万字长文详解优图RAG技术
2025-08-28 18:01:54AI云资讯4810
在信息爆炸的时代,如何从海量数据中精准获取知识并生成智能回答,已成为AI落地的核心挑战。腾讯优图实验室凭借前沿的RAG体系,突破传统检索与生成的局限,打造了一套覆盖语义检索、结构化表检索、图检索的全栈解决方案。
本文将为你深度解析优图实验室RAG技术的架构设计与创新实践:从多阶段训练的2B级Embedding模型、Reranker分层蒸馏,到结构化表的智能解析与查询,再到自研GraphRAG框架在构图效率与复杂推理上的突破。目前,优图实验室自研的RAG技术已应用在多个领域和产品,未来,我们更将着力于迈向Agentic RAG与低成本精细化方向,推动产业智能化升级。
RAG技术架构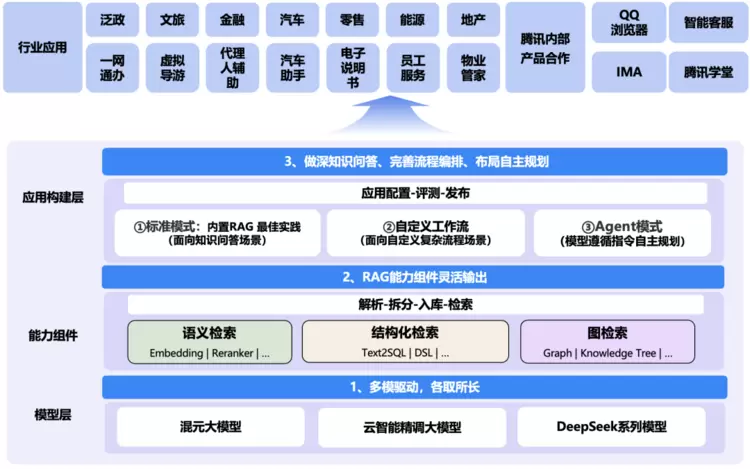
语义检索
1.1、Embedding模型
1.1.1、多阶段训练管线
为了提升基于大语言模型(LLM)的向量模型的检索能力,采用多阶段训练策略,逐步增强向量模型的泛化能力和检索效果。

图1.1. 训练管线概览图
弱监督对比学习训练。通过批次内负样本共享和跨设备负样本共享技术,每个查询文本对应多达6万个负样本,来极大增强向量模型的判别能力。
有监督对比学习训练。通过优化数据采样方法,使跨设备共享的负样本来源于同一个子数据集,来保证难负样本的质量和难度一致性,提升对比学习的有效性。在输入文本中加入特定任务的指令词,进行指令感知的对比学习,使模型能够根据不同任务调整语义匹配策略,来提升向量模型指令遵循的动态检索能力。
1.1.2、精细化数据工程
1.1.2.1、数据构造流程训练数据的规模和质量对向量模型的效果至关重要,一般地,构建对比学习训练数据的流程如下:
构建(问题,相关文档)的文本对。通常有两种方式,一是在网络上收集已经构建好的开源的问答对数据;二是利用大语言模型杰出的文本生成能力,为文档生成高质量的问题数据。通过收集开源数据和利用大语言模型合成数据,扩充了训练数据的规模,增加训练数据的多样性和丰富性,有助于提高向量模型的泛化能力。
挖掘难负样本,构建(问题,正样本,负样本)三元组。构建两千万规模的文本语料库用于难负样本挖掘,通过扩大语料库规模、构建特定行业语料库、利用大语言模型识别过滤假负样本的方法,优化了挖掘负样本的质量和效果。
1.1.2.2、数据质量控制
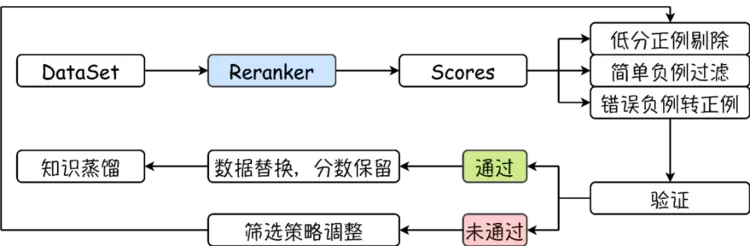
图1.2. 质量控制逻辑示意图
在上述内容基础上,借助 Reranker 模型对训练语料进行筛选及重组,以进一步提升数据质量。大致的处理逻辑包含以下三项:
剔除相关性分数极低的伪正例
基于相关性分布,过滤简单负样本
识别强负例挖掘过程中的潜在正样本,并进行替换
Reranker 模型的评分在通过验证后,会应用于编码器的更新过程,实现label层面的知识蒸馏。
1.1.3、多任务均衡配置
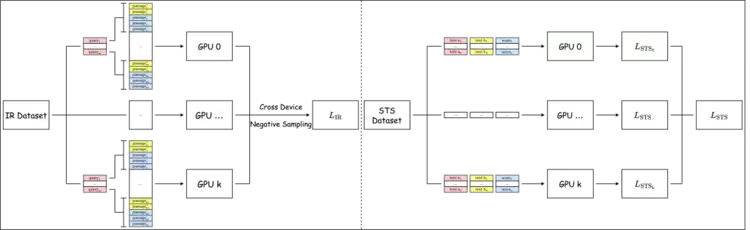
图3. 多任务跨GPU联合训练示意图
为充分发挥 Embedding 模型的潜力,解决不同任务属性、不同领域数据之间的冲突问题,我们设计了一套精密的联合训练方案:
数据统一化:依据数据在组织形式等方面的差异,将整体语料划分为 IR 和 STS 两大类,并采用统一的联调格式同时囊括二者,从而实现混合加载。
动态采样器:跨设备负采样是编码器微调过程中的常用技巧,但在多任务、多领域、多节点混合训练时,跨域数据的引入会为对比学习带来噪音,影响模型表现。对此,通过重构采样器和加载器,保证一次 iteration 中,多个 GPU 获取的样本严格出自同一数据集,并支持为它们设置差异化的 batch size 以充分平衡更新次数。
任务特定指令及损失:不同的检索及匹配任务拥有不同的领域特点及评价标准。相较于不加区分地对待全体数据,差异性的设置可以在最大程度上为参数更新过程注入先验知识。经过分析,我们针对 STS 和 IR 这两大类任务设计了不同的损失函数,同时支持配置个性化指令以灵活应对下游任务。在这种方式下,通过与采样器的联合作用,每个批次将提供纯粹的任务梯度,从而极大地避免强制适配时的潜在性能损失。
模型融合策略:以ModelSoups为代表的权重融合技术此前已被证实可以为CLIP等多模态模型带来提升,而这一方案同样适用于文本嵌入领域。在精调阶段结束后,通过选取不同训练轨迹得到的模型,并精心设置它们的融合方式及权重,进一步增强了网络在各项任务的表现。
1.1.4、任务定制损失损失函数是模型优化过程的目标及主要参照,对于神经网络的性能具有重要影响。良好的损失函数应充分贴近任务的评价指标,从而为模型提供有效指导。
具体到编码模型最主要的两类应用场景——文本语义相似性(STS)及信息检索(IR)。STS任务采用Spearman相关系数作为根本指标,该指标通过计算样本的预测排位与真实排位之差来衡量顺序一致性。IR任务的核心指标nDCG同样是list-wise式的,但它更强调高位优先性。鉴于在大部分IR任务中,与给定query相关的文档其实非常稀少,因此将这些正样本有效突出出来是提升模型表现的关键。
基于这两类任务的差异性和共通性,我们为STS任务引入了多种顺序性损失,希望模型从逆序对、分数差异性等角度对Embedding分布进行调整,以捕获细粒度的语义区别。对于IR任务,则会在采集充分多的负样本同时尽可能地扩大query和所有正样本之间的相似度分数,从而增强模型的判别能力。
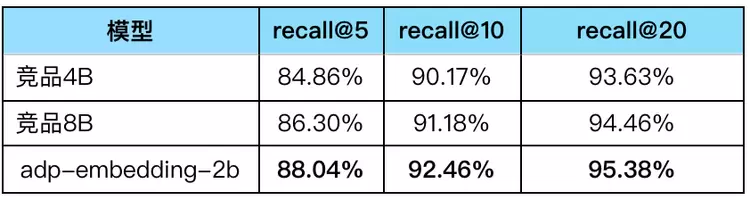
1.1.5、模型效果目前很多开源的Embedding模型在开源榜单测试集和业务侧测试集上的效果没法很好的平衡,往往顾此失彼。我们的apd-embedding-2b模型能够在这两种测试集上都达到比较好的效果。
我们验证了apd-embedding-2b模型在C-MTEB基准测试中的表现,在中文IR任务和中文STS任务上均取得了SOTA的结果。
中文IR任务

中文STS任务

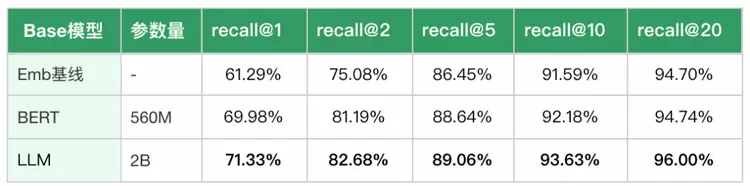
同时我们也在业务集上进行了实际测试,apd-embedding-2b以2B的参数量超越竞品4B、8B模型的效果,具体结果见下表:
1.2、Reranker模型
尽管向量模型的双编码器架构在实际的检索场景中计算效率高,耗时短,但它却无法直接捕捉查询文本和文档文本之间的微妙关联。为了提升检索环节召回文档的准确性,需要采用基于LLM的Reranker模型对向量模型的检索结果进行重排序。这种方式可以有效捕捉到查询文本和文档文本之间深层次的语义关联,从而给出更准确的检索结果。
1.2.1、Reranker模型升级为LLM模型传统的Reranker模型通常基于BERT、RoBERTa等模型进行训练,包括BGE-Reranker-large、Jina-Reranker等,其模型参数量相对较小(110M~400M),输入长度有限(512个token),对自然语言的理解能力远不及LLM。
为了提升Reranker模型在实际复杂场景中的表现,使用LLM训练Reranker模型成为必要方案。该方案能够有效发挥LLM对复杂问题和文档的理解能力,从而提供更高质量的文档检索结果,并且其所能支持的文本长度更长(达到8k甚至更长)。同时,通过对特殊任务添加指令,模型也能够适应不同场景的重排序需求。下表是在某业务数据上进行的评测:
1.2.2、分层知识蒸馏损失
对比学习损失是的Reranker模型训练时常用的损失函数,它的核心作用是帮助模型学习到区分相关和不相关查询-文档对的能力,从而有效地提升文档的排序质量。除此之外,知识蒸馏也是一种可用的训练策略。使用更强大的LLM作为教师模型,为查询-文档对给出更精确的相似度分数,然后约束Reranker模型输出和教师模型尽可能保持一致。这两种损失均有助于模型提升文档检索能力,通常可以两者搭配一起使用。
为了进一步发挥知识蒸馏的优势,我们对Reranker模型多个层级的Transformer的输出添加约束,构建分层(Layerwise)知识蒸馏损失。这种策略能够强化模型在不同深度层给出较一致的查询-文档相似度分数的能力,也称层级输出能力。如果训练数据中未提供教师模型给出的相似度分数,则可以用模型最后一层的输出状态作为知识蒸馏的监督信号,来约束之前的部分层输出和最后一层一致的状态,同样可以实现分层知识蒸馏。
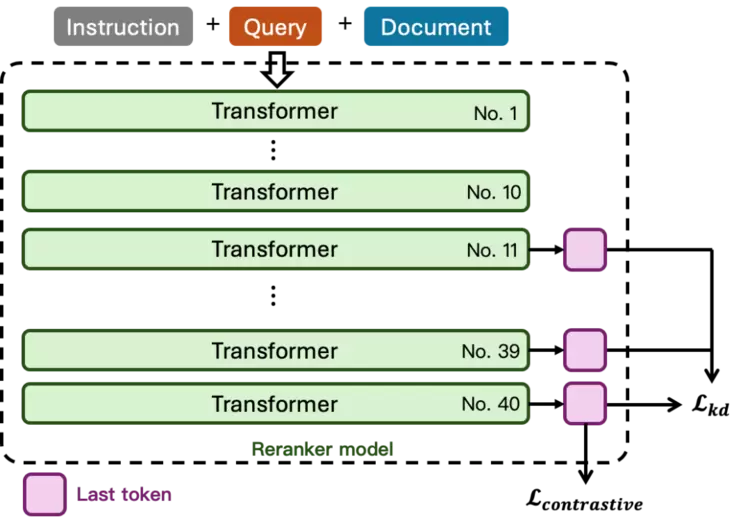
图1.4. 分层知识蒸馏损失策略
使用该策略训练的Reranker模型具备层级输出能力,允许用户选择模型不同层的输出来计算最终的相关性分数。这意味着用户可以选择使用模型较浅层或较深层的输出来进行重排序,这为检索效率和性能提供了更大的灵活性。通过选择合适的层,可以在性能和推理速度之间进行权衡。
1.2.3、高质量业务训练数据构造对于特定业务场景,通常缺乏领域适应的高质量训练数据用于Reranker模型的精调。对此,我们构建了一套高效的数据自动化构造流程,能够批量的清洗和构造高质量的训练数据。具体步骤如下:
Query预处理(可选):对于复杂问题,可以优先对问题进行拆解,用子问题(或原问题)借助向量模型进行第一阶段文档检索,同时检查Query的明确性和拆解的合理性,去除无效的Query
Query实体识别:对Query或子问题进行分析,识别其中所包含的有效实体,包括客观实体和时间实体,以此作为文档初筛的参考依据。
文档实体召回:对于步骤1中检索到的文档,使用LLM判断其中是否包含Query中存在的实体,并给出实体召回打分;客观实体和时间实体需要分别打分,0为无召回,1为全部召回。
文档初筛:根据实体召回结果,筛除实体召回打分均为0的文档,不参与下一阶段处理(这些文档可视为简单负例)
文档精评分:使用LLM对初筛后的文档结合Query一起给出相关性打分(这一步的文档数量将大幅度减少,提升精评分速度)
分数校准:对于打分后的文档,根据实体召回的评分重新校准分数;这一步能有效缓解模型在评分时产生的幻觉,纠正一些LLM的不合理判断。校准后的分数仅是针对单个Query的相对评分,只用于文档排序
自适应正负例筛选:
按照单个Query的分数分布选取正例,遵循“高分突出的情况下固定正例数量 <=10”和“高分均衡的情况下保持最大分均为正例”两个原则;
根据正例数量按固定比例确定负例数量,按分数从高到低依次补齐负例,尽可能保留难负例。
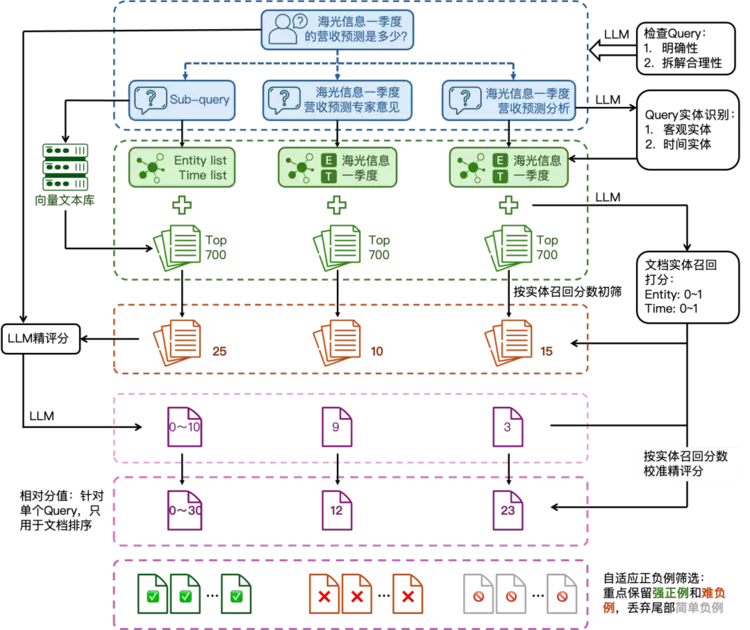
图1.5. 高相关性数据筛选流程
这套数据构造流程的优点在于:
通过实体召回对文档进行粗筛,能够有效降低精评分步骤需要处理的文档数量
通过实体召回打分对精评分进行矫正,能够有效避免LLM因为幻觉打出错误的高分或低分
自适应正负例采样策略保证了每个Query所构造的正负例文档都是高质量且分布比例均衡
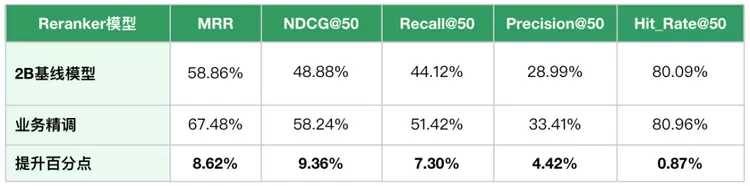
借助该数据构造流程,目前已针对业务场景进行了精调验证。根据业务评测报告,精调后的版本显著优于线上版本:
结构化信息检索
2.1、技术简介
在数据呈指数级增长的今天,企业内部积累了海量的信息数据,其中,结构化数据因其格式规整、语义明确,蕴含着巨大的商业价值。然而,如何让非技术人员也能轻松访问和分析这些数据,一直是业界的难题。
结构化数据:具有固定格式和明确语义,如数据库表格,便于计算机快速查询和处理。
非结构化数据:如文本文档、图片,无固定格式,语义理解难度大。
为应对结构化数据查询的挑战,我们基于经典RAG框架融合Text2SQL技术,通过“理解-检索-生成”的模式,将用户的自然语言问题高效转化为精准的数据结果。
2.2、方案总览
2.2.1、多源数据检索结构化数据常见数据源形态包括DB数据库表、表格文件等,业务上通过支持不同数据源的载入,设计了基于文本切片检索的RAG与Text2SQL融合的方案,将文本切片与text2sql查询结果送给下游阅读理解模型。阅读理解模型会综合两类信息,生成更准确、更全面的回答——既包含基于统计或字段的精确数据,也包含相关文本切片提供的上下文解释或补充信息。 整体检索问答方案如下:
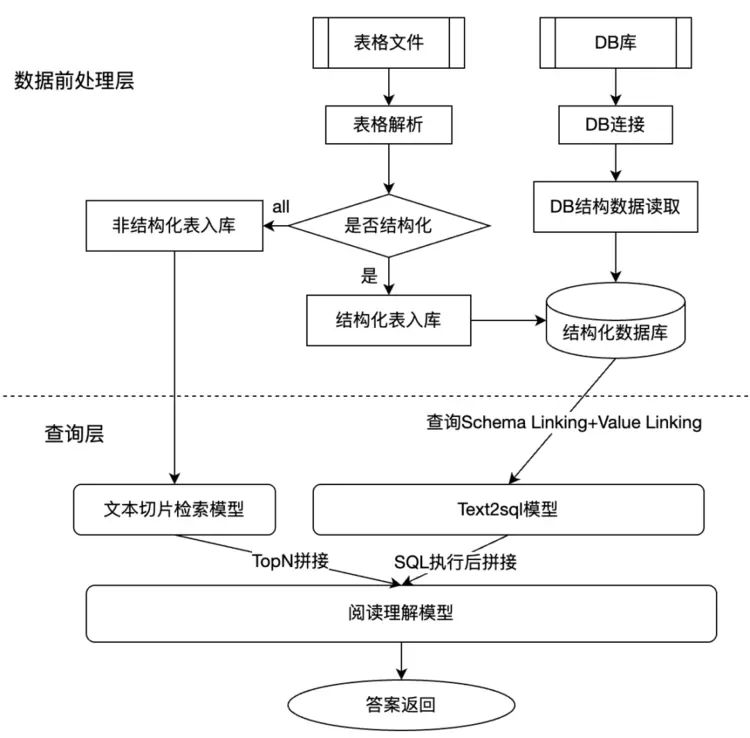
图2.1. 不同数据源载入问答系统
2.2.2、Text2SQL核心技术(1)自动化数据合成和增强数据合成对Text2SQL任务具有重要价值,主要体现在快速适配新场景和提升模型泛化能力两方面。通过自动化生成多语言的数据库表结构、自然语言问题及带推理过程的SQL答案对,系统能快速构建适配不同数据库方言(如SQLite、MySQL等)的训练数据。这种能力不仅显著降低人工标注成本,更重要的是使模型能预先学习到多样化的schema结构和查询逻辑,当面对真实业务中新出现的数据库范式或查询需求时,模型凭借合成数据训练获得的"经验"能更快实现性能收敛。特别是合成的"带思考过程的SQL答案"通过显式展现查询逻辑的构建路径,有效增强了模型对复杂查询的语义解析能力。
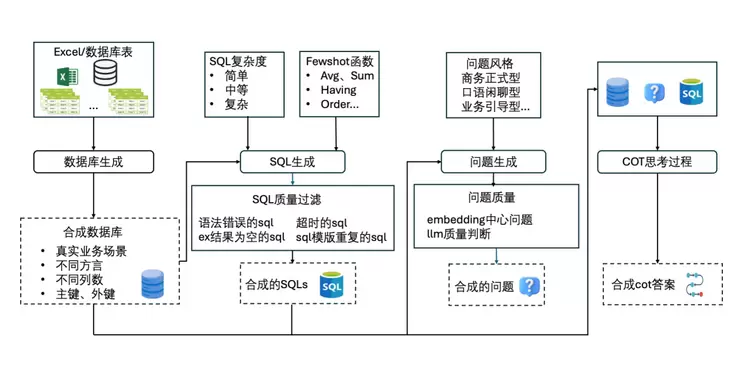
图2.2. 数据合成方法
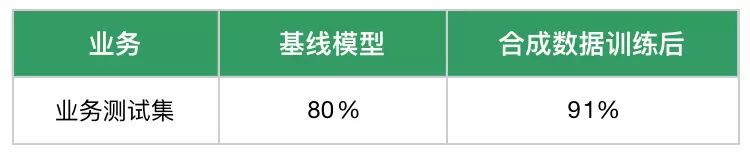
通过数据合成加训,对新场景提升效果如下:
(2)基于Agent的Text2SQL框架
Text2SQL 是一项将自然语言转换为SQL的技术,它允许用户通过日常语言与数据库交互,而不需要掌握专业的SQL语法。在实际业务中落地应用仍面临诸多挑战。例如领域知识的泛化能力,自然语言表达的多样性与复杂性,语义不明确、不完整等。
我们提出基于大语言模型的多智能体(Multi-Agent)协作框架,该框架由三个Agent组成:
筛选器(Selector):从众多表中选择相关表和列,减轻不相关信息的干扰;
分解器(Decomposer):将复杂的问题分解为子问题并逐步解决它们;
优化器(Refiner):使用外部工具执行SQL并获取反馈,根据反馈信息优化错误的SQL。
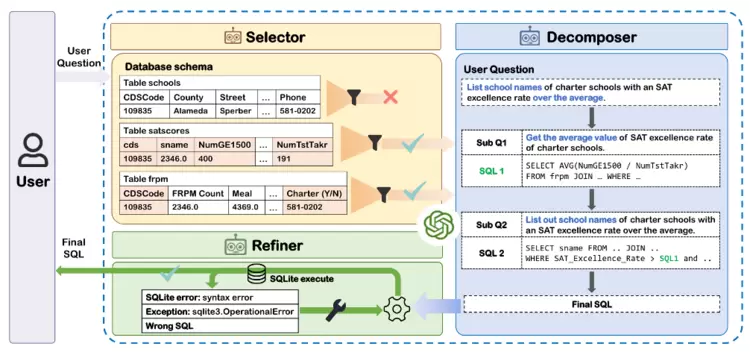
图2.3. MAC-SQL技术架构概览(中稿COLING 2025 [1])
基于开源BIRD和Spider数据集,本框架配合自研的7B模型,执行准确率超过ChatGPT-3.5等。本框架的方法配合 GPT-4 使用,能够达到SOTA的水平,远超单独直接使用GPT-4的效果。
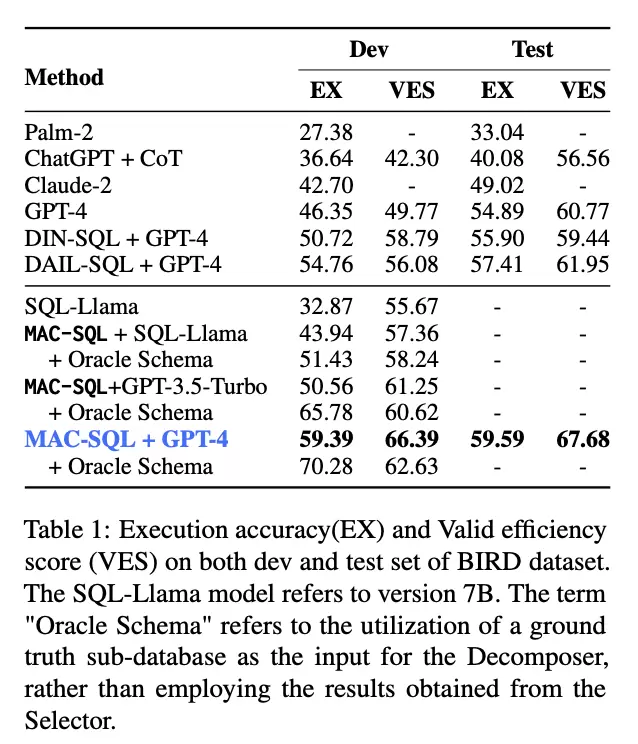
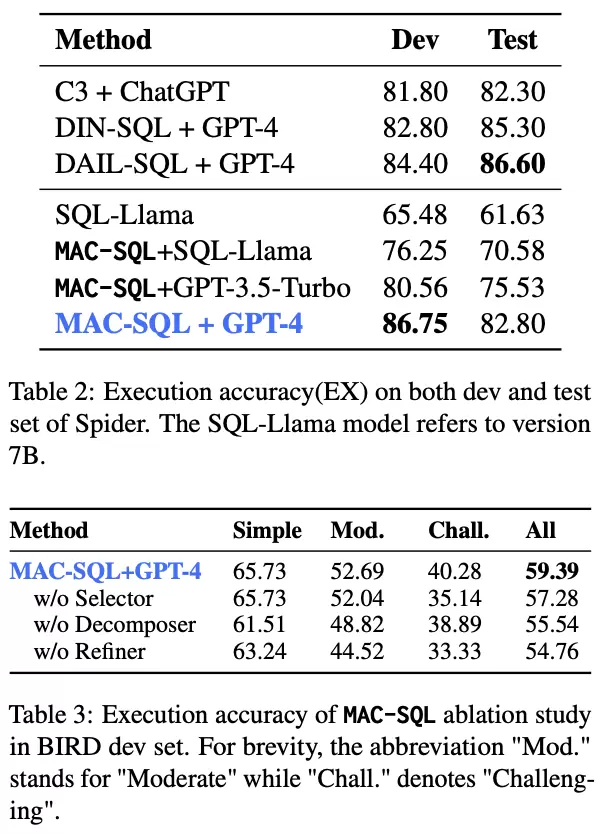
图2.4.效果对比
2.3、技术实践与优势2.3.1、表格文件场景(1)高精度结构化解析由于Text2SQL仅支持标准结构化表格,现实场景的表格文件会有许多非标准表格被排除在外。针对嵌套、合并等非标准情况,我们设计解析引擎-智能结构化识别方案,将原本非结构化表格自动转化为结构化表格。调用智能结构化解析,精度超过90%。主要阶段包括:
阶段①是否结构化知识表格判断
阶段②表头识别
阶段③将原表格元素识别结果提取整合为可被Text2SQL查询的结构化表
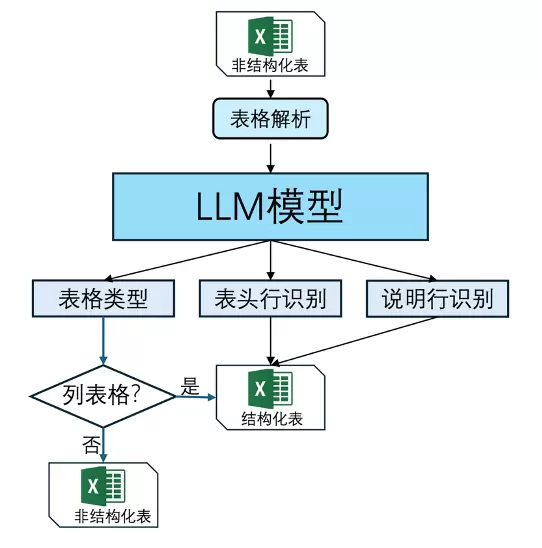
图2.5. 智能结构化解析流程示意
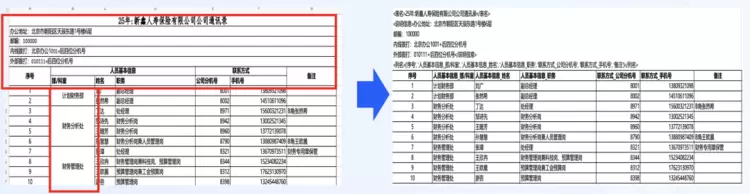
图2.6. 非结构化表格解析为结构化表格效果
(2)灵活语义窗口切分对于表格文件场景下的语义切片,支持可选窗口大小的切分策略,通过表头属性与表内容的组合,在保留语义的同时,允许灵活配置多粒度切分方法:

(3)双引擎SQL查询
将解析后的结构化表格数据存入Elasticsearch(ES)和MySQL,组成双引擎检索器。
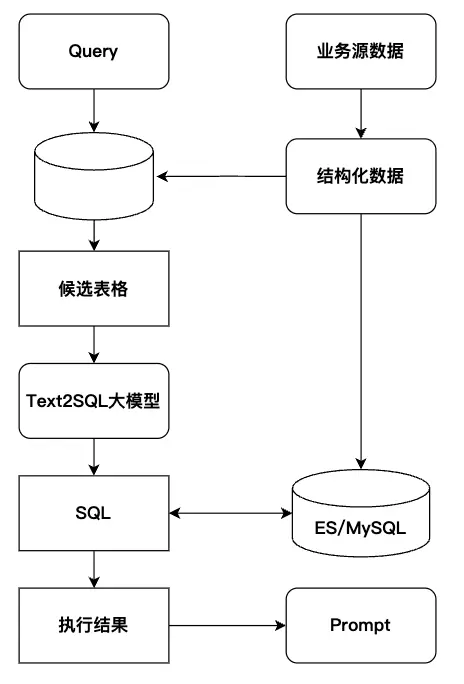
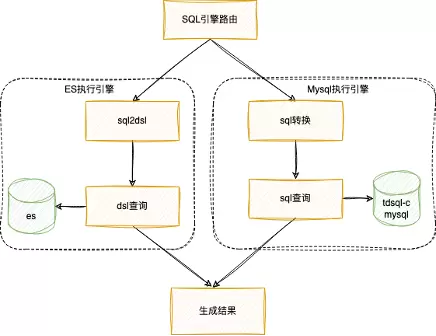
图2.7. SQL到ES/MySQL双执行引擎的路由
在双引擎检索架构中,ES弥补了MySQL在模糊查询和语义泛化上的局限性:
通过抽象语法树解析SQL语句可以实现语法校验与自动校正
抽象语法树(AST)是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
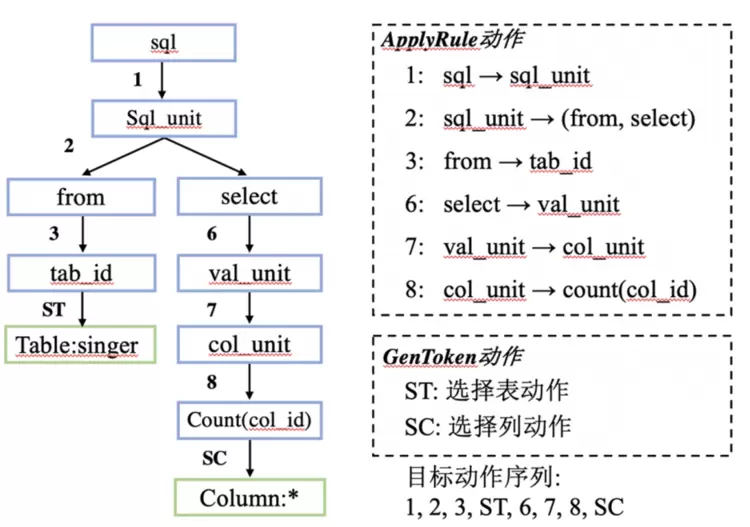
图2.8. SQL语句的AST及其动作序列 (相关技术中稿ACL findings 2023[4])
利用ES强大的全文检索能力处理模糊查询,提升检索召回
以某售卖场景为例,若按照问题中表述的售卖模式为'一次性售卖与租赁模式',MySQL直接查询执行结果为空;若使用ES泛化查询,则售卖模式模糊匹配可以找到'一次性售卖模式'和'租赁模式',该策略有效提升了SQL值匹配不准时查询的召回率。

性能提升验证
基于SQL的ES查询,首先将SQL语言通过AST解析,检查SQL语法的正确性,对语法错误的情况进行校正,然后可以通过方言转化将SQL AST转化为ES的DSL语法进行查询召回。双引擎表格查询的评估结果如下:

2.3.2、通用DB场景
(1)表拼接与链接针对Text2SQL的不同场景需要,提供DDL / SimpleDDL两种数据schema的提示词范式。
“DDL”(数据定义语言)包含标准化语言,其中包括定义数据库结构和属性的命令,提供创建数据库所需的详细信息,包括列类型和主键/外键。 相关信息输入健全,输入长,查询慢。
简化的 “SimpleDDL ”只提供表名和列名。相关信息输入简洁,输入短,查询快。

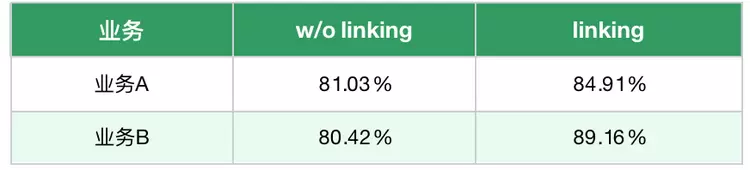
表链接引入语义向量,为大模型SQL生成提供可靠的依据:
Schema: 数据库的逻辑结构,描述数据的组织形式,包括表、字段、关系、约束等。定义数据如何存储、关联和验证。
例如:学生数据库 Schema 可能包含学生表(学号、姓名、年龄)和课程表(课程ID、课程名),并通过外键关联选课记录。
Schema Linking(模式链接): 指将Query与数据库模式(Schema)中的元素进行关联的过程。关注表和字段的映射(如 "学生" →student表)
Value Linking(值链接): 指将Query中的具体值(如数字、日期等)与数据库中的实际存储值进行匹配和关联的过程。确保查询条件(where)中的值能正确映射到数据库中的对应字段值。关注查询条件值的映射,如:
识别查询中的条件值(如 "年龄大于20" → age > 20)
处理模糊或非标准表达(如 "上个月" → date >= '2023-09-01')
匹配数据库存储的格式(如 "张伟" → 数据库可能存储为 '张伟' 或 'Zhang Wei')
处理同义词或缩写(如 "CS" → "Computer Science")
利用语义向量拼接提示语生成SQL,执行准确率结果如下:
(2)改写信号拆解与融合
为了将上下文改写信号更好的融入Text2SQL模型中,我们对复杂查询场景采用拆解策略,将复杂查询拆分为多个简单查询;对多轮交互场景采用基于编辑矩阵 (包含插入和替换操作)的改写信号表示方法,该编辑矩阵与表格-文本链接关系矩阵融合,一并融入到self-attention中。通过改写信号的拆解与融合,可以显著提升模型在SQL解析过程中对上下文语义的理解能力。
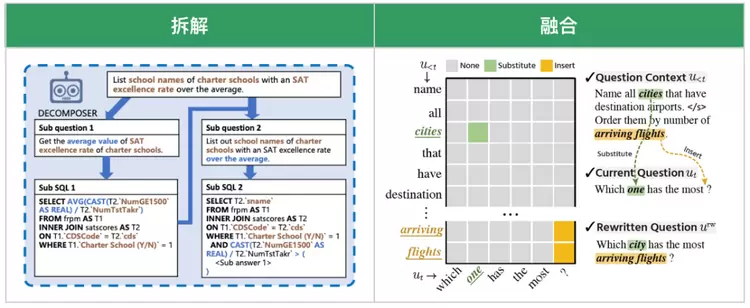
图2.9. 改写技术示意图(中稿EMNLP 2022 [2]、PRICAI 2023[3])
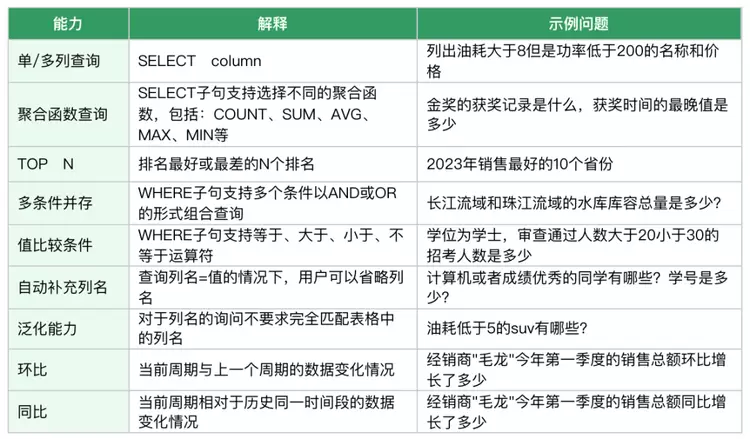
(3)SQL查询与计算Text2SQL技术作为连接自然语言与数据库查询的智能桥梁,能够准确捕捉用户查询意图,并将其映射为结构化的数据库操作指令,在保持语义完整性的同时严格遵循SQL语法规范。应用Text2SQL技术具有以下优势:①多维度查询支持 ②智能条件处理 ③语义理解与扩展
常见能力覆盖如下:
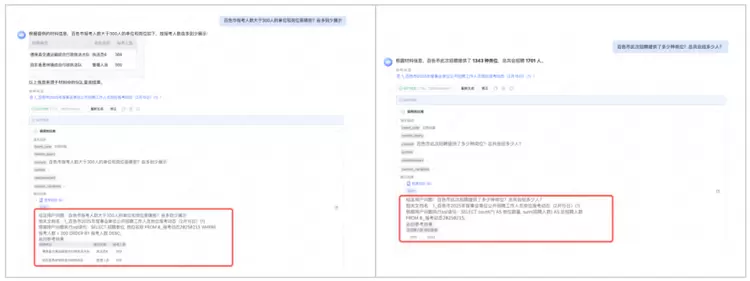
腾讯云智能体开发平台实践效果示例:
2.4、问答推理与润色
问答系统中通过阅读理解模型进行答案推理与润色,能够显著提升Text2SQL直接查询结果的可读性,同时实现以下优势:
(1)精准性与语义理解的统一Text2SQL可直接获取结构化数据中的关键字段或计算结果,确保查询的精确性。
文本切片检索提供语义层面的灵活匹配,丰富回答依据的信息量。
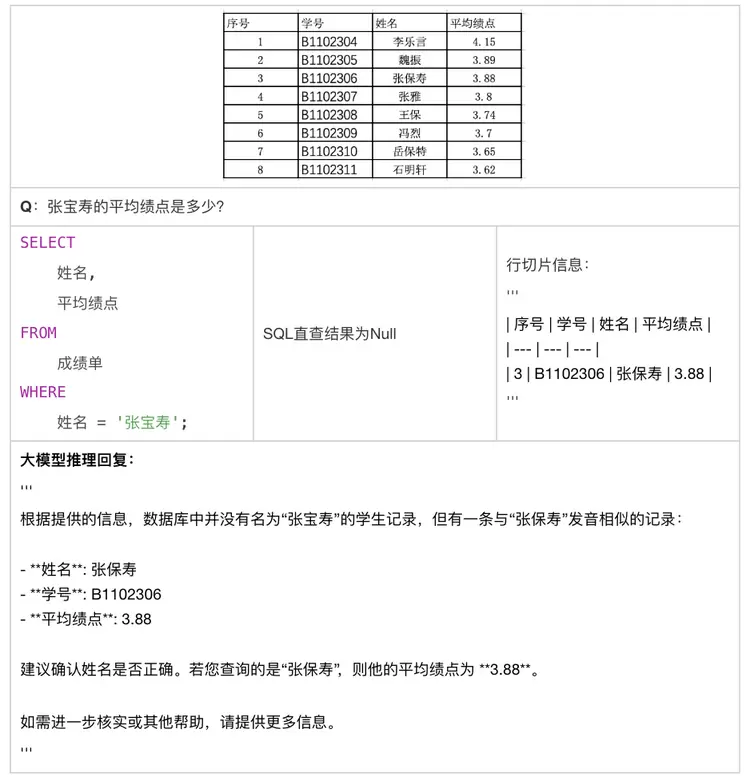
(2)复杂问题的高效处理
对于需要结合结构化查询与文本推理的复杂问题(如推理分析、趋势解读等),模型可同时利用:
数据库字段的精确查询结果。
关联问题的描述性内容。
生成兼具数据支撑与语义连贯的综合回答。
GraphRAG
3.1、自研GraphRAG-Benchmark
当前GraphRAG技术发展还处于初期阶段,业界缺少专门针对GraphRAG评测的规范数据集,同时缺少不同GraphRAG方法在相同benchmark下统一的效果评价方式,因此今年6月份优图发布了自研的GraphRAG benchmark[5][6]。
优图实验室GraphRAG-Bench在多个领域构建了不同类型的问题,构建了适合衡量GraphRAG效果的复杂推理数据,并提出了一套完备的效果评估流程。
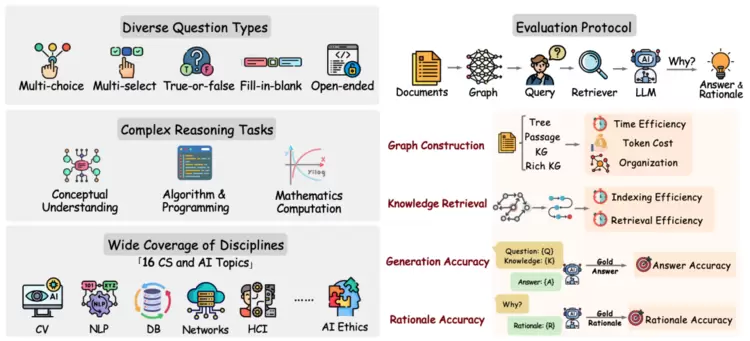
图3.1.GraphRAG-Bench构建逻辑及评测设计
在优图实验室的GraphRAG-Bench中,我们设计了四个维度来评价GraphRAG框架的质量,并对当前主流的GrphRAG框架进行了评测分析。四个维度分别是:
构图成本:构图成本主要评估从原始文本数据离线构建图谱过程中的时间和token消耗。在我们的测评中,HippoRAG、DALK,ToG,GFM-RAG四种方法在构建图谱的时间消耗相当,RAPTOR方法在图谱构建过程中token的消耗量具有显著优势。
检索效率:检索效率主要评估每次查询对图谱检索的平均时长,在9种方法中,RAPTOR因为主要依赖向量检索,速度最快;依赖GNN为代表的GFM-RAG框架速度达到秒级,以LightRAG为代表的图检索方法平均时长在十几秒级。
回复准确率:用于评估各个框架在不同类别的任务下,回答问题的准确性。经评测,GFM-RAG、GraphRAG、HippoRAG和Raptor方法平均准确率效果领先。
推理能力:所有GraphRAG方法显著提高了LLM的推理能力,增加了生成正确理由的概率。HippoRAG和RAPTOR在推理能力上表现最佳,这与它们检索有用信息的能力密切相关。
3.2、自研GraphRAG框架当前以知识图谱为主要知识组织形式的第一大类框架有 GraphRAG和LightRAG等,这类方法将知识粒度细化,但是缺点在于构图和检索的质量和效率偏低,难以在生产环境使用;
第二大类是树结构方案,代表框架有RAPTOR和E2GraphRAG等,这类方法通过层次化迭代对文本切片进行知识总结,但是构图和总结高度依赖大模型且无法挖掘细粒度知识之间的关系。
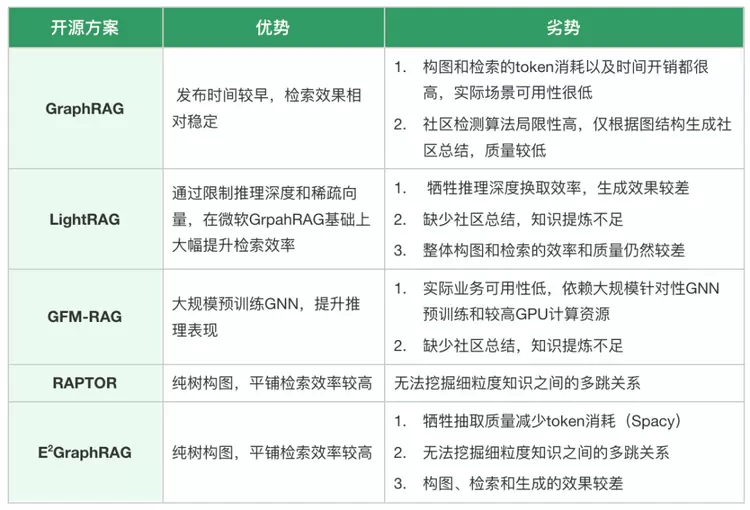
3.2.1、领域图谱构建的质量和效率提升
我们通过融入两类方法的优点,每个节点类型都有特定的功能和角色:实体和关系节点用于连接语义单元;属性节点用于表示实体的特征;社区节点用于总结社区的核心信息。这种异构图结构使得优图GraphRAG能够实现更细粒度的检索和理解,从而提高整体性能,形成效果和效率均更贴近落地可用的创新GraphRAG方案。
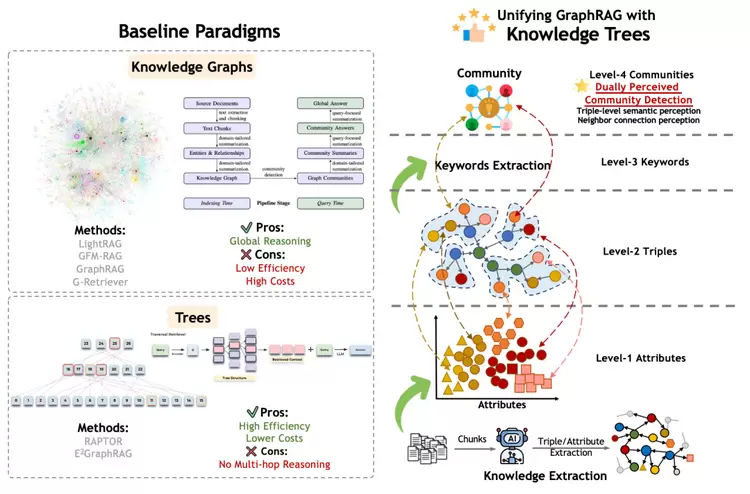
图3.2.Knowledge Tree与当前基于图/树的GraphRAG 方法对比及优势
(1)通过知识树对知识进行有效组织构建属性、知识图(三元组)、关键词、社区四级知识粒度的树型图谱结构,实现了对文本知识的精确多级整合,从效果和效率上超越现有图和树的两类方案;
同时保留了图的细粒度知识推理 和 树的层次化汇总摘要。
(2)对GraphRAG社区检测进行创新 S2Dual-perception
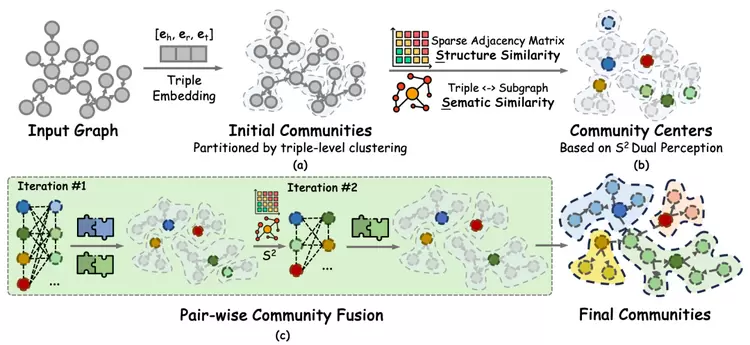
图3.3.通过稀疏邻接矩阵的结构感知以及子图语义相似度的语义感知提出的社区检测算法
现有的图社区检测SOTA算法Leiden存在如下问题:
强制按照连接性划分社区,过分依赖图构建质量,限制了推理发现和补全能力;
效率低下,全图遍历单个节点不断计算与当前社区合并后的质量函数后更新社区,不适用于大规模图数据。
为了解决这些缺陷,我们同时利用拓扑结构Structure和子图语义信息Semantics,生成更高质量的社区总结和发现,实现对结构化知识的高效组织,克服传统社区检测算法的局限性。
通过稀疏邻接矩阵计算Jaccard相似度量化锚节点与社区子图间的拓扑重合度,反映锚节点与候选社区中邻居间的连接强度;
编码锚节点的特征与候选社区的子图特征捕捉语义重合度,反映锚节点与候选社区子图的文本相似度。
(3)支持不同领域的图Schema结构自适应优化通过预置三大类的中英文领域图Schema包括人物、事件和概念中的实体类型、关系类型和属性类型+ 在构图时大模型的Schema信息补充,来自适应调整最合适特定领域的构图Schema,在保证特定领域抽取质量的同时减少人工干预。
3.2.2、优化复杂query的理解和推理领域内对复杂Query理解缺乏关注,现有baseline在Query查询过程中主要以文本切片和摘要的语义向量相似度进行直接检索,但复杂长难句Query的向量直接匹配效果较差,导致难以真正理解复杂多跳Query。
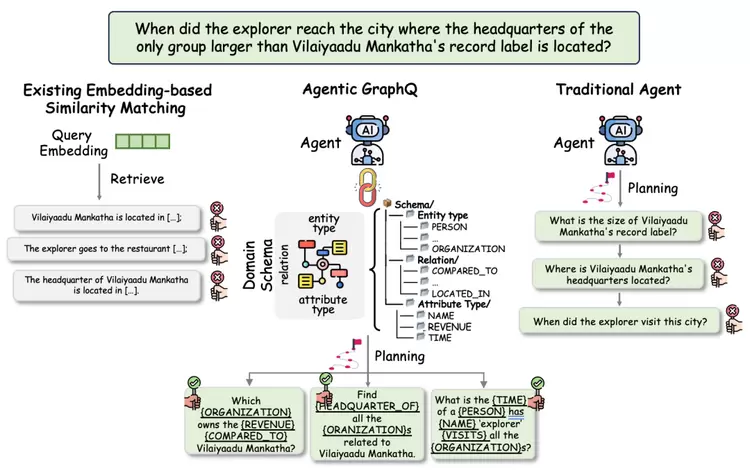
图3.4. Agentic GraphQ,基于图谱Schema进行复杂问题的针对性解耦
(1)复杂Query理解图Schema当前在AutoSchemaKG及优图GraphRAG的两个方法中被用于提升构图质量。针对复杂长难Query理解,我们首次提出将图Schema应用到Query理解和子任务解耦上,帮助模型对复杂多跳Query中的关键实体、关系和属性精准定位。
首次提出图谱Schema感知的复杂Query理解模块AgenticGraphQ。通过Agent对Schema的理解,挖掘Query中{Entity} / {Relation}/ {Attribute}之间的隐式关系和依存句法,实现多跳向单跳简化的子任务解耦;
基于Schema,结合Query理解和图谱推理,大幅度提升复杂Query的理解能力及关键实体、关系等重要信息的定位能力;
通过将Query简化,轻量推理即可完成解耦后的子任务,极大降低下游对推理模型的依赖,模型减重。
(2)高效多路检索主题词匹配或关键词检索;
采用Query-Triple的三元组向量匹配并对结果进行相关性剪枝,融入更多结构和语义信息,取代传统Query-Node的单一向量匹配方案;
基于路径的DFS邻居检索
3.2.3、框架效果
经实验对比,相比当前主流开源GraphRAG框架(如微软GraphRAG、LightRAG等),优图GraphRAG框架在构图成本和回答准确率上有大幅度的优化。
(1)构图成本在hotpotQA、2wiki和musique三个开源数据集上对比评测,优图GraphRAG的构图效率大幅提升。在社区检测上首次提出创新,相比当前社区检测的SOTA算法Leiden,效率提升近100%。
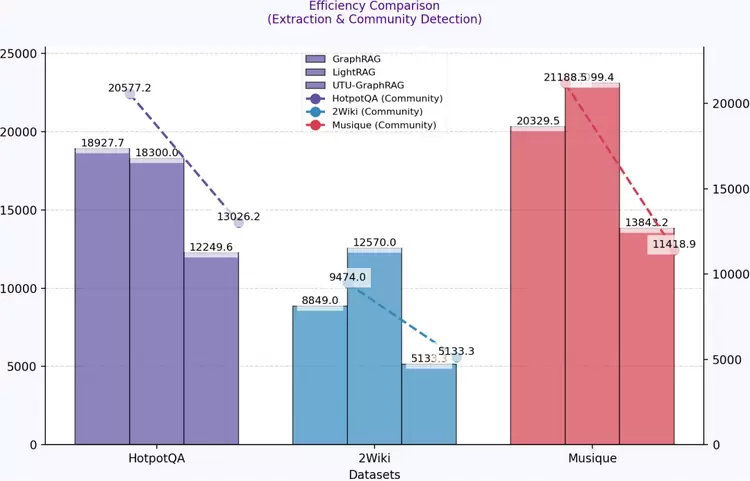
优图实验室GraphRAG的大模型调用成本显著降低。在hotpotQA数据集构图阶段,微软GraphRAG(Global)消耗token量为亿级,LightRAG构图token消耗量在千万级,优图GraphRAG在相同的数据上构图的大模型调用成本降低到百万级。
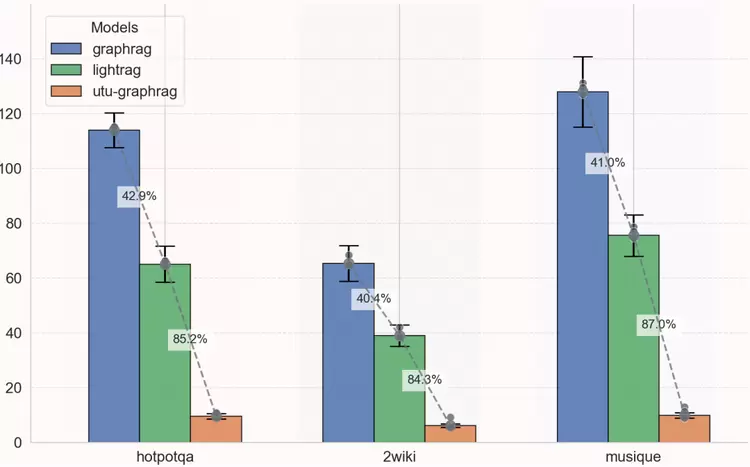
(2)检索效果提升
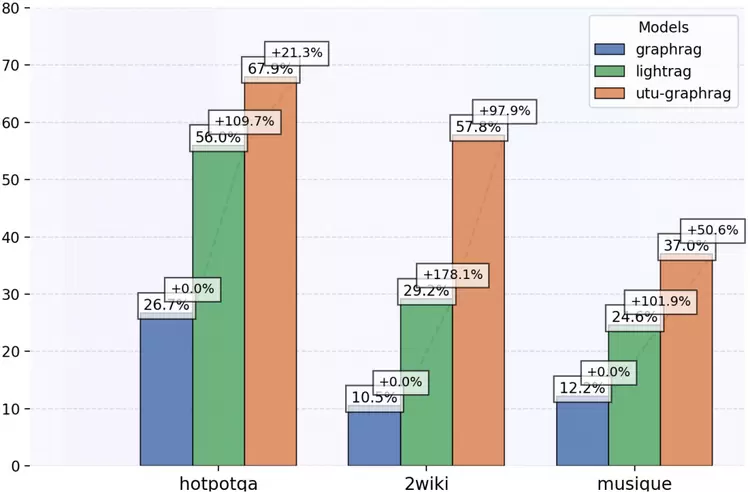
效果方面,优图实验室GraphRAG对比微软GraphRAG(Global) 提升200%+、对比LightRAG提升20%-100%,在GraphRAG专注的复杂数据集上效果提升显著。
 未来展望
未来展望
目前,我们的RAG技术已在汽车、文旅、泛政、金融等多个行业成功落地,深度助力腾讯云智能客服、QQ浏览器、IMA等腾讯内部产品。随着大语言模型和RAG技术的快速发展,我们也将持续打磨技术架构,提升原子能力效果,也将围绕Agentic RAG、精细化、低成本的趋势进一步实践:
(1)Agentic RAG:通过引入智能体技术,实现复杂问题的自动化分解和多步骤推理。结合动态规划、实时反馈和工具调用能力,提升系统在复杂场景下的推理准确性和解释性。
(2)精细化与低成本:以GraphRAG作为新兴技术的代表,在保障精细化知识管理优势的同时,重点优化构图成本和计算效率。通过动态增量式更新、轻量化建模等技术手段,降低部署门槛,使技术更普惠。
未来的RAG技术将不再局限于简单的“检索-生成”的线性流程,而是发展为“规划-决策-检索-验证-推理”一体化闭环智能系统。也期待更多业界伙伴与我们携手,共同探索RAG技术在更广泛场景的创新应用,推动产业智能化升级!
参考文献[1]MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL,COLING,2025.
[2]Cqr-sql: Conversational question reformulation enhanced context-dependent text-to-sql parsers,EMNLP,2022.
[3]QURG: Question rewriting guided context-dependent text-to-SQL semantic parsing,PRICAI,2023.
[4]G3R: A Graph-Guided Generate-and-Rerank Framework for Complex and Cross-domain Text-to-SQL Generation,ACL,2023.
[5]GraphRAG-Bench: Challenging Domain-Specific Reasoning for Evaluating Graph Retrieval-Augmented Generation, arxiv,2025.
[6]首个!腾讯优图联合香港理工大学发布为GraphRAG设计的评测基准+数据集
相关文章
- Interspeech 2025 | 腾讯优图实验室4篇论文入选,涵盖超声波活体检测、神经语音编解码、语音合成等方向
- ICCV 2025 | 腾讯优图实验室大模型8篇论文入选,涵盖风格化人脸识别、AI生成图像检测、多模态大语言模型等方向
- 最高10倍加速!北京大学联合腾讯优图实验室将 GQA 改造成 MLA形式
- ACL 2025 | 腾讯优图实验室大模型4篇论文入选,涵盖智能体、角色扮演、自动推理等方向
- 超越ControlNet!腾讯优图实验室联合复旦大学提出AI生图新框架,解决多条件生成难题
- 优图实验室:用AI驱动B端,推动产业智能化
- 腾讯优图实验室郑冶枫:科幻电影之外的脑机接口技术探索
- 腾讯优图实验室研发的跨年龄人脸识别技术,拯救了千万家庭
- 腾讯优图实验室获全球胸部多器官分割大赛SegTHOR三项冠军
- 对话腾讯优图实验室联合负责人:做技术的人不能躲在后端
- 践行科技向善,腾讯优图实验室发布两大AI+公益成果
- 腾讯CSIG:腾讯优图实验室AI手语识别研究白皮书
- 腾讯优图实验室专家写给2029的信:计算机视觉AI技术的爆点在哪里?
- 腾讯升级优图实验室,加大AI与视觉识别投入
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


