从“治不好”到“不用治”: 瓴羊Dataphin的数据治理AI破局之道
2025-03-17 16:31:19AI云资讯4277
当前,AI技术的爆发式增长正在倒逼企业重新审视数据治理的价值——当业务部门期待用数据驱动决策时,却常因“指标口径不统一”、“数据血缘不透明”陷入内耗;当技术团队投入重金训练模型时,又可能因基础数据质量缺陷导致AI应用事倍功半。
AI时代,如何让数据治理从“成本中心”蜕变为“业务引擎”?
在3月7日「数据荟」Meet Up上海站中,瓴羊Dataphin高级技术专家周鑫指出:“数据治理实施的最大困难,在于整个治理过程抓的点太多。”这一论断揭示了行业共性困局:企业往往在多个治理模块中疲于奔命,却因缺乏核心抓手难以形成持续价值。对此,企业如何破局?阿里云智能集团瓴羊高级技术专家周鑫提出 “以数据标准为中心,贯穿数据全生命周期”,强调以标准化重构治理链路,让数据真正成为业务增长的燃料。
数据治理的 “定海神针”:为什么标准是破局关键?
从实施链路来看,数据治理为何如此困难?
大部分企业进行数据治理时,往往经历评估现状、制定目标、执行计划、持续监控四个步骤,在如此漫长的链路中,既要考虑数据质量、数据质量、数据安全或生命周期,还要在保持较低成本的同时,照顾到整个组织架构,需求不可谓不繁琐。周鑫表示,“传统治理步骤面临四大问题:缺少简单易用的实施方法、治理链路复杂、工具支撑不足、难以持续治理。”

正是这一困境,导致企业在实施阶段很容易偏离中心,缺少一个核心抓手。即使艰难完成治理,后续迭代也非常困难,一个目标的改动,可能牵一发而动全身,造成数据安全与质量规则的反复调整,大大拖慢了治理进度。
因此,问题的关键,是找到数据治理的核心——数据标准。
近年来,国家频频颁布数据标准相关政策规范,从《“数据要素x”三年行动计划》到国家数据标准体系,再到全国数据标准化技术委员会,都印证了数据标准的重要位置。
“当企业把数据标准定下来的时候,治理工作已经做了很大一部分了”,周鑫表示,以瓴羊Dataphin为例,企业完成业务与数据盘点,并将数据纳入数据元中心后,即可在Dataphin梳理数据标准。数据标准的建立不仅贯穿数据建模、研发等事前环节,还能通过生成质量规则和安全识别、分类分级等功能,实现对数据事中及事后的全面管控。
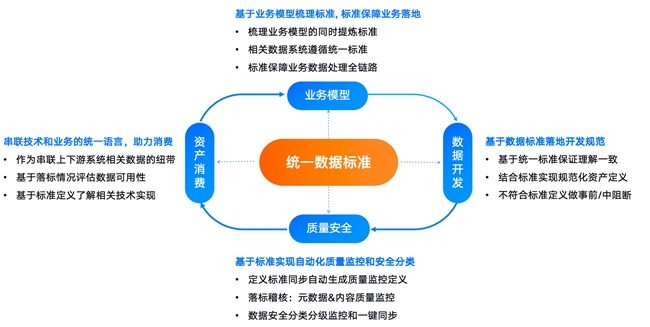
如此一来,用户在落标时,只需关心那些没有满足标准的数据即可。例如,在手机号的标准设置中,系统会根据用户设定的属性要求,自动生成一系列质量校验规则,确保相关字段数据符合标准;在访问权限上也会自动匹配审批流程,帮助快速识别和处理不合规的数据。这使数据标准的满足度与落标情况,成为衡量数据质量优劣的“晴雨表”,数据满足度越高,数据质量也就越好。
AI驱动的主动治理:从“人找数据”到“数据找人”
AI时代奔迅而至,激活了数据治理的一池春水。在AI技术爆发式增长的当下,数据治理的机会在哪里?
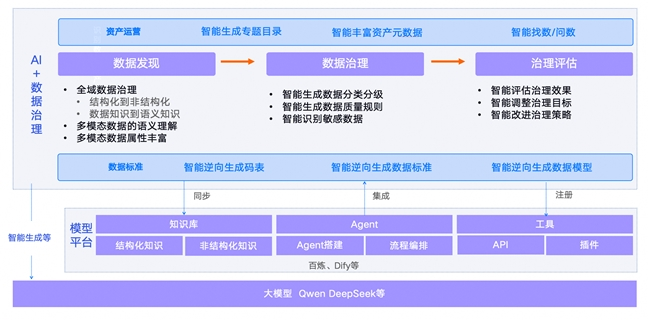
周鑫认为,通过AI+数据治理的结合,可以实现完整的主动数据治理。
首先,在数据标准阶段,通过AI逆向生成码表、数据标准以及数据模型可以很大程度地降低从业务到标准、到模型的实施成本。其次,在AI时代,数据从结构化到非结构化、从数据知识到语义知识的变化,通过丰富语义知识能促进AI的成功,企业可借助AI自动构建质量规则,实现分类分级和特征识别,管控数据整个生命周期,在数据治理结束后,AI还可自动识别治理效果,提供治理策略指引,形成数据治理的良性内循环。 最后,在资产运营阶段,通过和AI的结合,自动生成专题目录,智能丰富资产元数据和智能找数问数,帮助企业低成本的管理和使用数据资产。
Dataphin的治理实践:让数据资产“主动适配”业务需求
“我是电商业务负责人,今年大促目标是GMV提升20%,数据能帮我做什么?”
“我正在准备做运营外投,对于圈选母婴群,希望从数据上结合知识库,有什么建议?”
“我是产品运营,我想了解产品的销量指标定义是什么?”
……
在AI的助力下,以上数据资产应用问题,都可以通过对话的方式得到回应。
而承载这一功能的平台,便是智能小D。
“智能小D能够通过业务问题直接定位数据资产,例如当问它'如何进行客户分层?'时,基于思路策略,寻找提供对应的数字资产表”,周鑫表示,智能小D基于Dataphin打造,由阿里云百炼平台和开源Dify提供支持,核心功能聚焦于知识管理,尤其擅长数据知识的梳理和应用。未来,智能小D将进一步支持非结构化知识和智能体管理,用户还可通过挂载自定义智能体,实现智能体的个性化定义与功能拓展。
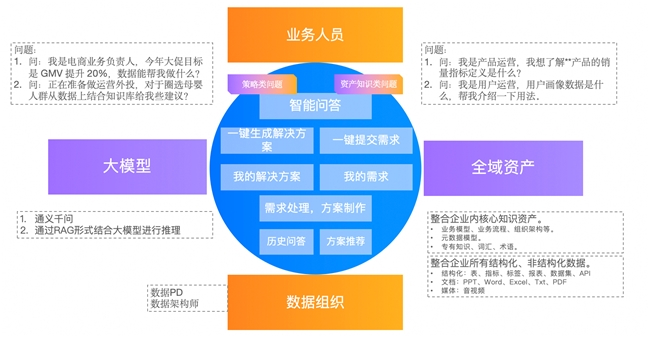
借助智能小D,用户可以直接询问具体的业务需求,如“我要找客户表”、“我要做客户分层,需要那些表?”、“销量下降明显,可能的原因有哪些?”等,大模型将根据用户需求,通过分解、联想等方式,为其快速提供对应的数据资产表,让用户无需BI分析师的专业技能,也能实现轻松读数。
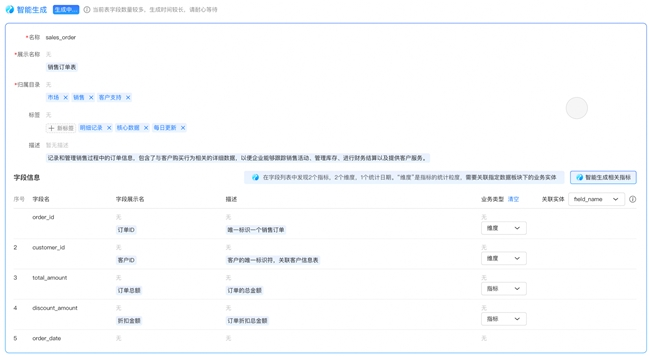
除此之外,Dataphin还在属性丰富方面引入了AI能力,简化了数据上架的流程。以往,一张表上架到目录,需要历经以下几个步骤:针对上百个字段,逐一描述其名称与含义;熟知运营方目录,制定便于搜索的标签;若过程中发现新增指标需求,还需返回重新填写目录和标签。
“比如500个字段、大宽表的情况下,操作下来至少需要半小时,而结合我们的AI能力,整个资产上架的过程能得到极大的提效”,周鑫表示,Dataphin可以帮用户智能生成所有描述,规划所有目录,自动识别潜在指标,待用户确认无误后,即可一键上架,几十秒即可完成所有资产上架工作。
在特征识别方面,Dataphin通过引入AI能力,降低了识别门槛,加快了识别速度。例如,在进行身份字段设置时,传统方法需要编写SQL能够识别的正则表达式,性别识别还需顾及成千上万张资产表复杂的表达方式,很难一次性枚举种种条件。引入AI能力后,Dataphin即可以自动生成所有的正则表达式,几十秒内即可完成一次特征识别。
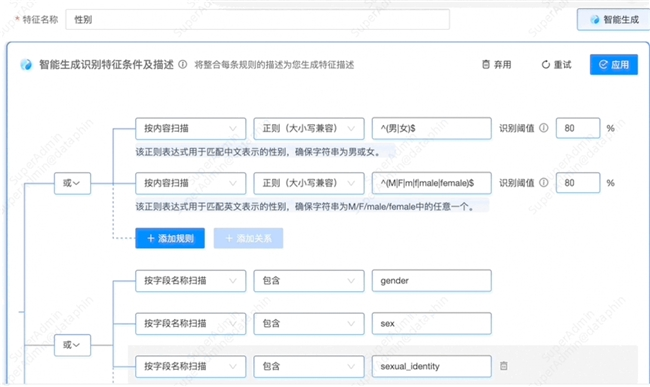
在数据治理与AI融合的远期规划中,周鑫提出 "迈向智能化最大的标识自助治理,是通过AI能力,基于业务变化自动调整治理目标、策略,最终调整业务动作" 。面对海量数据质量参差、治理链路冗长的挑战,周鑫指出 "从小的业务、领域切入,通过将问题求解集合缩小到特定领域,加快提升数据质量。”这一实践路径的核心在于,初期在有限业务圈内优化数据质量与Agent能力,同步注入行业知识库与业务逻辑,以渐进式迭代实现治理闭环。
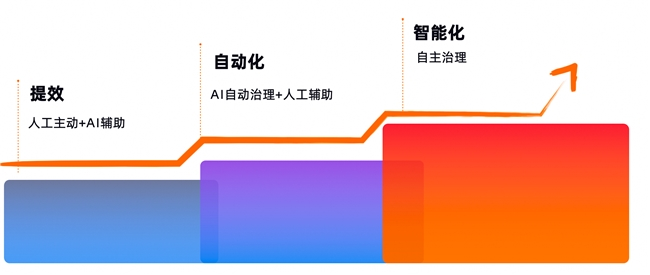
周鑫指出,目前Dataphin的数据治理AI计划正处于提效阶段。在这一阶段,Dataphin将进一步引入更多行业和业务知识,增强对非结构化数据的理解能力,并辅助生成质量规则。随着提效阶段的完成,数据治理将迈入自动化阶段,平台将实现质量规则的自动生成、分类分级的自动处理,以及敏感数据的自动识别等功能。最终,在更高阶的智能化阶段,Dataphin将基于对业务流程的深度理解,实现系统自动生成数据标准,全面提升数据治理的智能化水平。
正如《大数据之路2》书中所言,当数据标准贯穿全生命周期,治理动作无缝融入业务流时,企业才能真正将数据资源转化为驱动业务增长的"活水",实现从“数据支撑”到“数据驱动”的质变。
未来,瓴羊将持续深化AI与数据治理的融合创新,助力企业深化数据智能应用,高效构筑企业洞察市场、优化策略、提升竞争力的宝贵资产。
相关文章
- 友好跃迁 智算无界丨科华数据慧云8.0新品正式发布!
- SpaceX AI1发布背后:太空超算/数据中心正从概念走向工程现实
- 擎策·知海全球专利数据库升级:四个更新,让检索少绕弯
- 苏州新添长三角规模领先的无本体数据采训中心
- 华为云GaussDB:三大硬核方案直击数据库升级痛点,以数智创新构筑金融业坚实数据根基
- Adjust MCP 服务器:连接 Adjust 数据与您的 AI 工作流
- 华为云空间Cloud Kit全新升级:开放Web端与云图库接入,赋能全场景数据协同
- 宏杉MCloud:秒级CDP强势护航,无惧数据丢失,业务即刻恢复
- 知乎2026高考季:高考数据通焕新上线,真人经验分享为考生答疑解惑
- 数智普惠 一步到位 | 华为极简全闪数据中心2.0存储商业峰会-暨大附一院样板点发布会成功举办
- 共赴「芯」征程 | 科华数据x沐曦,以液冷技术协同推动国产芯片生态创新发展
- 金仓数据库助力北京某大型公共服务核心系统完成国产替换
- 数据中心耗电远超电网负荷,迫使英伟达与谷歌在2026年第三季度前启动800V直流电架构改造
- 数据要素进入AI时代:趣链科技布局“AI+Data”
- 火山引擎 “Data + AI“ 双轮驱动,打造面向 Agent 的企业数据新基建
- 上海移动携手月星环球港打造“数据要素×AI”商业新范式
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


