CVPR 2020 | 京东AI研究院对视觉与语言的思考:从自洽、交互到共生
2020-04-14 08:53:40AI云资讯1190
纵观视觉与语言在这六年间的飞速发展史,它就仿佛是两种不同文化(计算机视觉与自然语言处理)的碰撞与交融。这里每一种文化最初的进化都是自洽的,即独立地演化形成一套完备的视觉理解或语言建模体系;演化至今,我们当前所迎来的则是两种文化间的交互,自此视觉理解和语言建模不再是简单串联的两个模块,而是通过互相的信息传递成为共同促进的一个整体;对于视觉与语言的未来,则一定是聚焦于两者更为本质和紧密的共生,它所渴望的,将是挣脱开数据标注的桎梏,在海量的弱监督甚至于无监督数据上找寻两者间最为本质的联系,并以之为起源,如「道生一,一生二,二生三,三生万物」一般,赋予模型在各种视觉与语言任务上的生命力。

This monkey on the back of horse
Disney made the best cake of all time using projection
Tiny squid flopping around on the rocky bottom of fish tank
注:为了更好地便于读者理解和推动视觉语言领域的发展,将这几年我们关于视觉与语言的代表性工作(LSTM-A [1],GCN-LSTM [2],HIP [3],X-LAN [4])进行开源,这些对应的源码都在 GitHub 上陆续公开(https://github.com/JDAI-CV/image-captioning),敬请关注!
缘起视觉与语言,即视觉内容理解和自然语言表达,原本分属于计算机视觉(CV)和自然语言处理(NLP)两个不同的研究领域。然而在 2014 年,图像描述生成(Image Captioning)猛然打破了两者间的壁垒,凭借着机器翻译中经典的 encoder-decoder 模型一下贯通了从视觉内容到语言表达的转换,为 CV 和 NLP 领域的后继者同时打开了一个不同模态交叉融合的新世界。
与机器翻译中不同自然语言间的转化相仿,图像描述生成任务可以提炼为从一种视觉语言(图像特征表达)到自然语言(描述语句)的转换。现今主流的图像描述生成算法的原型都可概括为两个模块:视觉编码器(Visual Encoder)和语言解码器(Language Decoder)。前者负责对视觉内容的理解,将视觉语言编码为富含语义信息的特征表达,后者则依据编码后的特征表达来解码出相应的语言描述。
自洽各自文化的起点都是从蹒跚学步的孩童开始,渐渐形成一个完备自洽的体系。对于视觉和语言也是如此。身处深度学习的浪潮之中,视觉和语言各自也都在不断地往前进步,譬如由底层纹理到高层语义的视觉内容理解(Visual Understanding),亦或是由单个词出发演化至整个词序列的语言建模(Language Modeling)。
在这一阶段的视觉与语言模型本质上是视觉编码器和语言解码器的简单串联。以图像描述生成任务举例,该阶段的研究重心往往是如何从图像视觉内容中解析出更多的高层语义信息,并将这些语义信息融入到视觉编码的过程中,以增强编码器输出的视觉特征表达。这一研究思路也正是我们在前三年一系列工作的脉络,即属性(Attributes)-> 关系(Relation)-> 结构(Hierarchy)。
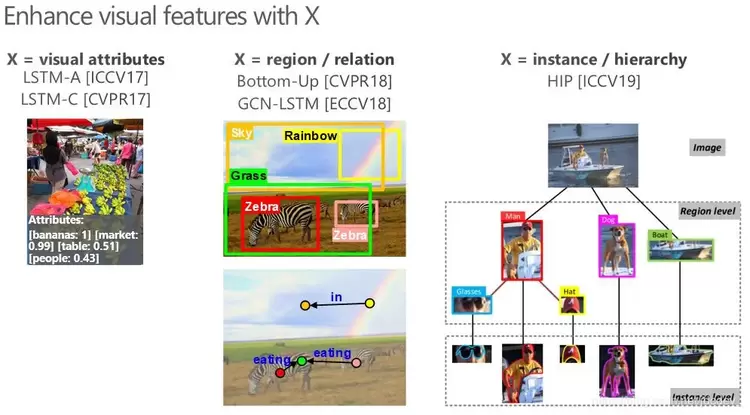
如上图,首先是 2017 年我们尝试在视觉内容编码的过程中引入高层的语义属性,它不仅包含图像中显著的物体,也具备背景中的场景信息。在获取高层语义属性后,我们不仅可以在特征层面将语义属性特征融合至编码特征中(LSTM-A [1]),也可以将识别的语义属性词直接「拷贝」到解码出的描述中(LSTM-C [5])。接着在 2018 年,受到 Bottom-Up [6] 中通过物体检测器获取高性能的物体区域特征的启发,我们进一步去挖掘物体和物体之间的关系(GCN-LSTM [2]),构建出物体间语义和空间的关系图,从而促进对图像的理解。尽管物体间关系图有效地引入了物体间关系的语义信息,但依然无法充分表达整个图像所包含的丰富语义。故在 2019 年,我们提出了一种多层次的树形语义结构(HIP [3]),它囊括了从语义分割后的物体实例到检测后的物体区域再到整个图像的不同层级之间的语义信息。通过这样一种树形结构可以实现对物体不同层次间语义关联性的编码,以解码出更为精准的描述文本。
视觉与语言发展的第一阶段自洽可以看做是每个文化独立的发展史,所衍生的算法模型也大多是视觉编码器和语言解码器的简单串联。然而没有一种文化可以在发展中独善其身,互相调和与交互将是必然。因此现今的视觉与语言渐渐步入交互的阶段,目的是促进视觉编码器和语言解码器间的信息交互。
注意力机制(Attention Mechanism)是不同模态间最典型的信息交互手段。它可以通过每一时刻解码器的隐状态来推断当前编码器中需要关注的图像区域,以此帮助编码器更好地理解图像内容。如下图,早期的注意力机制 soft-attention [7] 会依据条件特征 Q(解码器当前的隐状态)与每一个图像局部区域特征 K 的线性融合来获取该区域对应的注意力权重,再将每一个注意力权重作用于局部区域特征 V 实现图像特征的聚合编码。在这两年也涌现了多种升级版本的注意力机制,比如自顶向下的 top-down attention(Bottom-Up [6])、同时捕捉多种注意力的 multi-head attention(Transformer [8])和利用门控进一步过滤注意力的 attention on attention(AoANet [9])。
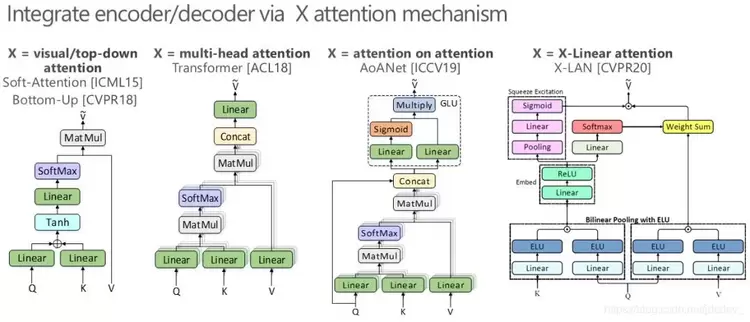
当我们回顾传统的注意力机制时,可以发现它往往利用线性融合来进行跨模态的特征交互学习,所以其本质只挖掘了不同模态间一阶的特征交互,大大限制了注意力机制在视觉与语言这一复杂的跨模态内容推理任务中的作用。针对这个问题,我们在最新的 CVPR 2020 工作 X-LAN [4] 中打造了一个能实现高阶特征交互的注意力机制 X-Linear attention。它可以利用双线性融合技术去挖掘不同模态间二阶乃至更高阶的特征交互信息,以增强跨模态的内容理解。
同时,该 X-Linear attention 可以作为一个灵活的插件接入到目前流行的各种图像描述生成模型中,极大地提升编码器和解码器在模态内和跨模态间的特征交互能力。我们也在最为权威的 COCO 在线评测系统上对所设计的图像描述生成系统进行测试,在多个指标上均达到世界第一的水平(如下图)。

尽管视觉内容的理解可以随着各种高性能网络的设计和语义的深入挖掘不断升级,视觉和语言间交互的方式也已经从传统的 soft-attention 演化到捕捉高阶信息交互的 X-Linear attention,但视觉与语言的技术发展依然逃脱不了深度学习对于训练数据的贪婪。COCO12 万+的图像,约 60 万的人工标注语句,天然制约了图像描述生成技术进一步的发展。无论是对于更多物体的理解还是对于更广泛语言的表达,亦或是更精细更本质的视觉-语言匹配,都需要更细粒度、更大规模的视觉与语言标注数据来支撑。那么如何打破这一视觉语言数据的壁垒?如何突破当前算法的瓶颈?
当人们对某种文化进行反思甚至于迷茫的时候,就意味着一个新的起点将应运而生。因此在当下,视觉与语言也需要迎来一个新的阶段,其目的是在更广大的数据上挖掘出两者间最为本质的共生特质,从而促进不同模态间更为自由的转换。具体而言就是我们需要在海量的弱监督甚至于无监督视觉语言数据上去习得两者间最为本质的联系,然后再赋予模型在各种视觉与语言任务上的生命力。
目前刚刚兴起的视觉语言预训练(Vision-language pre-training)或许可以成为破局的关键。借助于海量网页自动抓取的视觉语言数据,如 Conceptual Captions 和 Auto-captions on GIF,我们可以预训练一个通用的编码器-解码器模型。正是因为在海量数据上所学会的视觉语言共生特质,该预训练模型可以全方位地赋能各种视觉与语言的下游任务,打破每一个下游任务中视觉与语言训练数据的限制,实现了「大一统」的视觉与图像间跨模态理解与转换。目前,京东 AI 研究院的这些技术已在京东应用落地。例如商品图像搜索和图像审核等场景,同时也正尝试将视觉与语言技术融入任务驱动型多模态增强对话中,旨在提升人机交互效率和用户体验。
结语好奇心是个人或者组织创造力的源泉,在权威图像描述生成评测集 COCO 上的成绩彰显了京东 AI 研究院在视觉与语言领域的世界领先水平。京东智联云将一面以智能供应链、「新基建」等为抓手,帮助政府、企业、个人进行数字化、网络化、智能化转型,成为了与零售、物流、数字科技组成了京东四大核心业务版图,是京东对外技术与服务输出的核心通道。一面以「ABCDE」技术战略为基础,保持前沿的技术技术研究和好奇心,即「以人工智能(AI)为大脑、大数据(Big Data)为氧气、云(Cloud)为躯干、物联网(Device)为感知神经,以不断探索(Exploration)为好奇心」。
相关文章
- 京东汽车与壳牌合作再升级 双方将携手发布壳牌喜力光影系列新品
- BOE(京东方)荣获OPPO公司“卓越质量奖” 以卓越品质共筑高质量合作新标杆
- 京东与影智XBOT达成深度战略合作,共推餐饮机器人规模化普及
- 京东携手AMD打造电竞嘉年华 以锐龙9000HX系列处理器升级全民千帧电竞体验
- 京东携手CIHE中国国际耳机展组委会 以三大共建深化音频消费市场
- BOE(京东方)前沿电竞技术矩阵亮相“核聚变嘉年华” 携手合作伙伴共筑原生电竞生态新格局
- 中国企业全球化样本:联想集团上升至2026 Gartner全球供应链榜全球第7,京东同榜
- 只改一处,为什么也要“大满配”?京东家装局改焕新产品深读
- 运动相机同比增长6倍、AI眼镜增长150% 京东618政企3C福利采购成新刚需
- 53.9%市场份额登顶!京东家电稳居2026年618线上第一
- 京东五金城发布618战报 工业机器人及关键模组成交额同比增长超10倍
- 联想AI平板斩获京东天猫双平台618双冠,原生天禧AI如何重塑平板灵魂?
- 蓄力618大促!京东3C数码×可灵AI以内容赛事激活AI装备大众消费市场
- BOE(京东方)中国首条第8.6代AMOLED生产线量产 开启全球高端显示新篇章
- 京东集团政企全景服务亮相廊洽会,以超级供应链助力京津冀一体化
- TCL华星赋能客户增长,携手联想打造京东“好屏”营销
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布


