行空板MultinomialNB模型实现古诗词作者快速识别
2024-08-30 17:22:57AI云资讯2277
在浩瀚的古诗词海洋中,琳琅满目的佳句常常让人陶醉,但很多人却难以记住每一句的作者。当人们欣赏这些优美的诗句时,常常会想起那位才华横溢的作者,却苦于无法准确识别他的作品。为了解决这一难题,行空板引入了MultinomialNB模型——一种用于文本分类的机器学习模型,朴素贝叶斯分类器的一种。通过这一模型,行空板实现了古诗词作者的快速识别,不仅提升了古诗词的互动性,还为诗词爱好者提供了全新的体验,使他们在欣赏之余,轻松了解背后的创作人。
一、实践清单
硬件清单:

软件使用:Mind+编程软件x1
Mind+是一款拥有自主知识产权的国产青少年编程软件,集成各种主流主控板及上百种开源硬件,支持人工智能(AI)与物联网(IoT)功能,既可以拖动图形化积木编程,还可以使用Python/C/C++等高级编程语言,让大家轻松体验创造的乐趣。
二、实践过程
1、硬件搭建
1、将摄像头接入行空板的USB接口。
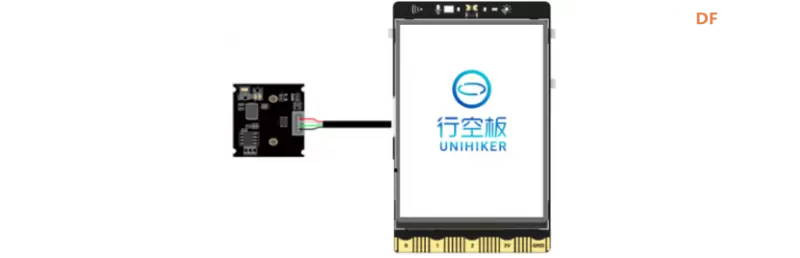
2、通过USB连接线将行空板连接到计算机。

2、软件编写
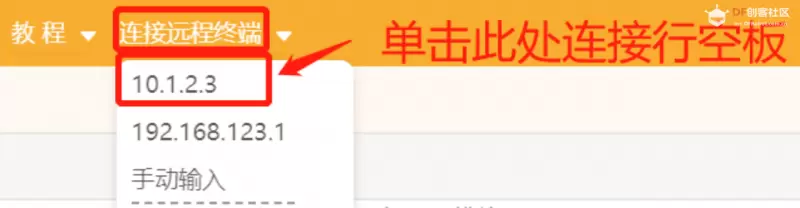
第一步:打开Mind+,远程连接行空板
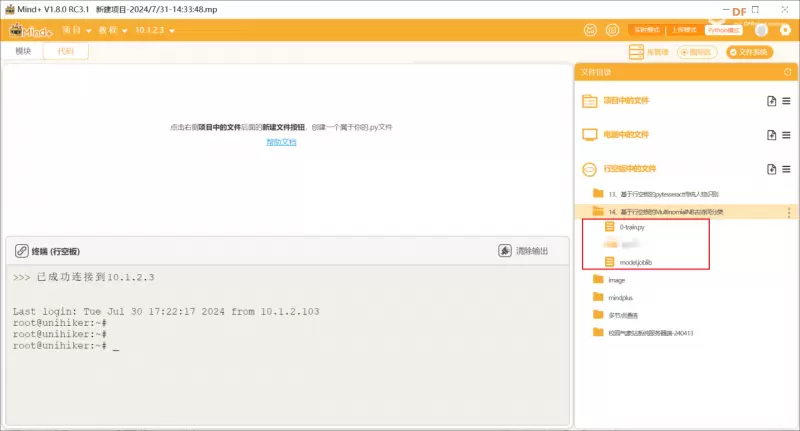
第二步:在“行空板的文件”中新建一个名为AI的文件夹,在其中再新建一个名为“基于行空板的MultinomialNB古诗词分类”的文件夹,导入本节课的依赖文件。Tips:0-train.py是用来训练古诗词和对应作者的程序,可以在其中增加数据集,model.joblib是训练生成的模型,用于对古诗词进行分类,这里我们直接用即可。
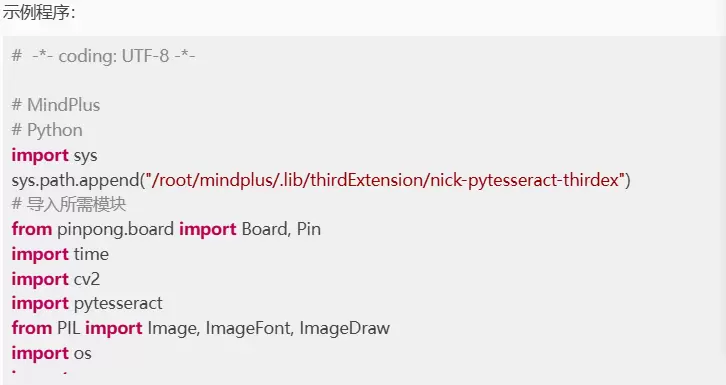
第三步:编写程序
在上述文件的同级目录下新建一个项目文件,并命名为“main.py”。
示例程序:
3、运行调试
第一步:运行主程序运行“main.py”程序,可以看到初始时屏幕上显示着摄像头拍摄到的实时画面,将摄像头画面对准古诗词,如这里为“红掌拨清波”,然后按下板载按键a,将此帧图像拍摄保存,之后自动识别图像上的文字,在Mind+软件终端,我们可以看到识别到的中文结果以及模型预测的该古诗词的作者。
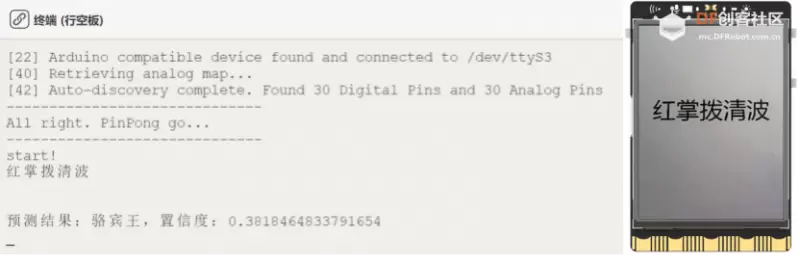
Tips:如果预测结果不准确,可以自行调整“0-train.py”中的数据集,训练模型。
4、程序解析
这段程序通过使用 OpenCV 库调用摄像头,实时从摄像头读取图像,然后使用 Tesseract 进行 OCR(光学字符识别)识别,并将结果显示在图像上。识别出的文本还会通过一个预训练的 MultinomialNB 模型进行分类,并显示预测结果和置信度。具体流程如下:
① 初始化:
· 导入所需的库和模块。
· 初始化 UNIHIKER 开发板。
· 设置 Tesseract OCR 的路径。
· 打开摄像头并设置分辨率和缓冲区大小。
· 创建一个全屏窗口用于显示图像。
② 定义函数:
· 定义 drawChinese 函数,用于在图像上绘制中文字符。
③ 加载模型:
· 使用 joblib 加载预训练的 MultinomialNB 模型。
④ 主循环:· 进入无限循环,从摄像头读取图像。
· 检测按键输入:· 如果按下 'b' 键,退出程序。
· 如果按下 'a' 键,捕获当前图像并保存到指定路径。
· 使用 Tesseract 进行 OCR 识别,提取图像中的文本。
· 使用预训练的 MultinomialNB 模型对提取的文本进行分类预测,输出预测结果和置信度。
· 在图像上绘制识别到的文本,并在窗口中显示处理后的图像。
⑤ 结束:
· 释放摄像头设备,并关闭所有 OpenCV 窗口。
三、知识园地
1. 了解MultinomialNB模型
MultinomialNB 是一个用于文本分类的机器学习模型,属于 scikit-learn 库中的一部分。它是多项式朴素贝叶斯(Multinomial Naive Bayes)分类器的实现。下面是对 MultinomialNB 的详细介绍:
概述
· 定义:MultinomialNB 是朴素贝叶斯分类器的一种,专门用于离散型特征(通常是单词计数或词频等文本数据)。
· 朴素贝叶斯模型:基于贝叶斯定理的一种简单但功能强大的概率分类器,假设特征之间是条件独立的。
· 多项式模型:适用于特征表示为多项式分布的场景,通常用于文本分类任务,如垃圾邮件检测和文档分类。
特点
· 简单有效:模型简单,计算效率高,适合大规模数据集。
· 文本分类:在自然语言处理(NLP)领域,尤其是文本分类任务中表现出色。
· 概率输出:可以输出每个类别的预测概率,帮助理解模型的信心度。
主要功能
1. 文本支持:
· 适合分类离散型特征,特别是词频或词袋模型(Bag-of-Words)表示的文本数据。
· 利用词频统计和类别条件概率进行分类预测。
2. 多类别支持:
· 支持多类别分类任务,可以处理多个类别的分类问题。
关于《行空板MultinomialNB模型实现古诗词作者快速识别》项目的详细信息,请访问DF创客社区,了解更多。
相关文章
- 世界模型与VLA并非对立,云迹科技单臂协作机器人如何融合两条技术路线
- 中科第五纪首次提出「3D世界-动作模型」新范式,斩获CVPR2026冠军!
- 国内首个!飞渡科技工业级空间智能大模型“峥嵘“通过国家网信办备案 空间智能产业迎来合规商用里程碑
- 自变量发布QUANXTA Zero系列无本体数采方案,从具身模型反向定义数采基建
- 视频生成大模型搞不定几何一致,如视让每一帧符合物理世界的逻辑
- Om AI联汇发布VLX:全球首个面向物理世界的端侧流式多模态模型
- 人人都有大模型,千匠网络押注的是落地能力
- AI大模型产业应用创变营顺利举办,智数集团携东莞软协共探AI产业落地路径
- 全球前三!中国电信网络大模型及智能体 斩获GSMA多项国际权威认证
- 大模型重塑视觉 AI,商汤获Gartner认定为全球前沿技术创新者
- 映翰通发布 Mo 62A / Mo 68A AI 单板计算机,加快边缘 AI 从模型到原型
- 从生态聚合到资源调度,移动云以模型服务平台开启智算服务新范式
- 从《自然》封面走向产业一线:清华团队探索世界模型
- 国内首家!浩鲸科技鲸智大模型Token运营平台获信通院双认证
- 天数智芯全栈算力底座Day0适配GLM-5.2 自主创新架构铸就国内大模型长程推理新标杆
- 越疆将发布下一代陪伴交互AI人形机器人,以自研大模型重新定义家庭具身智能
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


