AI如何更懂医?看腾讯天衍实验室智能医疗诊断技术创新
2022-01-05 18:18:58AI云资讯1093
近年来,在互联网技术和政策、疫情等大环境的推动下,在线问诊需求正高速增长,自然语言处理(NLP)技术在该领域的研究成果和应用落地也越来越多。虽然,智能问诊已经能够实现预诊断,但很多时候系统给出的诊断结果与现实情况大相径庭。举例来说,当我们能准确地给出“体温38.5度、有点发热、四肢无力”等症状时,系统会比较容易根据提供的信息进行询问,给出如感冒、病毒感染等相对精准基础诊断;但如果给出诸如“疲劳”,甚至“累”“没劲”“胸痛”等含糊不清的主诉,智能诊断系统可能就无能为力了。
这是因为,目前计算机在文本理解的精度和深度上和人类仍然有很大的差距,特别是在医学领域,不仅要求计算机学会庞大的专业术语,形成知识图谱;更要能读懂没有专业知识的患者对于症状的模糊主诉,并将其与专业术语做关联。
在此过程中,研究人员除了要给算法“投喂”庞大的专业语料和日常知识,提升算法能力,加强AI对真实世界的理解,还需要用更好的策略,选择合适的模型,优化医疗NLP领域目前面临的问题,而这也是第二十届中国计算语言学大会(下称CCL2021)智能医疗对话诊疗评测——“智能化医疗诊断赛道”要解决的主要难点。
在此赛道中,腾讯天衍实验室团队提交的方案凭借较高的疾病预测准确率和症状召回率,成功获得该赛道第一名,下面我们来看看这套方案是如何进行算法思考和模型选择的。

任务难点:让算法迅速读懂“患者”
“智能化医疗诊断”赛道的任务是:需要选手开发一个模拟实际问诊过程的可交互程序,用程序与拥有超过2000组医患对话样本的病人模拟器“过招”:首先,要与主办方提供的baseline模型交手,判断出“患者”的初始症状;然后,还要根据这些信息,输出能够进一步获取有效信息的问题,对“患者” 进行接下来的症状询问;最终,在不超过11次的交互过程中,识别出“患者”的疾病和症状。比赛结果也是以诊断准确率和症状召回率来确定。
其中的难点是,2000组的对话样本,每个都包含着大量数据信息:疾病类别、病人自诉文本、直接信息(病人自诉中明确提及的实体信息、症状),甚至隐藏信息(需要结合整段医患对话得到实体及标签,判断患者是否已经有该症状)。并且,与现实世界病人一样,机器“患者”不会一次性把症状表述清楚,比如出现一种症状多种描述等主诉表达。
选手开发的算法和对应算法选择的模型,不仅要能“读懂”被“模糊描述”的症状,并迅速将症状分类;还要根据当前询问到的病人信息,准确判断出“患者”还可能具备什么症状,以便在有限的问诊交互环节中,增加“患者”有效信息输出,从而最大可能提升疾病诊断准确率以及症状召回率。
因此,该任务不仅考验算法能力,更同时考验算法和模型的搭配策略,以提升程序问诊的准确性和效率。
方案对策:更高效的算法+更合适的模型 提升推理速度
为了让AI更加理解“患者”信息,腾讯天衍实验室利用搜索、问答、预训练、分类等多项NLP、机器学习技术,进行程序开发,整体方案分为症状问询、疾病预测两大版块,每个版块都采用相同模型预测方案,同时,每个版块细分为三个部分:基于检索查询历史病例、基于自然语言的症状/疾病预测、基于症状的症状/疾病预测(如图所示)。这三个部分在同一个交互周期内会同时运行,并通过加权算法进行“校准”,来得到需要继续问询的症状或者输出诊断的疾病。
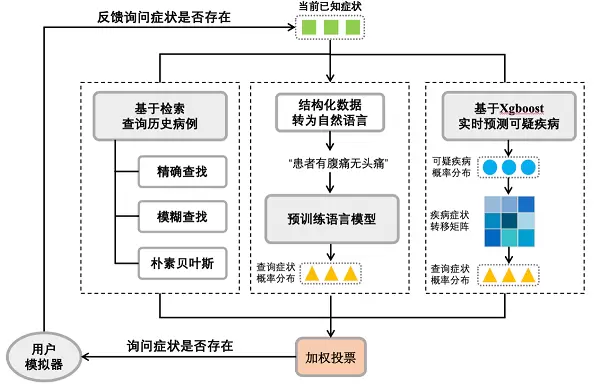
症状问询预测框架图
基于检索查询历史病例部分,利用了精准搜索、模糊搜索,以及贝叶斯推理等技术,用来查找算法数据库中的相似病例,这样做的好处是,不仅能将主诉症状的模糊表述和精准表述相结合,以拓宽对于主诉症状和疾病的检索范围,还能更高效地对症状进行预测。
基于自然语言的疾病预测,是将症状列表转化为自然语言后,利用预训练语言模型预测查询症状概率分布。值得注意的是,此部分选手们采用的模型是天衍实验室自有的大规模医疗预训练语言模型MedBERT,它是基于大规模的医疗在线文本由Robert继续训练得到的,不仅能更好适配医疗领域内的语言学习,还在多项医疗标准数据集上取得了SOTA。相比通用预训练模型来说,MedBERT更能胜任医疗相关的任务执行。
在症状/疾病的预测部分,方案采用了在多项赛事中被验证、分类效果表现优异的分类器——xgboost模型,其优势是使学习出来的模型更加简单,防止过拟合,因此,进一步提升了算法运行效率。

疾病预测框架图
多策略融合召回预测的方式,不仅将检索、自然语言疾病预测、症状疾病预测三种模型优势进行互补,实现了更高的准确率和症状召回率,同时,在症状召回上,还能鼓励更多轮的症状问询,并做良好的超参数配置调优,从而获得更高的症状召回率。正因如此,在最终评测中,天衍实验室在疾病预测准确率和症状召回率上,均获得了总分第一的成绩,甚至,在症状召回率上,还超出其他团队方案10%以上。
这一成果的获得,不仅表明天衍实验室在算法能力和模型具备相对优势,同时,这也是天衍实验室在医疗健康领域AI算法研究和应用落地深耕多年的实力体现。
腾讯天衍实验室一直专注于医疗健康领域NLP研究,其成果已经在腾讯互联网医院中的导辅诊、合理用药、健康助手等业务版块成功落地。同时,天衍实验室还期望在行业层面推动整个NLP的创新研究:如,在深度学习顶会ICLR2021上举办MLPCP挑战赛(医疗对话生成与自动诊断国际挑战赛),以推动医疗咨询对话系统和预测患者可能的疾病类型等方面的创新突破;携手CCKS2021(全国知识图谱与语义计算大会)和中山大学举办蕴含实体的中文医疗对话生成评测,以助力自然语言基础、语言理解、信息抽取、知识图谱构建等领域的研究创新和算法能力提升……未来,天衍实验室仍将持续扎根医疗健康领域,持续探索和推动NLP领域学术科研与应用方向更多价值落地。
相关文章
- 联想天禧AI与腾讯Skill Hub达成战略合作,天禧Claw正式接入一站式AI技能平台
- AI智能体从概念走向落地 赞同科技CTO蒲云出任腾讯云AI智能体嘉年华(华东赛区)专家评委
- 领驭科技×腾讯云联合亮相2026深圳国际眼镜业博览会
- 腾讯云发布边缘Web与AI Agent托管平台 EdgeOne Makers:一键开发部署,分钟级全球上线
- 中国企业创新盘点——同时入选《财富》中国科技50强的联想集团与华为、腾讯、阿里
- 腾讯云TVP走进香港数码港,解码AI出海新范式
- 腾讯云以 99.8% 防护率通过AV-C年度评测
- 值得买科技与腾讯云深化“AI+消费”合作,首个消费决策Skills上线腾讯WorkBuddy
- 一码三端!HDC 2026腾讯视频鸿蒙版跨端方案重磅公布
- 李未可AI眼镜成为腾讯云WorkBuddy首批生态伙伴,加速终端入口商业化落地
- 打破传统网络边界,飞猫引入腾讯云聚通加速能力破解游戏延迟难题
- 腾讯首发效率智能体工具集,打造“AI提效新标配”
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- 腾讯云ADP4.0发布:推出Claw模式,助力企业Agent规模化落地
- 腾讯董志强:AI Agent已成为众多企业“数字员工”,安全防护需要同步跟上
- Agent进入“生产级”时代!腾讯云ADP4.0发布,打造企业级 AgentOps平台
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


