其通用性。
2)深度压缩技术:支持模型转移学习和压缩,支持蒸馏、修剪和量化等压缩技术。不仅能执行模型压缩,还能对运行中的资料和参数进行压缩,减少存储使用。
模型大小可压缩至50分之一以下,准确度的影响率小于1%,提供GUI NPU\/CPU等工具链。
3)动态储存资源配置:让共享内存和运作内存之间可以进行更有效的资源配置,提升储存资源利用率的同时却不影响运算效能。
刘峻诚解释,基于动态定点存储技术,I\/O在做每层计算时都会动态调整比特数,8bit现在已经成为主流,但到一些具体的算法可能只需要4bit、6 bit就够了,有些地方需要要10 bit,所以需要动态调整,提高其算力利用率。
此外,刘峻诚认为,可拓展性和兼容性是耐能芯片平台的最显著优势,平台能够兼容主流框架和第三方算法,包括主流深度学习框架API ONNX、TensorFlow、Keras、Caffe,支持更广泛的CNN轻量化模型,包括 Vgg16、ResNet、GoogleNet、YOLO、Tiny YOLO、Lenet、MobileNet、DenseNet等,而且针对不同CNN模型分别进行优化,在不同神经网络模型下,可达到70%~90%的运算效能。
「我们应该市面上目前资源最多的AI芯片公司之一。我们还做了一个编译器,可以支持这些框架的开发」,刘峻诚说道。
为了更好地完善软件平台,今年刘峻诚特意邀来原金蝶中间件有限公司首席架构师袁红岗加入团队,这位技术大牛曾在2004年被公推为「影响中国软件(50.840,1.34,2.71%)开发的20人」之一。
作为耐能最为核心的架构技术优势,目前「可重组式架构」技术已经入选新竹国立清华大学等高校课程,刘峻诚个人也作为台湾成功大学的客座教授进行讲解。刘峻诚表示,「我们的芯片在实验室课上供学生编程搭建方案,两三人一组很快就能上手,这增加了我们对其易用性的信心」。
不同于大多数AI芯片在强调芯片研发和快速迭代的能力,出身于传统半导体行业的耐能更强调芯片的通用性,尤其在分散的物联网市场。
「我们发现IoT、机器人、无人机,都是量小但杂的市场,所以我们的打法就是用一颗通用化的芯片来支持更多应用。同时强调软件平台开放包容,让体量较小的开发者自己做开发以支持自己的量。」刘峻诚谈道。「我们不可能做一颗芯片卖无人机,再做一颗芯片卖给机器人,那公司一定会垮掉。」

刘峻诚表示,团队都是芯片领域的老将,打从一开始就深知AI芯片的能力和局限性,当市场不是很清楚的时候,我们会先卖IP,有一定量才决定流片,再判断什么样的制程合适。
「我们是高通出来,对半导体产业非常熟悉,不能做一颗不赚钱的芯片,至少我们公司不会这样干,我们做的这颗就是一定要赚钱,所以才会打磨这么久,才会强调其通用性,可以做3D人脸支付、做语音的家电控制、可以做扫地机器人,做门禁打卡机。」
2理论值不够惊艳,但实际利用率靠谱
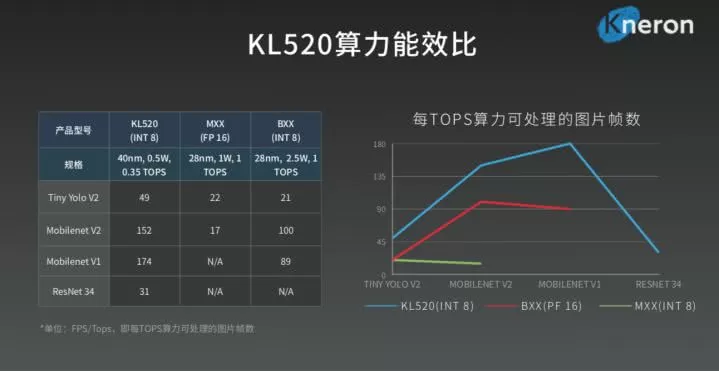
在算力能耗比方面,耐能二代KL520对比市面上较为经典的架构,能够提升3-4倍。
MAC利用率是刘峻诚引以为豪的性能优势之一,他表示,我们找到过市面上所有能买到的AI芯片进行对比,目前还没有能达到25%以上的,「我们应该是世界最好的」。

所谓MAC,既乘积累加运算算子,目前大部分AI芯片的核心都是由MAC组成。理论上,MAC数越多,AI芯片算力会越大。但实际上还有MAC使用率的影响。如果MAC堆积很多,但如果使用率不高,也无用。一颗AI芯片的核心性能指标之一就是MAC的利用率。
为什么塞进去大量计算单元后可能利用率不高?
刘峻诚表示,MAC利用率跟I\/O(进出速度)、存储数有关,需要很强的芯片设计经验。比如,一台跑车马力非常强,但轮胎不好,或者转轴算得不好,协调性不够,导致实际上跑起来速度并不快。可以说,MAC利用率更大层面考验的是团队对于芯片底层架构的设计能力。
正是基于此,刘峻诚透露,在谈客户时,因为耐能的价格能做到大厂的1\/4至1\/5,并且性能更优,所以具备十分强劲的竞争力。
刘峻诚认为,AI芯片不能只看算力。因为算力的提升可以简单通过MAC数的堆积、制程工艺的提升实现;但与之相对应的代价是芯片功耗和面积的提升,成本的增加。
成功的终端AI芯片应具备足够的算力、最有竞争力的成本、最高的兼容性、最低的功耗的基本条件。
3落地开枝散叶
目前,耐能已经展开合作的客户有高通、格力、搜狗、奥比中光等。此前,耐能的第二代IP,KDP系列已经落地国内知名家电品牌的空调产线中。在技术方案上,与Synopsys、钰创科技、Himax(奇景光电)展开合作。
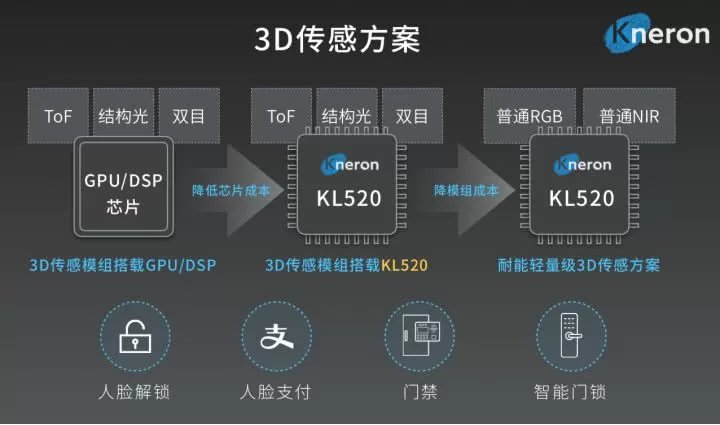
为应对3D摄像头模组贵、芯片成本高、硬件功耗高等3D传感行业痛点,耐能通过和奇景光电、高通合作推出轻量级3D传感方案,将传统的3D传感模组ToF\/结构光\/双目+GPU\/DSP芯片方案简化为,普通RGB摄像头+普通NIR(近红外光)+KL520,在芯片和模组两个层面降低成本。
在智能门锁市场,耐能与大唐半导体合作,将3D方案落地在轻量级AI芯片上,误识率仅为数十万分之一。同时,对室内外的光线环境均能很好适应,有效的防止多种材质的相片、显示屏甚至人脸模型的攻击。
在产品线路图规划上,耐能在2018年已经实现KDP300、KDP500两代协处理器IP的研发和落地,目前已经落定到国际大厂的产品线中。
2019年,低功耗 IP版本KDP320已经和国内前三大家电巨头之一达成合作,近期将由该大厂发布。KL520目前已经量产,KL720将在第四季度发布。
更长远地,2020年,耐能将相继推出KL330、KL530(28nm)、KL730(16nm)等三代IP,其中KL530将采用28nm制程、KL730的制程则为16nm。
相关文章
- 高通技术专家谈Wi-Fi 8:4×4射频配置为何是移动连接的关键一跃
- 高通发布骁龙Reality Elite旗舰XR芯片,性能更强的智能眼镜即将问世
- 爱疆科技携星汉AI 2.0重磅登场,以高通量检测赋能钙钛矿产业化
- 共促6G创新发展,高通与业界探索AI等技术的应用
- 高通×极视角端侧AI开发者技术日暨骁龙大赛颁奖典礼圆满落幕
- 高能数造全自动硫化物高通量制粉线:直击行业痛点,重构硫化物制备全链路新范式
- 高通点赞广汽埃安N60智驾大赛获亚军,文远知行WRD 3.0亮相高通峰会
- 东软智行与高通技术公司共拓中央计算时代汽车智能化新格局
- 东软智行与高通技术公司签署战略合作谅解备忘录
- 锚定AI原生新赛道 移远携全系车载方案闪耀2026高通汽车峰会
- 高通将推出搭载新款骁龙C处理器的Windows笔记本电脑,售价300美元
- 智能体时代的AI发展新方向,高通COMPUTEX 2026给出“计算连续体”答案
- 不断推动技术进步,高通徐晧:6G试验频率可在覆盖和带宽之间实现更好的平衡
- 如何推动6G快速发展?高通钱堃:技术标准化有利于实现产业化的广泛应用
- 苹果提速研发AI眼镜,高通/微美全息构建多维触达矩阵抢占穿戴消费风潮!
- 高通徐晧:6GHz频段能够在覆盖能力与带宽资源之间实现更好平衡
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


