用脑电图也能做语音识别?新研究造福语音障碍者
2019/06/26 11:12AI云资讯1481

工业界版权检测系统易受攻击?
版权检测系统在网络界面中起着至关重要的作用,尤其是在数字资产不断增长的当下,它们的安全性显得极其重要。然而,目前人们在提高它们的安全性和鲁棒性方面并没有做太多工作。
为了应对这一挑战,研究人员最近对版权检测系统的脆弱性进行了研究,并展示了这些系统如何容易受到敌对攻击。为了展现这种无防御的天性,他们利用原始神经网络建立了一种简单的歌曲识别方法,并利用常用的梯度法对其进行攻击。
令人震惊的是,混音攻击竟然能够成功地欺骗包括AudioTag和YouTube在内的业界最佳系统。当AudioTag版权检测器未能检测到为其构建的对抗性示例时,他们能够使用youtube的内容ID系统进行规避并未被检测到。
本文提高了对版权检测系统面临威胁的认识,并强调了提高此类系统安全的重要性。随着人工智能社区对鲁棒的人工智能和机器学习系统的积极研究和深入设计,考虑可能对这些系统构成潜在危险的威胁是至关重要的。对于初学者,可以使用对抗性训练和其他可用的防御手段来帮助实现这一目标。
用脑电图做语音识别——语言障碍人士的福音
研究人员首次仅使用脑电图特征将连续语音识别应用到汉语和多语言词汇。他们展示了基于深度学习的自动语音识别(ASR),使用脑电图信号对有限的英语词汇(4个单词到5个元音)进行识别。他们还展示了对更多的英语词汇使用连接主义时间分类(CTC)模型和attention模型,来完成基于脑电图的连续噪声语音识别,。
在他们的研究中,他们观察到,与CTC模型相比,当使用较小的脑电图特征数据集训练时,attention模型的错误率更高。因此,他们在研究中只使用了CTC模型。他们还拓展了他们的工作,为一个由更多中文词汇和中英词汇等多语言词汇的列表应用了CTC模型。他们在工作中使用了非常嘈杂的语音数据,并且在使用脑电图特征的较小语料库中显示出较低的字符错误率(CER)。
本工作证明了利用脑电图特征进行鲁棒多语言语音识别的可能性,可以帮助有说话障碍的人实现语音激活技术。
它可以帮助自动语音识别(ASR)系统,例如飞行器直接语音输入,在背景噪声条件下使用简单的语音指令克服性能损失等,从而使他们能够在非常嘈杂的环境中如机场,商场等环境下执行高精度语音识别。
另外,这一研究提出的语音脑电图数据库还可以扩展,以促进该领域的研究。
面向更有识别力的深层神经网络嵌入,用于识别说话人
受深度神经网络在语音识别中的成功应用启发,研究人员对DNN在说话人建模中的应用进行了研究,发现与传统方法相比,判别性深度神经网络(DNN)具有更好的说话人嵌入性能。
目前大多数的深度说话人嵌入框架都采用softmax损失函数作为优化准则,这与较先进的基于边缘的分类损失函数相比存在一定的不足。研究人员使用了三种不同的基于边际损失的方法来解决这一挑战,这三种方法不仅将不同的类别分开,而且要求类别之间有固定的边际。
结果表明,通过训练一个DNN语音分类器并从中提取嵌入信息,可以直接建立一个高性能的说话人识别系统。
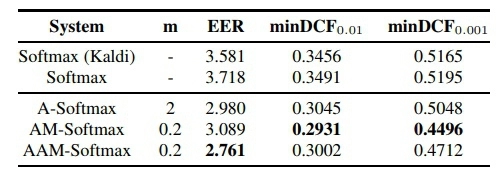
在使用两个公共文本独立的任务(包括VoxCeleb1和Speaker in The Wild,即SITW)来评估后,这一方法展现了先进的性能:与使用softmax交叉熵损失的基线相比,新方法降低了两个任务25-30%的相等误差率(EER),取得了在VoxCeleb1测试集熵2.238%的EER和SITW核心测试集上2.761%的EER。
从深度预训练语言模型,转向端到端语音合成的转移学习
这一研究利用BERT辅助Tacotron-2的训练。Tacotron-2是一种由编码器和基于注意力的解码器组成的最先进的文本语音转换(TTS)方法。本研究的目的是利用深度预训练的学习管理系统所包含的丰富的文本知识来辅助TTS训练。
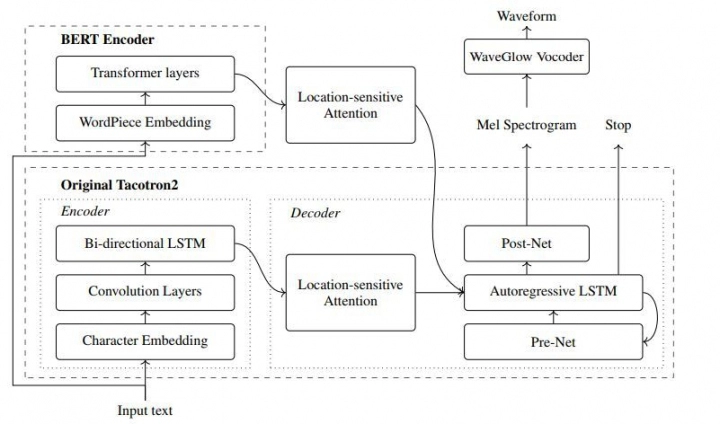
结合BERT将输入文本序列转换成文本表示,这些文本表示与Tacotron-2编码器提取的文本表示并行,并将两者提供给Tacotron-2的解码器。BERT是一个基于转换器的模型,以无监督的方式训练大量文本。从大量未标记的文本数据中学习到的BERT表示法显示,它包含了非常丰富的输入文本的语义和句法信息,并且有可能被TTS系统利用,从而弥补高质量数据的不足。
从研究结果来看,将BERT加入到Tacotron-2框架中并不能提高合成音频的质量。但该方法在训练过程中收敛速度较快等其他方面的优势也能对tacotron-2模型进行改进。
该模型非常善于判断何时停止解码,因此合成音频的杂音量较小,从而消除了对组件设计领域广泛专业知识的需求。
开源转换器实现最优翻译结果
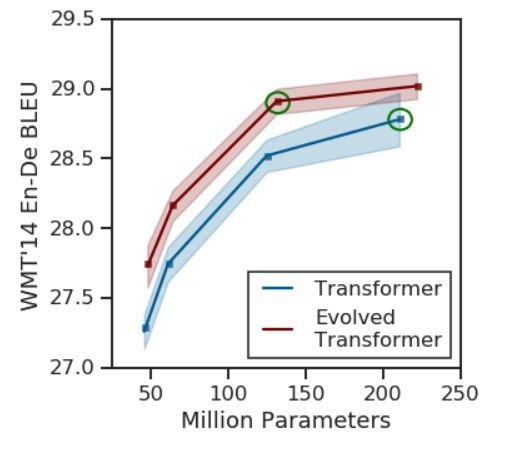
谷歌的研究人员进行了一项大规模的翻译任务,并发现了一个进化转换器(ET:Evolved Transformer)。传统的转换器依赖于自身的注意力,而这一转换器是一个混合体,利用了自身的注意力和广泛卷积的优势。
与大多数序列到序列的(seq2seq)神经网络结构一样,该模型有一个编码器,将输入序列编码为嵌入,以及一个解码器,使用这些嵌入构造输出序列。对于翻译任务,输入序列是要翻译的句子,输出序列是翻译结果。
新的转换器实现了显著的性能,并证明了参数的有效使用。它在WMT 14 En-De上达到了BLEU分数 29.8和SacreBLEU分数29.2的测试结果。
相关文章
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


