ABeam(德硕)|大语言模型系列 (1) : 大语言模型概览
2024-01-29 21:37:39AI云资讯3500
大语言模型系列引入篇
自从图灵测试在20世纪50年代提出以来,人类一直不断探索机器如何掌握语言智能。语言本质上是一个由语法规则支配的错综复杂的人类表达系统。
近年来,具备与人对话互动、回答问题、协助创作等能力的ChatGPT等大语言模型应用横空出世,引发社会热议,成为全球科技的竞争焦点。大语言模型也成为人工智能发展的热点方向,有望给人工智能创新带来爆发式增长。
本系列文章中,ABeam将聚焦于大语言模型,探讨大语言模型的商业模式和行业应用案例,以期为不同类型的企业带来迎接科技浪潮、拥抱大模型的新灵感。
本期作为大语言模型系列的引入篇,将为大家介绍语言模型及其演进历程、大语言模型的底座、概念、特点等基本概览。
01关于语言模型
About Language Model
1 概念
语言模型是根据语言客观事实而进行的语言抽象数学建模,是一种对应关系。语言模型与语言客观事实,就如同数学上的抽象直线与具体直线之间的关系。
2 语言模型的任务
■ 判断句子的语言序列是否为正常语句
【例】语言序列W1,W2,W3,…,Wn
P=概率
语言模型即P(W1,W2,W3,…,Wn )
■(在语言识别、机器翻译等任务中)对候选答案进行打分排序,以此筛选出正确结果
【例】语音识别:
结果1-再给我两份葱,让我把记忆煎成饼
结果2-再给我两分钟,让我把记忆结成冰
评分:结果2>结果1
02语言模型研究的关键概念及技术
Key Concepts and Techniques
语言模型研究中包含多种关键概念及技术,通过改进各个方面,达成模型研究的发展。

数据来源:ABeam根据公开资料整理
03语言模型演进里程
Milestones
从传统二十世纪中期的N-gram模型,渐渐发展至神经网络模型,再到现今的Transformer架构,语言模型一路不断创新,实现了自然语言处理领域的重大进步。
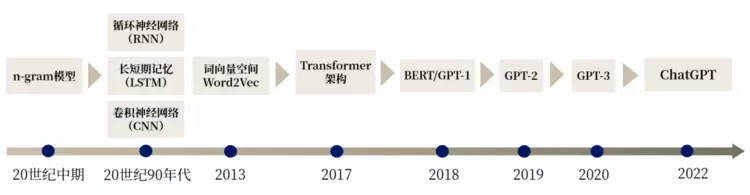
数据来源:ABeam根据公开资料整理
04大模型底座--Transformer架构
Transformer Architecture
Transformer模型是一种深度学习架构,自2017年推出以来,彻底改变了自然语言处理(NLP)领域的发展。该模型由Vaswani等人提出,并已成为NLP界非常具有影响力的模型之一。
它在机器翻译、文本摘要、问答系统等多个自然语言处理任务中取得了显著的性能提升。Transformer模型的突破性表现使得它成为现代自然语言处理、研究和应用中的重要组成部分。它能够捕捉复杂的语义关系和上下文信息,极大地推动了自然语言处理的发展。
1 特点
Transformer模型引入了自注意力机制(self-attention),使得模型不仅能够关注当前的词,还能关注句子其他位置的词,进而确定输入的序列哪些与输出强相关。
故而训练模型时不必标记所有的训练数据,可以直接导入大段文本,进行留空训练,对输出内容进行纠正。
05关于大语言模型
About Large Language Models
1 概念
大语言模型(LLM)是指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。大语言模型可以处理多种自然语言任务,如文本分类、问答、对话等,是通向人工智能的一条重要途径。
2 特点
规模庞大、包含数十亿参数,以帮助它们学习语言数据中的复杂模式。
3 与小模型的区别
大语言模型与以前AI模型的不同之处在于其通用性和泛化能力。它们通过预训练阶段获取了深刻的语言理解,使其在处理不同任务时无需大量标注样本,这降低了依赖标注数据的程度。
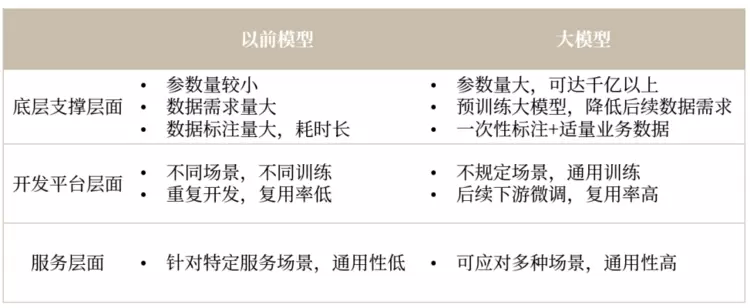
数据来源:ABeam根据公开资料整理
4 目前主流大语言模型(部分)
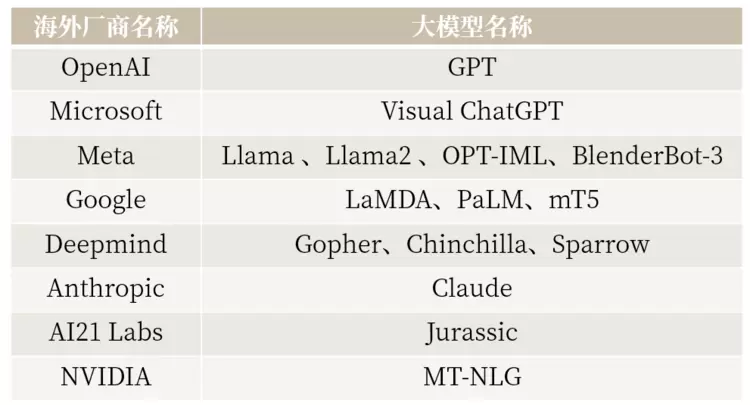
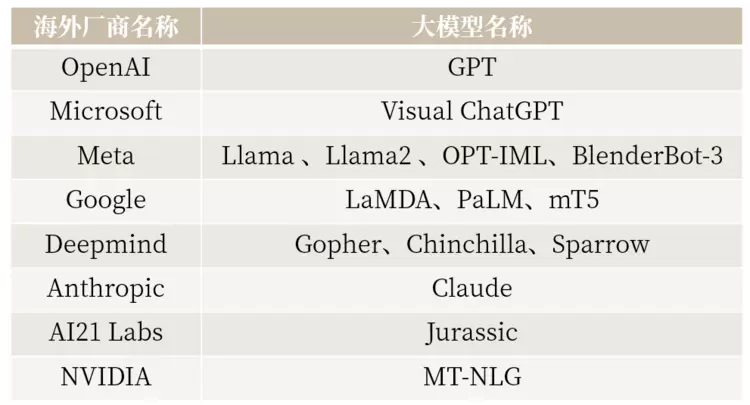
下期,ABeam将着眼于
大语言模型的商业模式及商业价值,
为大家解锁更多大语言模型的深层逻辑。
敬请期待~
相关文章
- 英矽智能上线大语言模型训练框架MMAI Science Gym,赋能通用模型实现垂类领域专精
- 美光HBM3E芯片位于AI与高性能计算新纪元,驱动大语言模型认知飞跃
- 认知科学研究院首次发现:进化策略竟能超越强化学习训练大语言模型
- 全球首款结合深度学习与大语言模型的酒店房型匹配系统:途灵科技TourMind 正式推出MappingMind解决方案
- Zetrix AI 推出全球首个伊斯兰教义大语言模型 “NurAI“
- ICCV 2025 | 腾讯优图实验室大模型8篇论文入选,涵盖风格化人脸识别、AI生成图像检测、多模态大语言模型等方向
- 大语言模型升级!时空壶 X1 同声传译器的上限在哪里?
- 时空壶 X1 融入大语言模型,AI 同传性能飞跃,持续领航多元场景应用
- 大米和小米推出基于大语言模型全面测评儿童语言能力AI工具
- 新加坡MERaLiON大语言模型创东南亚先河,以多语言处理与情感智能实现技术突破
- 科大讯飞亮相GITEX ASIA 2025,全球首发本地部署大语言模型一体化方案
- 「唐能风采」唐能翻译参与并主持《人人都用得上的翻译技术》新书发布会暨大语言模型赋能沙龙活动
- 极空间私有云联合UnifyDrive亮相CES:发布全球首款大语言模型 AI NAS
- IC China 2024|大语言模型加速半导体制造CIM2.0变革
- 顺丰丰语大语言模型来了!物流垂域能力全面超越通用模型,已应用于20余个场景
- 这家顶尖制造企业,如何借助AI大语言模型升级客户服务?
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


