库瀚科技协办中国移动科技周,共建多样性算力科创发展新未来
2023-09-09 23:42:52AI云资讯1360
近期,中国移动第四届科技周暨战略性新兴产业共创发展大会正式启动。中国移动携手产学研用各方合作伙伴,以“澎湃创新力 战新共未来”为主题,汇聚院士学者、产业大咖、业界专家,围绕云和算力网络、人工智能、6G、大数据、能力中台、安全等领域,聚焦科创前沿,共商协同创新新模式,共谋战新产业发展新未来。
其中,库瀚科技协办了以“多样性算力”为主题的分论坛,该论坛聚焦算力基础设施领域,与各界合作伙伴开展技术创新分享和实践经验交流,促进技术生态繁荣,共同推动数字经济高速发展。

(图片来源:中国移动)
库瀚科技软件架构师邱重阳在本次论坛中,分享了库瀚在全RISC-V架构下高性能存储软件的实践与探索

库瀚分享:挑战与趋势
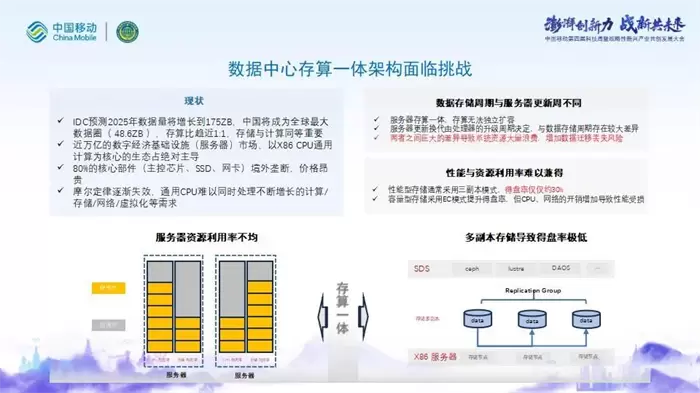
根据IDC预测数据,2025年全球数据量将增长到175ZB,中国将成为全球最大数据圈( 48.6ZB ),存算比趋近1:1,存储与计算同等重要。基础设施(服务器)市场近万亿,目前主导这个市场的还是X86 CPU通用计算为核心的生态。而X86 CPU的核心技术被境外垄断,价格昂贵的同时不符合国内信创趋势。摩尔定律在服务器芯片上逐渐失效,但是高速的存储、网络设备还在快速发展,通用CPU很难再同时处理计算、网络、存储等需求。
在此背景下,数据中心存算一体架构一直面临两个主要挑战:
第一个挑战是数据存储生命周期和服务器更新周期不同,存算一体的服务器架构无法使存算独立扩容,服务器的更新换代由处理器的升级周期决定,一般是2~3年更换,与数据存储5~10年的生命周期有较大区别,两者之间巨大的差异导致系统资源大量浪费,增加数据迁移丢失风险。
另外一个挑战是,传统分布式存储架构使得性能和存储资源利用率难以兼得,通常情况下,性能型存储通常采用三副本模式,得盘率仅仅约30%,容量型存储采用EC模式提升得盘率,但同时增加了CPU、网络的开销,导致存储系统整体性能受损。
数字经济时代,多样应用推动生产进步,当下比较热有ChatGPT、自动驾驶等,这些应用的背后都在消耗巨大的算力。这些不同的应用需要不同的算法,特定的算法匹配特定的算力来处理才能发挥更好的能效比。
业界涌现出越来越多的数据处理单元(DPU)和基础设施处理单元(IPU)专用芯片,在数据流处理路径上取代通用处理器,提升算力能效比。面对新的业务需求,结合计算、网络和存储的新技术发展趋势,新型存算分离的Diskless架构将重新定义数据中心基础设施。Top 厂商积极布局Diskless 架构,通过IPU对接共享的闪存盘框。
我们可以说:传统存储是存储1.0时代,分布式存储开启存储2.0时代,Diskless正在带领我们走进存储3.0时代。
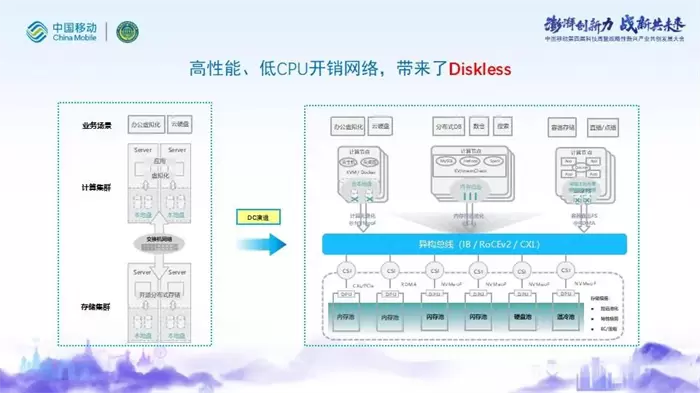
策略与思路
·思路一:存储服务器使用存储专用芯片
目前芯片龙头已经推出的各类智能网卡形态数据处理芯片,主要是满足云厂商自定义的CPU算力卸载需求。头部厂商都在专用数据处理芯片的方向,但是目前看到的数据处理芯片侧重于计算服务器侧网络、计算虚拟化卸载等问题,存储服务器更强调IO加速、EC\压缩的优化,低功耗、低成本的需求。基于存储专用芯片的存储服务器是去x86架构、提升算力能效比、降低存储服务器成本的一个有效手段,当然也同时需要对应存储基础软件来与之配套。
·思路二:通过数据分层机制来解决存储性能和资源的有效利用率难以兼得的矛盾
数据分层存储已经是一个比较老话题了,但就当前数据中心Diskless架构的趋势来说,数据分层本身使用了两层数据分离存储的策略,这和Diskless数据拉远池化的理念更加契合。一般来说,数据分层机制,通过副本机制对外提供统一的高性能存储服务;通过EC策略进行数据存储使得存储系统整体得盘率更高。通过两层架构的技术整合,以提高存储系统整体的存储性能和资源的有效利用率。
·思路三:通过软硬融合的设计提升存储系统资源的有效利用率
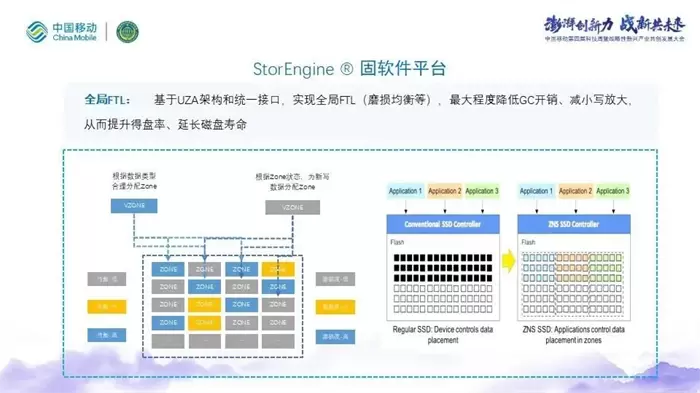
首先,目前SSD访问接口仍然是基于块语义的随机覆盖写,这并不契合NAND Flash的特性,NAND Flash是追加写、擦除后写,SSD为了适配传统块语义的接口,不得不在内部实现转换层FTL,增加了元数据管理、GC、OP空间预留等资源的开销。为了解决这个问题,库瀚提出了open channel技术,以及继承于它的zoned namespace技术,这些技术突破传统的标准硬件接口,打通设备与应用层之间的信息屏障。
其次是存储侧的计算卸载,也可以说是近存储计算。存储服务器侧的数据压缩、EC等算法,不适合利用通用处理器来计算,将其卸载到专用处理器可以显著提升能效比。
实践与探索
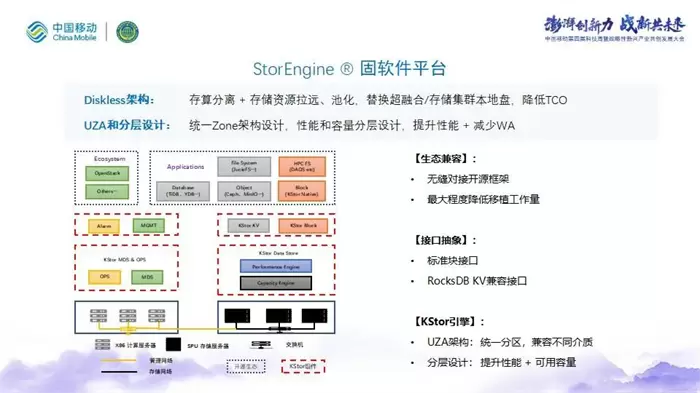
库瀚打造的存储平台是从底层SSD 主控芯片、SSD 固件、存储服务器主控到存储底层基础软件全技术栈打通的一个存储架构,在IO链路上基于全RISC-V架构主控平台,软硬融合设计的全闪存存储平台。
库瀚两颗RISC-V芯片——Aurora SSD主控、eSPU覆盖从应用到存储全流程,eSPU主板主控形态支持实现无x86架构的存储服务器,eSPU智能网卡形态面向数据服务基础设置场景;Aurora SSD主控支持实现PCIE 5.0/4.0等多型号的高性能企业级固态硬盘。
库瀚StorEngine 软固件平台是一套软件定义存储生态的高性能分布式存储软件基础计算模组,也是两颗RISC-V芯片平台的存储基础软件,以助力数据中心实现在现有硬件平台、eSPU/Aurora硬件平台下发挥业界领先的性能。
StorEngine 既可以运行在x86\ARM平台上,也可以运行在eSPU(RISC-V)平台上。
库瀚StorEngine 采用Diskless 存算分离架构,把存储资源拉远池化,以替换传统存储中的本地盘;通过高密度的SPU盘框 + 存储计算分开扩容的能力,来降低数据中心整体成本。
库瀚StorEngine 使用数据分层和统一zone设计,性能层和容量层的分层设计使得系统在提升得盘率的同时,能够提供高性能存储服务;统一zone架构,使StorEngine兼容不同介质存储设备,全局存储资源以zone为单位进行分配,实现全局FTL,使SSD的磨损均衡可以在全局作用,同样可以延长SSD的寿命。
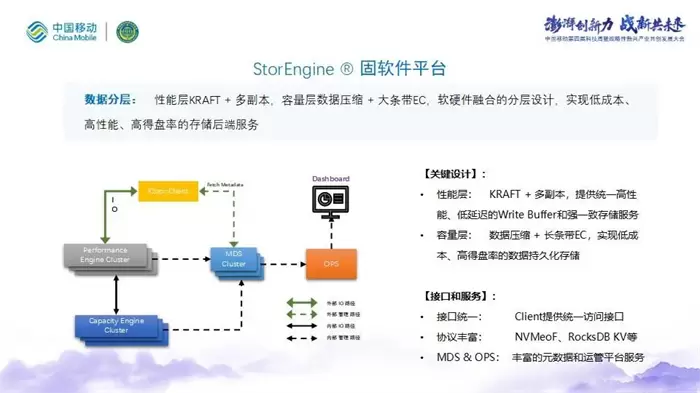
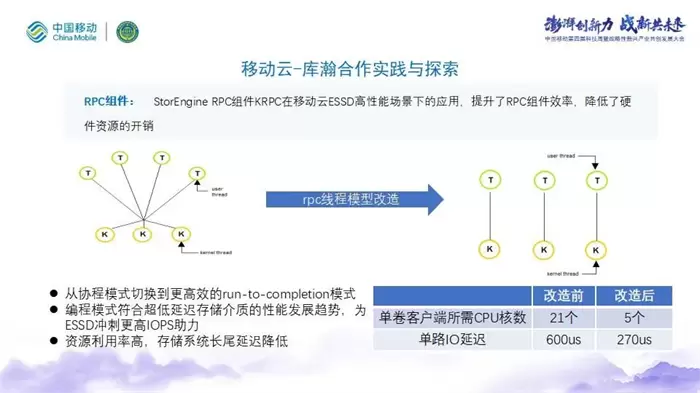
库瀚与中移已就存储系统项目开展了合作与探索。中移ESSD是一套全自研的高性能全闪分布式存储系统,单卷可达百万 IOPS以上;库瀚StorEngine RPC组件KRPC在中移动ESSD高性能场景下的应用,提升了RPC组件效率,降低了硬件资源的开销。单卷客户端所需的CPU核心数量从改造前的21个下降为改造后的5个,与此同时单路IO延迟也从600us下降到270us,整个资源的利用率得到了显著的提高,存储系统的长尾延迟也有所改善。
相关文章
- 首创“共享家电 + AI 家庭算力”模式,窝窝优加重塑智慧家庭服务新链路
- 2070 TFLOPS 算力加持,加速进化发布新一代具身开发旗舰平台 Booster
- 迎接产业爆发风口,中科源本高端锂离子电容器锚定AI算力刚需
- 加速进化发布 Booster T2:以旗舰算力与运动能力推动人形机器人走向真实世界
- LEAP East 2026观察:九章云极提出AI成为公共设施的时代降临,机器流量冰山凸显万亿算力变局
- 海光亮相光合组织大会,展示全景AI算力底座能力
- 首个全国产十万卡超智融合算力系统落成,同步启动第二套研制、建设
- 算力新基,为AI而生!阳光电源EnerNeo固态变压器发布
- 秦淮数据CEO吴华鹏: 从IDC到“Token工厂”,AI时代的算力底层逻辑正在重塑
- 国家最大算力网络接入十万卡超智融合算力池
- SAI-DA 1.0丨GEOTA平台——以数字算力,革新新药研发
- 立讯精密正式登陆港交所:年内港股最大IPO,AI算力打开全新成长空间
- 新品发布 | 绿盟安全智算一体机,构建“算力、调度、安全“深度融合的AI基础设施
- 英伟达Rubin全液冷时代,川润股份“算力液冷+绿色能源”全链条闭环服务卡位千亿赛道
- 光合组织2026智能计算应用大会即将召开,国产AI算力全链发展进入应用检验期
- 从太空算力到世界模型|佳格天地硬核科创亮相 2026 全球数字经济大会
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


