深耕文档型数据库12载,SequoiaDB再开源
2024-01-16 11:29:27AI云资讯969
1月15日,巨杉数据库举行SequoiaDB新特性及开源项目发布活动。本次活动回顾了巨杉数据库深耕JSON文档型数据库12年的发展历程与技术演进,全面解读了SequoiaDB包括在高可用、安全、实时、易用性四个方向的技术特性,宣布了2024年面向技术社区的开源计划。此次发布活动不仅是对SequoiaDB性能的全面介绍,更是对十余年来始终坚守以JSON文档型数据库内核为技术底座的发展历程的深刻回顾。不忘来时路,方知向何行,巨杉数据库也将在2024年新年伊始,迎来新的篇章,开启新的征程!
稳健发展,行业影响力不断提升
回顾过去,巨杉数据库自2011年研发内核、2012年公司成立,至2013年推出SequoiaDB v1.0版本,再到如今已走过十二个春秋。历经12年的洗礼,巨杉数据库也取得了令人瞩目的成就。目前,巨杉数据库已经在超过100家大型银行及金融机构的核心生产业务规模应用,覆盖各行业的企业用户总数超过1000家。在金融行业,其客户群体涵盖国有银行、股份制银行、省级农信、城商行、保险、证券等金融机构,同时还积极扩展政府、汽车、新能源等多个行业客户,赢得了广泛的市场认可。其中超过50家企业的应用时间已超过6年,最长的系统运行时间甚至达9年。自成立以来,公司实现稳健发展,行业影响力不断提升,数据量及业务接入保持持续增长态势。
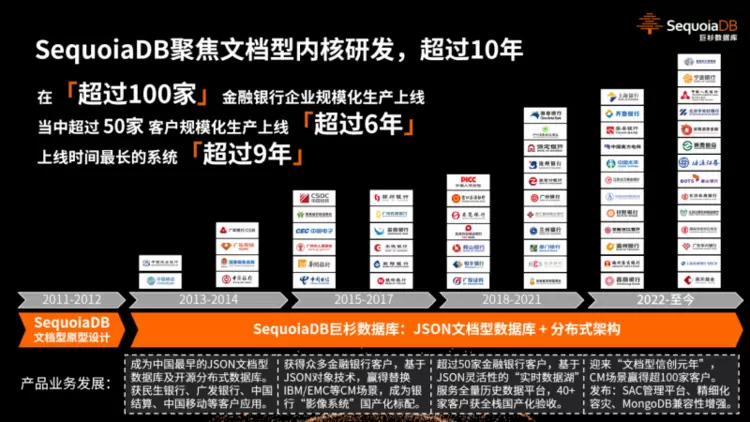
守正创新,发展JSON文档型内核
巨杉数据库SequoiaDB以 JSON 文档型数据库内核为技术底座,通过分布式架构为众多客户提供了多元化的业务和全方位的支持。正是因为对技术创新的坚持以及对市场需求的洞察,巨杉数据库始终坚守JSON文档型内核,在持续迭代中实现创新发展。
在JSON基础能力方面,从最初 v1版本,实现 CURD 原子性的操作以及基础的ACID支持,到 v2 版本逐步提升对LOB大对象的存储能力,标志着巨杉数据库具备“多模数据”处理能力,同时支持存储过程、聚集计算等特性。在 v3.0 版本中,进一步提供自增序列全文检索、基于时间点的数据恢复和兼容部分 Mongo 语法。跨越4.0版本,到v5.0 版本,SequoiaDB 着力提升稳定性能,对于统计信息、访问计划、存储等进行了大量优化,提供死锁检测等功能,并进一步地兼容 Mongo 3、 Mongo 4 的语法。
在分布式管理方面,从基础的多分区原生分布式架构,逐步提供读写分离、主子表、策略访问、多中心容灾、精细化容灾等特性,持续增强分布式能力。
在安全性方面,涵盖从基础的鉴权、加密到信创的各类能力。此外,推出了SCM内容管理引擎,专注于非结构化数据和多模数据处理的统一数据生命周期管理。
在易用性方面,通过SAC运营的管理平台,全面提升DBA运维的便捷性。
十二年来,巨杉数据库基于JSON文档型数据底座和分布式架构的不断更新与迭代,为企业提供可靠的数据处理和存储解决方案,帮助企业优化业务效率,提升客户满意度。

广泛拓展,基于文档型技术的应用场景
在中国乃至全球范围内,“CM场景”是文档型技术应用中重要且突出的场景。基于处理多变的数据结构和庞大的数据量的迫切需求,催生了“CM内容管理平台”,同时极大地推动了SequoiaDB技术的创新。巨杉数据库持续跟进客户需求,进行技术迭代,实现从1.0 到 5.0 的跨越式发展。巨杉数据库为金融银行客户提供,稳定、可靠、可持续扩展的「CM内容平台」成为「银行影像平台」及「非结构化管理平台」的数据基础设施,目前已吸纳超过100家客户使用该场景。可以说,基于文档型技术并应用于“CM内容管理平台”场景是巨杉数据库取得的最为显著的成果之一,这一场景也持续为巨杉数据库贡献了超过85%的客户及营收,成为业务的主打业务场景。
此外,文档型数据库在在线业务系统、实时数据湖、IoT领域以及AGI人工智能等领域也得到广泛应用。JSON灵活的格式适合各种在线业务系统,尤其是面向需要快速迭代开发的各类APP的业务应用,基于文档型数据库的开发,可以显著提升团队的研发效率。在实时数据湖方面,巨杉数据库借助JSON灵活的数据处理能力,已助力多家客户构建全量历史数据平台,支持跨系统、跨业务的实时高并发数据查询。

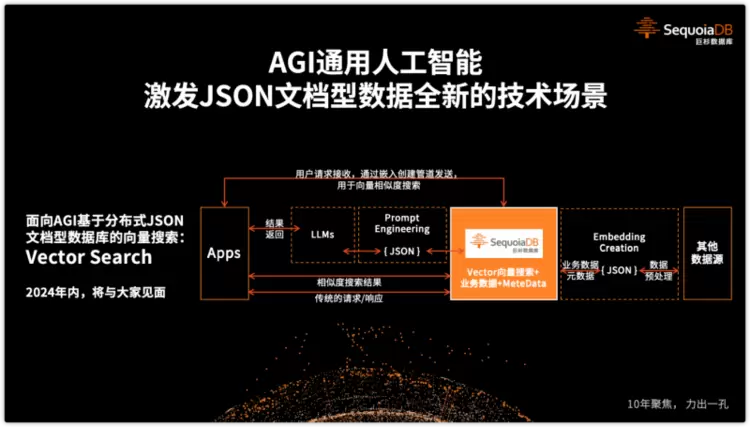
Vector Search基于文档型技术,探索AGI数据应用新边界
AGI 通用人工智能的发展,将进一步推动JSON文档型数据类型的应用(实际上,本次发布活动中,Vector Searche部分的讲解也是通过AI技术合成的)。
传统AI应用中,需要存取及处理的是,海量的半结构化「 CM 内容管理」数据、「动态标签」数据,以及各类非结构化对象数据。这些都正是 SequoiaDB 过去12年聚焦及取得显著成果的领域技术,而 AGI 全新的爆发性发展,必将对 JSON 文档型技术,带来全新的机遇及技术挑战。当前,业界领先的 Open AI、文心一言等大模型平台中,JSON 已经被指定为对内,及对外,函数调用的,标准数据传输格式。
另外,我们可以看到 “向量数据” 在 AGI 通用人工智能发展中,得到了关键的应用,需要更有效的数据库处理能力。
向量数据的存放格式,天然就可以用 JSON 结构表示,非常适合通过文档型数据库处理。然而,单独使用向量数据,并不能解决业务的全景问题。在业务过程中,向量数据还必须与其他业务数据进行组合使用,才能发挥其价值。因此 SequoiaDB 也正在探索,为文档型数据库提供 「Vector Search 向量搜索」能力,为保存到 SequoiaDB 的向量数据,提供高效的查询能力,这一特性将在2024年与大家见面。
要注意的是,我们并不需要发展独立的向量数据库产品。而是基于深耕了12年的 JSON 文档型数据库底座技术为基础,进行向量查询能力的扩展,这将可以帮助企业,驱动实体世界的更多数据,和 AGI 通用人工智能进行有效链接,释放全量数据价值。
四大特性,释放全量数据价值
巨杉数据库基于JSON文档型底座对SequoiaDB 进行了全面升级,此次发布活动全面解读了SequoiaDB 的四大特性——高可用、安全、实时和易用。

高可用:文档型数据库处理的数据,包括了结构化的元数据、半结构化的标签数据,以及非结构化的对象数据。对于PB级大数据或上百节点规模的大集群,在面对重大灾难时的数据可靠性、数据一致性和系统可用性时都面临着巨大挑战。精细化容灾能有效地帮助客户实现针对这些数据的多中心容灾,从而提升整体系统的高可用和数据高可靠能力。
安全:巨杉数据库不仅在技术上通过国密算法和硬件加速来平衡安全与性能,还提供了跨国内外不同芯片、不同操作系统的混合部署能力。这意味着巨杉数据库可以实现集群的异构部署,平滑地进行硬件资源的替换,对上层业务系统做到完全透明,保障业务连续性。
实时:巨杉数据库凭借JSON文档型数据结构的Schema灵活性,为企业提供了全量数据底座。DDL的实时变更、横向扩展能力,以及高性能的并发点查能力等都颠覆了传统ODS数据贴源层的界限,使得ODS能够服务于实时业务,满足对客实时数据查询和企业内部跨业务数据实时汇总的需求。
易用:巨杉数据库进一步增强了SAC的监控、告警和管理等功能。一站式的数据管理工具,极大地方便了DBA的管理工作,提高了问题排查的效率并简化了对系统的监控管理,从而为业务带来更高的稳定性和效率。
开放、开源共赴新篇章

新年伊始,巨杉数据库也将谱写崭新篇章。发布会介绍,巨杉数据库决定将在2024年Q1再次发布开源版本,不仅希望获得社区同仁的参与和监督,让产品未来发展更透明;同时也承担历史责任,希望通过开源的方式吸引更多合作伙伴,共同发展中国的分布式文档型数据库生态链,促进业务的快速迭代和开发效率的提升。近期,SequoiaDB新版本的源代码将通过Gitee、GitCode及GitHub再次开源。

相关文章
- 阿里MuleRun上线Pages数据库模式,零门槛交付可管理真实数据的完整网页
- 2026华为云创想者大会|华为云数据库全系AI升级,拥抱Agentic新时代
- 擎策•知海知识产权数据库迭代更新,专利检索&管理效率再提一倍!
- 金仓数据库助力广州燃气核心系统完成升级改造
- 中国移动磐维数据库V3.0通过国家安全可靠测评
- GoldenDB三款产品通过国测 筑牢国产数据库安全可靠新标杆
- 从“多库并立”到“一统底座”,AI时代数据库必须收拢
- 融合数据库不是“一库打天下”,而是“内核能力重构”
- 金仓时序数据库助力北京轨道交通应急指挥调度平台上线
- 擎策·知海数据库商标检索重大升级:国内国际数据双扩容,总量突破2.03亿条
- 筑牢数字中国底座 国产数据库从可用到引领的硬核突围
- AIOps正在杀死传统DBA?数据库智能运维的3个进化方向
- AI时代下的数据库选型:为什么“语义兼容”比“语法兼容”更重要?
- 2026时序数据库趋势:超融合(时序+关系+分析)是噱头还是未来?
- 效率提升60%,金仓数据库助力中国石化财务共享系统升级
- 平凯数据库云服务正式发布:以极致弹性,助企业实现高达 50% 的架构降本
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力


