讯飞星火在大模型横评中拔得头筹,成为AI时代的“灯塔”
2023-08-19 18:12:43AI云资讯1306
“从5月6日发布到今天,刚好是我们认知大模型100天的‘百日会战’。”在8月15日的科大讯飞星火认知大模型V2.0发布会上,讯飞董事长刘庆峰说道。而在星火V2.0发布后,全世界的目光再次聚焦到新一轮的大模型竞技潮来。
近日,《麻省理工科技评论》中国对讯飞星火、百度文心一言、商汤商量和阿里通义千问四款主流中国大模型进行了深度评测,结果显示讯飞星火以总分第一的成绩荣登榜首。
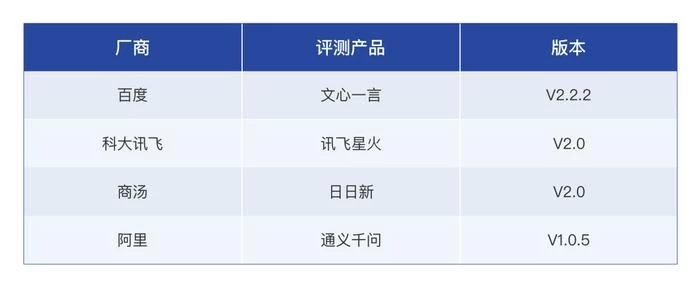
《麻省理工科技评论》是享誉世界的麻省理工学院全资拥有的媒体平台,在业界拥有很强的权威性,也被视为学术界的泰山北斗。此次它采用百分制计量,可参照60%得分率作为“及格线”,除两款参测大模型刚过“及格线”外,百度文心一言获得75.2%得分率,而讯飞星火斩获81.5%最高分,四款大模型的平均得分率为72.6%。可见,讯飞星火一己之力“拉高”的中国大模型的平均水平。
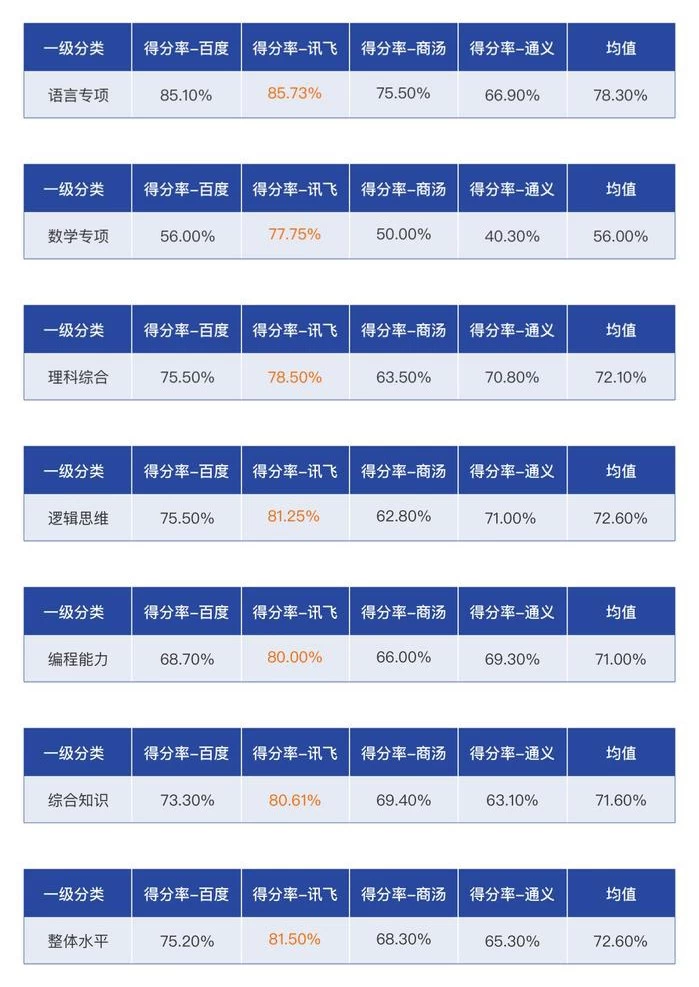
△四款大模型一级分类测试结果(部分)
根据《麻省理工科技评论》设计的600道题目,本次横评重点考察大模型语言、数学、理科、文科、逻辑、编程、综合知识和安全性共计8大类能力(一级分类),并涵盖126个二级分类和290个三级标签。通过拟人考试般的单选、多选、填空、简答四种题型,旨在评出“最聪明”的中国大模型。
作为中文语言大模型,《麻省理工科技评论》将语文专项测试放在了首测,题目是生成一份不同高校毕业大学生首份工作内容和薪资的调研问卷。结果商汤商量和通义千问都采取了“堆砌式”回答,只有讯飞星火与文心一言给出了思路清晰,条理顺畅的问卷结构,双方仅以0.63%得分率不分伯仲。
在随后的数学与逻辑思维等测试项中,讯飞星火开启了“狂飙模式”。《麻省理工科技评论》先采用了一道“求解不等式”的数学题,唯有讯飞给出了解题逻辑和正确答案,并以77.54%得分率远高于56%的平均值,大幅高出21.75%。而在逻辑思维测试中,讯飞完美地解答了“池塘与水壶”的弯弯绕题目,展现了其在空间方位、演绎推理、逻辑谬误检测等方面的优势,并以81.2%得分率高出72.6%的平均值。
当测试来到了代码编程能力阶段,真正的好戏才刚刚开始。在8月15日,讯飞才对星火V2.0的代码能力进行了突破性提升,只因代码能力是支撑认知大模型“智慧涌现”的关键维度,代码能力与“聪明度”直接相关。《麻省理工科技评论》出具的题型是——用Python生成以下代码:def assertBbs(num : int, pow:int):"""实现一个函数,快速幂计算"""。这对于不懂计算机编程的人来说,无异于有字天书,但对于四款大模型来说,它们的答案却各有不同。
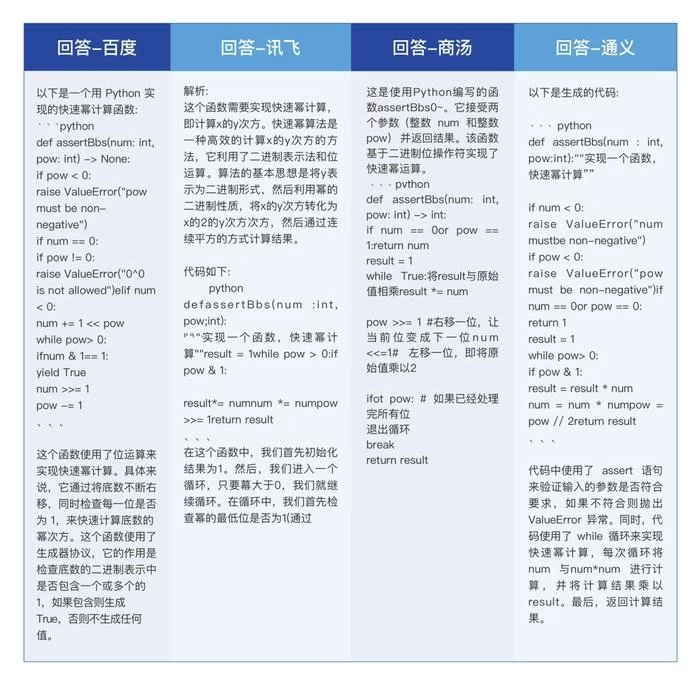
直接看结果吧,讯飞星火不仅生成了正确代码,还给出了“这个函数需要实现快速幂计算,即计算x的y次方”的详细解析。最终讯飞星火以80%得分率明显高于71%的平均值,《麻省理工科技评论》用“表现颇为亮眼”来形容讯飞的代码能力。此外星火在综合知识测试中也以80.61%的得分率远高于71.6%平均率,这并不令人意外,因为综合知识测试涵盖了以上多项能力,在单项中只要获得领先,在综合测试中也不会有太大悬念。
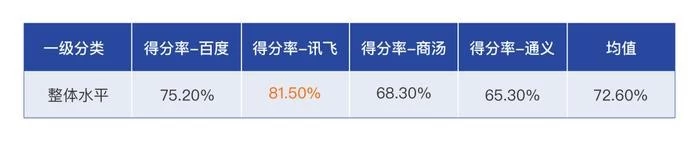
△四款大模型综合得分率
最终《麻省理工科技评论》一锤定音,讯飞星火以81.5分的成绩在本次横评拔得头筹,成为“最聪明”的中国大模型,在综合实力上位列第一梯队。2023年,随着中国人工智能研究在世界版图中占据愈发重要的地位,中国大模型的集体繁荣昭示着AI大航海时代的来临,以讯飞星火为代表的中国大模型佼佼者,正深入产业链上下游共创共建,已成为大模型时代照亮前路的“灯塔”。
相关文章
- 科大讯飞发布招采全链路AI智能体平台 招采行业迈入AI原生新阶段
- 讯飞AI眼镜获SGS佩戴舒适权威认证,40克超轻机身领跑行业
- 扎进流程,抠到极致,走向全球:三个讯飞人的AI产业化攻坚
- 科大讯飞与万新光学集团达成战略合作,共筑AI眼镜产业新生态
- 讯飞AI眼镜亮相世界市长大会 意大利市长现场求购
- 讯飞AI眼镜登场 科大讯飞自主可控软硬一体战略再落一子
- 全国首家!讯飞AI虚拟人交互平台全量功能通过国标认证
- 涉密会议记录安全无忧,讯飞AI录音笔S6系列筑起政企办公信息防护墙
- 未来智能发布viaim讯飞智能体耳机:迈出“AI Agent”战略第一步
- 自主可控 智测未来|科大讯飞人工智能终端测试中心正式揭牌
- 讯飞星火党政智盒发布,打造国内首个安全可控、敢用易用的党政“龙虾”
- 科大讯飞发布玲珑Agent OS,让AI真正走进企业核心业务流
- 全球首发|讯飞Astron开源项目矩阵,构建企业级智能体完整技术生态
- 2026中国翻译协会年会召开,科大讯飞携多语言AI翻译产品矩阵亮相并获评5A级企业认证
- 科大讯飞佛山人工智能产业基地正式启用,助力南海构建AI产业生态
- 科大讯飞重磅布局智能穿戴,讯飞AI眼镜开启跨语言沟通新时代
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


