出门问问重磅发布新七代TTS 引擎TicVoice 7.0,让AI“说人话”
2025-03-07 19:08:02AI云资讯14613
出门问问联合香港科技大学、上海交通大学、南洋理工大学、西北工业大学等研究机构,共同开源新一代语音生成模型 Spark-TTS,并重磅推出了Spark-TTS的商业化高品质 TTS 引擎:TicVoice 7.0。
TicVoice 7.0作为出门问问的第七代 TTS 引擎,能在不借助额外生成模型的辅助下(比如基于flow matching进一步预测声学特征),仅用语言模型(序列猴子)以单阶段、单流方式实现 TTS 生成。它不仅具备超自然的语音克隆与跨语种生成能力,还可根据用户需求定制精品专属声音。
目前,出门问问已经将TicVoice 7.0落地于旗下AI配音产品「魔音工坊」,为用户带来了更好的服务及效果体验,包括SOTA 的3秒语音克隆能力、更卓越的精品发音人定制效果等,在客服、有声书、情感直播、影视解说、影视配音等应用场景下带来更极致的用户体验。
TicVoice 7.0 :开启全新语音编码范式,技术 Buff 叠满
出门问问自2012 年成立以来,便坚持在人工智能语音领域深耕,不断迭代 TTS 引擎。凭借深厚的技术积累及先进的产品应用经验,出门问问先后推出了「魔音工坊」「奇妙元」「元创岛」等语音或搭载语音功能的产品,牢牢占据领先行业的技术与产品生态位。
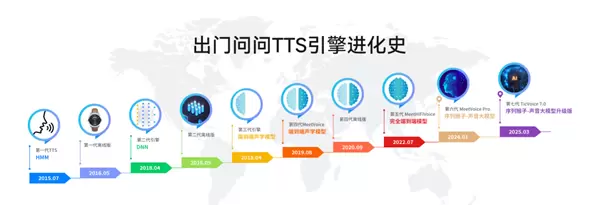
近日,出门问问联合国内外顶尖的学术研究机构香港科技大学、上海交通大学、南洋理工大学、西北工业大学,开源了新一代语音生成模型Spark-TTS,并发布于开源社区SparkAudio。

模型一经发布,便迅速登上Hugging Face 趋势榜 TTS 前二名,且增长势头强劲。而伴随着相关论文的发布,Spark-TTS 再次点燃学术圈的热情。

Spark-TTS 或者说 TicVoice 7.0 何以引发如此重大反响? 最重要的原因在于,它为行业带来了全新的语音编码范式,且实现了建模结构与文本LLMs 结构的高度统一:
直击主流语音token 痛点
TicVoice 7.0和Spark-TTS提出了一种全新的语音编码方式,可有效解决主流语音离散编码存在的两大核心问题:
单码本的语义token 需要经过多个阶段才能生成声学特征,在大语言模型的自回归建模过程中,难以对音色等属性进行精准控制。
声学编码通常依赖多个码本,导致模型设计复杂化,同时缺乏与语义的强关联性,增加了预测的不确定性和难度。
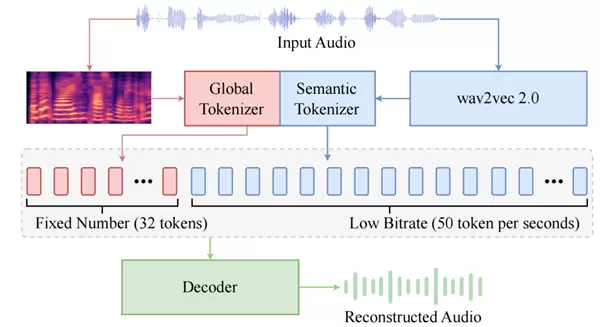
BiCodec示意图
如图所示,BiCodec 将输入语音编码为互补的两部分,即固定序列长度的Global Token和低码率的Semantic Tokens(50 TPS, token per second):
Global Token负责建模时序无关的全局特征(如音色),确保语音生成的全局可控性。
Semantic Tokens以wav2vec 2.0 提取的特征为输入,编码与文本紧密相关的信息,确保语义的强相关性。
这种设计使BiCodec既能利用Semantic Tokens 的低码率和强语义关联性,同时又能在自回归语言模型中实现对音色等属性的精准控制,兼顾高效性与可控性。
实现建模结构与文本LLMs 结构的高度统一
BiCodec 采用全离散、单流的编码方式,使语音 token 的建模与文本 token 的建模完全统一:
统一的模型结构:Spark-TTS直接复用 Qwen2.5 的原生架构,并扩展其 Tokenizer 以支持语音相关 token,使 Spark-TTS 的建模方式与文本建模高度一致。
属性控制:通过引入属性标签(如性别、基频等级)和细粒度属性值(如精确基频),Spark-TTS 以文本+属性标签为输入,采用链式思考(CoT, Chain of Thought)的方式,依次预测细粒度属性值 → Global Tokens → Semantic Tokens,从而实现音色生成高度可控。
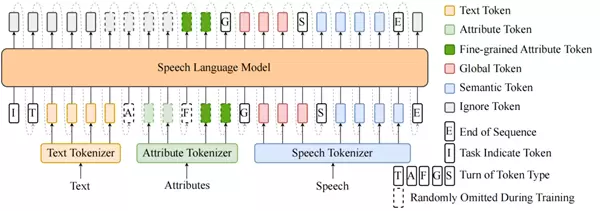
Spark-TTS的语言模型示意图
再度刷新行业语音克隆能力标准,极大提升用户体验
TicVoice 7.0展现出卓越的语音克隆能力,尤其在跨语言声音克隆方面表现出色。我们分别将其与出门问问上一代产品MeetVoice Pro及国内外优秀的同类产品做了评测,发现TicVoice 7.0在“3秒克隆”和“至臻Pro-精品发音人”方面领先优势明显。
让AI “说人话”,大大提升情感表现力
TicVoice 7.0能够在3秒内敏锐地捕捉声纹特征,让AI不仅能“说人话”,更能模仿人类的叹息、停顿。相比上一代的语音大模型,TicVoice 7.0的效果得到全面提升,3秒克隆经评测,其国际通用 MOS 评分从 3.9 提升至 4.2。其在音色相似度、情感表现以及稳定性上都有近10%的提升。总体而言,新一代语音大模型在听感上更自然、更悦耳、更稳定、情感表现力更强,可有效提升用户在客服、情感直播、有声书等场景的体验。
个性化定制更加精准,轻松获得播音级配音体验
TicVoice 7.0支持用户通过调整性别、语速、基频等多种属性(即将上线),精准塑造独特的声音风格。尤其在“至臻 Pro-精品发音人”定制方面,用户可通过 20-200句语料获得获得播音级的专业配音体验。
相比上一代的语音大模型,TicVoice 7.0在国际通用MOS 分数上从4.3 提升至 4.7。这意味着语音生成效果非常自然的,语音达到了广播级水平,普通人很难区分合成语音和广播语音的区别。总体而言,新一代语音大模型的语音更加清晰流畅、悦耳动听、容易理解、易于接受,可真正应用于影视/游戏角色配音等场景,为定制用户带来专业级体验。
TicVoice 7.0的发布不仅标志着出门问问在人工智能语音生成领域的又一次重大突破,更通过开源生态与产学研深度协同,为行业发展注入了新动能。
未来,出门问问将持续深化与顶尖学术机构的合作,不断提升用户的产品体验,探索语音生成技术与多模态AI 的融合边界,从“听得懂”到“听得真”,从“能表达”到“有情感”,让 AI 真正成为人类情感与智慧的延伸。
相关文章
- 出门问问携TicNote亮相全球共享发展行动论坛
- 出门问问首发AI原生协作平台CodeBanana,以《超级组织》重写AI时代的进化法则
- 出门问问向AI原生组织转型,Token消耗成本占人力15%
- 出门问问2025年亏损收窄90.5%,AI驱动组织效能量级跃迁
- 出门问问发布全球首款4G AI录音耳机 TicNote Pods,联合Alpha派推出金融投研版“涨听”
- 超越记录,打造协作新生态|出门问问TicNote系列新品亮相CES 2026
- 驱动AI原生组织进化!出门问问发布TicNote Cloud平台及系列AI硬件
- CES 2026|出门问问发布TicNote系列新品,联动TicNote Cloud打造团队协作新生态
- 搭载全新升级Shadow AI 2.0,出门问问打造TicNote硬件矩阵与协作生态
- 出门问问全新TicNote生态即将亮相CES,驱动AI原生组织发展
- 出门问问重磅发布TicNote Pods,“4G联网+Shadow AI”重塑耳机体验
- 出门问问发布TicNote Lite青春版,打造年轻人的AI思考伙伴
- 出门问问重磅发布TicNote Color系列,Shadow AI 2.0全面升级
- 穿越周期:出门问问“软硬结合”战略步入收获期,中期亏损近乎清零
- 出门问问TicNote销量居录音同品类热卖榜第一名
- 当AI学会主动思考:WAIC现场,出门问问TicNote让记录“活”起来
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


