硬科技突围:一颗中国芯片,如何破解AI算力的“存储墙”难题?
2026-01-22 11:18:02AI云资讯2557
在全球人工智能竞赛进入白热化的今天,一股“寂静的洪流”正在算力底座深处涌动。当业界将绝大部分目光聚焦于GPU的算力峰值时,一个更为隐蔽却致命的瓶颈——“存储墙”——正严重制约着千亿级大模型的实际效能。特别是在推理场景中,为注意力机制服务的KV Cache,其巨大的容量需求与严苛的延迟要求,让无数高端GPU的算力在等待数据的过程中被悄然“闲置”。
近日,一家名为绿算技术的中国公司,发布了一款可能改变游戏规则的芯片产品,试图从系统架构的底层,为这道高墙打开一个缺口。
一场瞄准“黄金微秒”的精准狙击
“这不是一次简单的国产替代,而是一次针对AI负载的体系化重构。”绿算技术研发负责人向记者表示。他们推出的,是一款基于自主IP的NVMe over Fabrics桥接芯片(擎翼)原型。
NVMe-oF技术并非新概念,它本是数据中心实现存储资源池化、构建解耦架构的关键。然而,绿算技术的突破在于,首次将这项通用技术,深度锤炼为专为AI大模型KV Cache场景服务的“超高速数据通道”。
其核心目标极其明确:将GPU显存中“住不下”的KV Cache,卸载到由标准NVMe SSD构建的庞大存储池中,并且必须保证访问延迟足够低——低至20微秒以内。这个数字,是确保大模型能够流畅进行实时推理交互的关键阈值。
“业界过去要么选择昂贵到无法规模化的HBM显存扩容,要么忍受软件方案带来的上千微秒延迟。我们的目标,就是在性价比与性能之间,开辟出‘黄金微秒’这一最优路径。”该负责人解释道。
架构重塑:从“缓慢爬楼”到“数据高铁”
为实现这一目标,绿算技术选择了最艰难但最彻底的路径:全硬件卸载。
在传统方案中,一个来自网络的存储访问请求,需要经历网卡、CPU、内存、操作系统协议栈、多次数据拷贝,最后才能抵达SSD,过程如同在城市街道中多次换乘。
而在这颗芯片内部,设计团队构建了一条 “数据高铁”。通过自主设计的七大核心IP核协同工作——从网络包的物理层接收、RDMA协议解析,到NVMe命令转换,直至通过PCIe写入SSD——全部在硬件逻辑中一气呵成,无需CPU介入,实现了零拷贝传输。
尤为关键的是,芯片内集成了一个智能的预取与缓存管理引擎。它能够学习Transformer模型的注意力访问模式,主动预取数据,将看似随机的KV Cache访问,变得更为有序和高效。
实测数据背后的商业价值
根据绿算技术提供的在自研LightBoat 2300加速卡上的测试报告,该原型方案取得了令人瞩目的成绩:489万次4KB随机读取每秒的IOPS,以及高达21.8 GB/s(单卡双100Gbe)的顺序读取带宽。这几乎达到了理论峰值,在实际的业务场景它足以应对数百个并发请求对海量KV数据的随机抓取。

“擎翼”存储ASIC卸载芯片原型
更值得关注的是其能效表现。在提供极致性能的同时,芯片级典型功耗小于10瓦(设计目标)。对比动辄数百瓦的GPU,这一功耗几乎可以忽略不计,但对于构建绿色、集约化的超大规模智算中心而言,其乘数效应带来的电费节约将是天文数字。
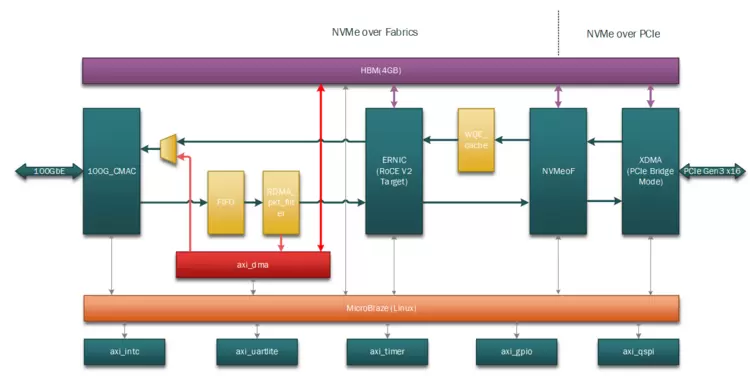
“擎翼”NVMe-oF ASIC芯片架构图
“我们的价值不仅在于单颗芯片的性能。”绿算技术市场总监指出,“在于它提供了一种革命性的成本结构。”他算了一笔账:使用该方案将KVCache扩展至TB级,其成本可能仅为单纯依靠顶级HBM显存扩容方案的十分之一甚至更低。这为AI公司在大规模部署千亿模型服务时,提供了至关重要的经济性保障。
生态与未来:能否撬动产业格局?
任何底层硬件的成功,都离不开与现有生态的融合。对此,绿算技术显得颇有信心。该芯片方案兼容英伟达GPU Direct Storage技术,并可被CUDA环境直接识别为标准NVMe设备。这意味着主流推理框架如vLLM、TensorRT-LLM等,理论上无需修改代码即可获得能力提升。
目前,该公司已与国内多家头部云厂商及大模型企业启动概念验证测试。行业观察人士认为,此类专用加速芯片的涌现,标志着AI算力竞争正从单一的“算力芯片竞赛”,演进到“系统级效率竞赛”。谁能从计算、存储、网络的协同优化中挤出更多性能、节约更多成本,谁就将在下一阶段的商业落地中占据主动。
绿算技术的这次尝试,无疑为国产AI基础设施的全栈创新提供了一个充满想象力的注脚。这颗小小的芯片,能否真正穿透“存储墙”,成为激活AI算力潜能的“关键一子”?市场和技术将共同给出答案。
相关文章
- 三星与马斯克再次联手,将基于4纳米制程打造第四代Neuralink芯片
- 清华系高温芯片独角兽谱析光晶:营收破2亿,创业板第四套标准打开资本化窗口
- 跨越感知瓶颈!单芯片8T8R毫米波雷达如何让机器人读懂复杂世界?
- 英伟达发布RTX Spark芯片,高调杀入PC市场
- 卡位星地融合赛道,星思半导体凭低轨卫星通信基带芯片领跑产业落地
- 比亚迪重磅发布中国首款4nm制程智驾芯片 布局高等级自动驾驶
- 墨芯人工智能完成C轮近十亿元融资,下一代芯片SparsePrime®年内推出
- 韩国AI芯片企业FuriosaAI下一代AI加速器采用2nm芯粒架构,支持HBM4/E内存
- RapidTDAS亮相AEIF2026,演绎车规芯片零缺陷智能解决方案
- 英伟达首席财务官调侃竞争对手因存储芯片短缺措手不及
- 星思半导体:以优质产品与领先技术,赋能中国5G RedCap芯片企业升级
- 星思半导体芯片:深耕商业航天赛道,解锁芯片企业发展新前景
- 思瑞浦 AI 数据中心全栈模拟芯片方案,构筑坚实智算根基
- 深耕核心创新技术,星思半导体推动5G RedCap芯片商业化落地
- 深耕5G/6G赛道,星思半导体彰显卫星通信芯片硬实力
- 芯启新程|亿海天剑®EQ6S7010高集成SoC芯片 全新面世
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


