格物钛:建立公开数据集标准,赋能AI工程化落地
2021-11-05 11:57:19AI云资讯890
10月30日,由DataFun主办的AI基础软件架构峰会如约而至,格物钛作为AI基础设施领域的创业明星代表与谷歌、字节跳动、第四范式等顶尖科技公司一同亮相MLOps分论坛,格物钛算法负责人薛林继为线上观众带来了一场《建立公开数据集标准,赋能AI工程化落地》主题演讲。

过去十年,无论是阿尔法狗、自动驾驶,还是基因测序,人工智能技术已经开始走出实验室迎来了广泛的应用落地。在这些AI应用落地的背后隐藏了一套非常复杂的系统工程。除了算法的设计开发之外,也涵盖了定义问题,收集数据,特征工程,模型部署上线等各个环节。一套正确、简单、高效并且能规模化复制的算法需要对每一个环节做精细化治理,而非简单的工具链拼凑嫁接。
正如敏捷开发标准的建立帮助广大开发者实现了软件项目的高效敏捷迭代,k8s原生技术成为实施标准后使通用的应用开发编排伸缩变得更加简单。然而AI工程化领域尚未形成一套成熟的实施标准去帮助AI更好地落地。格物钛看到了数据对AI模型效果的重要性和数据获取的难点,为全球开发者、场景和数据的拥有者提供了一个公开数据托管和协作的平台并形成了一套与之匹配的数据使用标准。
格物钛薛林继认为,如果把数据比作食材,把模型比作厨艺的话,有一句话就可以非常好地去描述数据的重要性,那就是优质的食材往往只需要最朴素的烹饪方式。但无论从采集难度还是成本上来看,获取数据始终是个很困难的事情,因此很多研究机构和企业会选择求助于免费的公开数据集资源,很多顶尖的算法也都是以公开数据集作为标准诞生的。不可否认,公开数据集会成为未来AI创新的核心驱动力,它在很大程度上解决了数据获取的难题,同时以自己的形式构建新类型任务,去推动不同算法的发展。
经过很长一段时间的调研,格物钛发现现有公开数据集的存储方式十分散乱,缺乏统一的托管平台,这种各自为战的方式使得不同的数据集提供方会选择使用不同的文件结构和标注方式,这对数据的交换与分享是极为不利的,开发者很难根据自己的任务去精确检索到自己想要的数据集。像可视化、数据标签分布统计这些基础需求的实现都会因为格式不同发生一些变化,算法工程师需要编写更多的胶水代码和新的逻辑去适配这些不同的格式。
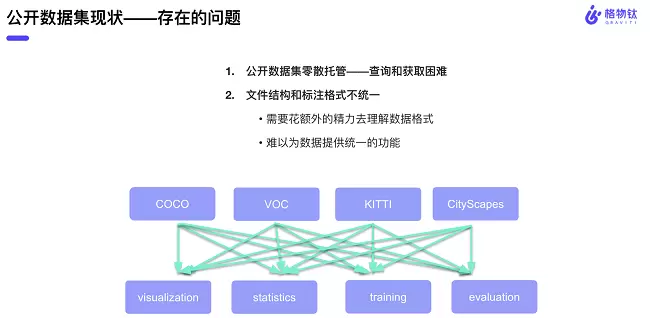
基于对上述痛点的洞察,格物钛认为需要建立一个统一的数据标准来降低数据理解和使用成本,从而去提升整个社区、企业内部的数据交换效率。
格物钛研究了1200多个公开数据集,从数据格式、标注类型、任务类型以及应用场景这四个方面制定了统一的数据集划分规范和标注格式的基础表示方法。在实施的过程中,格物钛将很多类型的数据集放在了公开数据集社区中,目前为止这套标准也是取得了很多社区成员的认可。在推广公开数据集标准的过程中,格物钛发现数据处理是需要很多基础服务的,这些基础服务可以通过数据平台的形式来实现,去解决企业在数据管理层面的痛点。
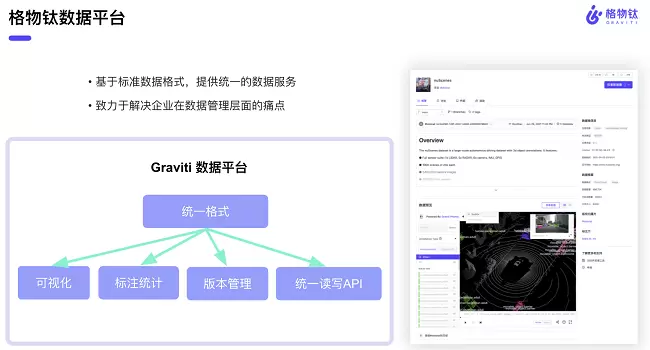
格物钛算法负责人薛林继认为公开数据集社区和数据标准的建立与推广是一个相辅相成的关系,社区为数据标准迭代提供了一个良好的实验环境,每当有一个新的数据集登录到格物钛公开数据社区的时候,都是对当前的数据标准做了一次检验。
格物钛公开数据集社区发展至今依旧面临不小挑战。首先数据集的种类太多,新的数据集层出不穷,只依靠单方的力量去制定标准很难跟得上最新的任务类型和数据种类。其次在一些企业端的场景中,企业数据并不需要去适配公开数据集的标准,用自己的标准就可以满足任务场景的需求。因此,公开数据集标准的设计也需要支持让使用的人自定义标准格式,然后以这种方式去适配多变的数据需求。薛林继在此呼吁希望不断有新的力量加入到社区建设中来,推动数据标准的迭代和演进,共同打造下一代公开数据集标准。
相关文章
- 中兴通讯全面助力《北京数据标准化白皮书》发布,筑牢首都数字经济“标准底座”
- 六大行业领先,电科金仓入选2026中国数据库产业图谱
- 四维图新数据合规闭环服务获A+ Awards新质生产力领航奖
- 秦淮数据CEO吴华鹏: 从IDC到“Token工厂”,AI时代的算力底层逻辑正在重塑
- 刘东:数据空间成为AI时代关键基础设施
- 融合7万小时具身数据,蚂蚁灵波开源具身视频基础模型LingBot-Video
- 2026中国信息通信业发展高层论坛 网络安全与数据安全实践分论坛成功举办
- 博士生的数据噩梦:实验数据管理贯穿科研全生命周期
- 勤哲Excel服务器:助力企业实现数据协同与流程一体化管理
- 数据“浓缩铀”是怎样炼成的 ——专利数据里的高质量数据集建设密码
- “凭感觉”和“看报表”都不够,钛动科技用“创意×数据”打通出海增长双引擎
- 2026全球数字经济大会数据要素发展论坛举办,北京数据集团发布“京算Token工厂”
- 科华数据AI算力基建再落关键一子丨山河湾谷智算中心正式揭牌!
- AI+大数据重塑外贸营销,宜选科技构建全球智能获客新优势
- 勤哲Excel服务器:以数据协同提升运营效率,赋能外贸制造企业数字化转型
- 氧橙携手光粒发布全球首款团队游泳数据监测AR泳镜,开启水上训练数字化新时代
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


