浪潮信息发布源2.0基础大模型,千亿参数全面开源
2023-11-27 21:42:31AI云资讯1390
11月27日,浪潮信息发布"源2.0"基础大模型,并宣布全面开源。源2.0基础大模型包括1026亿、518亿、21亿等三种参数规模的模型,在编程、推理、逻辑等方面展示出了先进的能力。
当前,大模型技术正在推动生成式人工智能产业迅猛发展,而基础大模型的关键能力则是大模型在行业和应用落地能力表现的核心支撑,但基础大模型的发展也面临着在算法、数据和算力等方面的诸多挑战。源2.0基础大模型则针对性地提出了新的改进方法并获得了能力的提升。
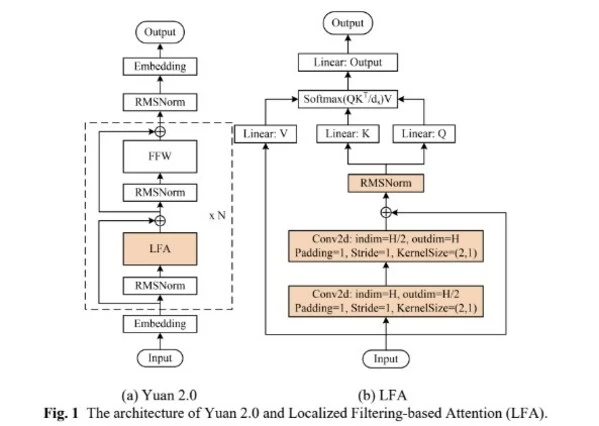
算法方面,源2.0提出并采用了一种新型的注意力算法结构:局部注意力过滤增强机制(LFA:Localized Filtering-based Attention)。LFA通过先学习相邻词之间的关联性,然后再计算全局关联性的方法,能够更好地学习到自然语言的局部和全局的语言特征,对于自然语言的关联语义理解更准确、更人性,提升了模型的自然语言表达能力,进而提升了模型精度。
数据方面,源2.0通过使用中英文书籍、百科、论文等高质量中英文资料,降低了互联网语料内容占比,结合高效的数据清洗流程,为大模型训练提供了高质量的专业数据集和逻辑推理数据集。为了获取中文数学数据,我们清洗了从2018年至今约12PB的互联网数据,但仅获取到了约10GB的数学数据,投入巨大,收益较小。为了更高效地获得相对匮乏的高质量中文数学及代码数据集,源2.0采用了基于大模型的数据生产及过滤方法,在保证数据的多样性的同时也在每一个类别上提升数据质量,获取了一批高质量的数学与代码预训练数据。

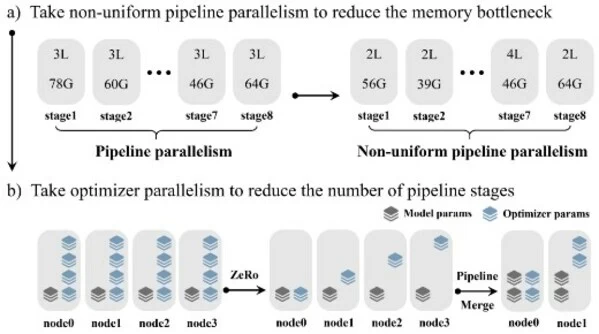
算力方面,源2.0采用了非均匀流水并行的方法,综合运用流水线并行+优化器参数并行+数据并行的策略,让模型在流水并行各阶段的显存占用量分布更均衡,避免出现显存瓶颈导致的训练效率降低的问题,该方法显著降低了大模型对芯片间P2P带宽的需求,为硬件差异较大训练环境提供了一种高性能的训练方法。
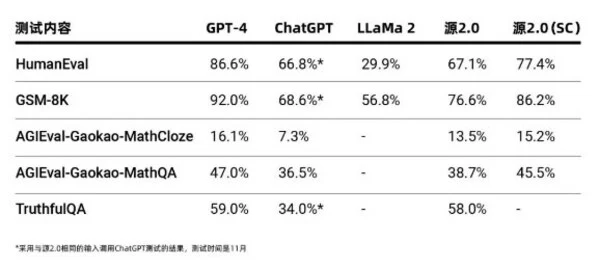
源2.0作为千亿级基础大模型,在业界公开的评测上进行了代码生成、数学问题求解、事实问答方面的能力测试,测试结果显示,源2.0在多项模型评测中,展示出了较为先进的能力表现。
相关文章
- 浪潮信息发布“元脑SD200“超节点,面向万亿参数大模型创新设计
- 打造更AI的操作系统 《龙蜥+超级探访》第三期走进浪潮信息
- 浪潮信息:元脑企智DeepSeek一体机将举办生态伙伴推介体验会
- 维谛技术 X 浪潮信息 | 强化产业合作,共拓液冷AI算力新格局
- 第一份额:浪潮信息存储成功中标运营商备份一体机集采项目
- 亿级数据、千条告警秒级处理!浪潮信息InManage智能管理10万+IT设备
- 企业大模型应用开发提速 浪潮信息发布元脑企智EPAI一体机
- 浪潮信息Infinistor:高效运维引擎,驱动企业数据价值最大化
- 液气换热型液冷数据中心首个技术标准发布,浪潮信息牵头编制
- 浪潮信息:元脑企智EPAI助力金融大模型快速落地
- 阿里云、字节、浪潮信息、英特尔、电标院: OpenBMC是服务器固件大势所趋
- 显著提升万卡GPU训练性能,浪潮信息X400荣获“2024 DPU&AI Networking Awards“!
- 迎接车路云一体化!浪潮信息路侧计算单元RSCU,可在55度正常工作
- 来布科技数保保软件与浪潮信息云峦KeyarchOS完成澎湃技术认证
- 让服务器开机远离飞机起飞!浪潮信息首创3秒智能控温技术,降噪30.4%
- 浪潮信息赵帅:开放计算创新 应对Scaling Law挑战
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench


