DeepSeek最火Engram怎么跑?英特尔至强+AMX实测:性能提升达1.67倍!
2026-02-05 10:43:05AI云资讯2066

近期大模型领域里最火的热词,或者说技术创新点,非Engram (DeepSeek最新论文里设计的Engram机制) 莫属。今天我们想分享的,是英特尔围绕Engram开展的早期探索——用至强® 处理器独立运行整个Engram模块,并使用其内置的英特尔® AMX(高级矩阵扩展)技术对其进行加速的初步成果或收获。
我们希望这次分享,或能作为参考,或是作为开端,能为未来Engram以及集成它的大模型的部署和实践,拓展和探明更多可能性及随之而来的潜在应用优势。
Engram设计初衷:
让大模型走向“查算分离”
让我们先简单回顾Engram的源起,它出现在公众视野,是源自DeepSeek联合北京大学发布的论文《Conditional Memory via Scalable Lookup》。业界对它的评价,是为“破解万物皆推理”模式引发的大模型的记忆困境提供了全新思路。这里提到的记忆困境,指的是宝贵的算力被消耗在本可直接调取的静态知识检索上,这不仅会拖慢响应速度、增加推理成本,还让大模型在复杂任务上的性能突破陷入瓶颈。
该论文创新地在大模型中提出了“查算分离”理念,通过Engram引入外置记忆模块,将“静态、常见、局部”的知识从计算里解放出来,在拉升检索效率至O(1)复杂度的同时,也把宝贵的算力资源留给Transformer专心做上下文理解和推理。
Engram核心创新:
用“外置记忆模块”实现查算分离理念
Engram将“查算分离”落到实处的做法,就是把大模型里的“计算”和“超大规模记忆”解耦,Transformer的算子全部在GPU/加速卡上计算,而庞大的EngramEmbedding表放在CPU内存或高速存储设备上存查。如图1所示,GPU与CPU分工合作并通过异步方式协同,GPU执行前一步计算的同时,CPU可提前预取后续计算所需的N-gram Embedding表,当计算执行到“Transformer Block with Engram”时,所需的静态知识已经就位。
这种分工模式改变了传统大模型“推理既要计算又要记忆”的状态,就像给学者配备了一本可即时查阅的百科词典,无需每次都从头推导基础知识点,而是将精力集中在深度思考上。
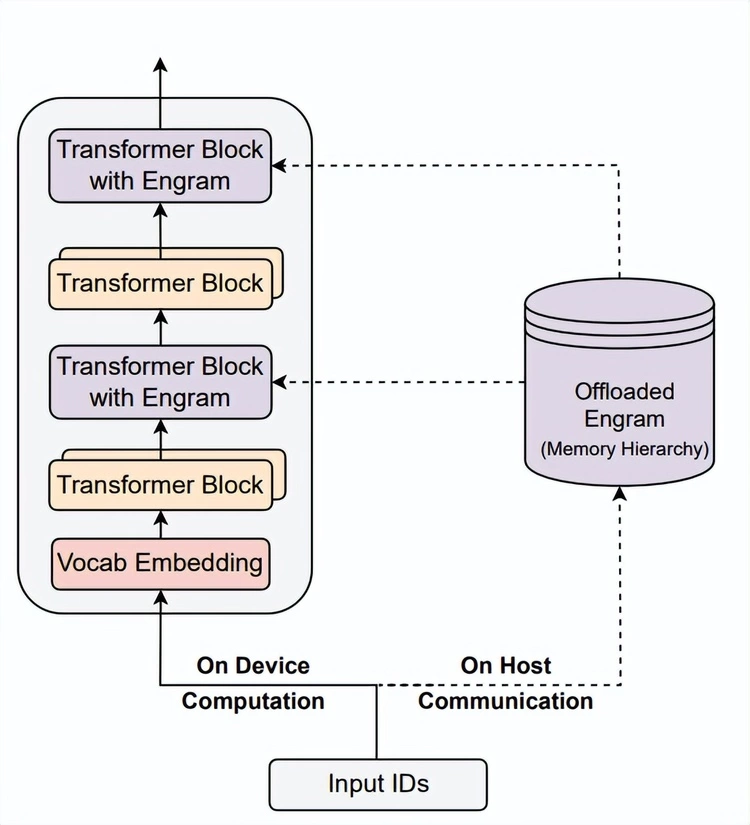
图1 大模型通过集成Engram实现查算分离
同时基于这一设计,Engram能充分利用CPU平台对大容量内存的有效支持,将“超大规模记忆”部分卸载至CPU平台上。论文数据提到:“将 1000 亿参数的表卸载至CPU内存时,仅产生可忽略的开销(小于 3%)。” 这表明,Engram 能有效突破GPU显存限制,为大规模参数扩展提供支持,从而为大模型用户带来显性收益。i
Engram计算流程解析
如图2所示,在Engram的计算架构中,其被嵌入Transformer主干网络,有以下几个主要工作阶段:
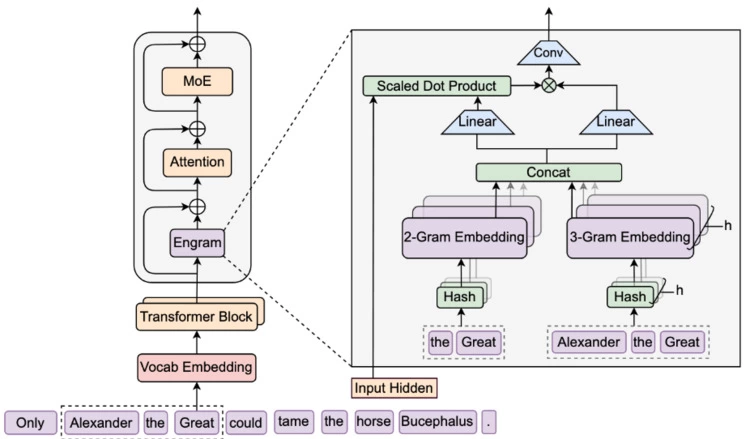
图2 Engram计算架构及核心工作流程
N-gram哈希检索阶段:模块对输入序列提取2-gram、3-gram等不同子序列(如图中的“the Great”、“Alexander the Great”),每个子序列对应其阶数的多头哈希机制,从预构建的静态N-gram 嵌入表(如图中的2-Gram Embedding、3-Gram Embedding表)中以O (1)复杂度查询对应嵌入。
动态门控融合阶段:N-gram嵌入表先经Concat(通道拼接)形成融合记忆向量,再通过两个Linear(线性转换)层分别投影为Key(记忆语义摘要)与Value(待注入信息)。随后将当前Transformer层的Input Hidden(全局上下文)与 Key 做 Scaled Dot Product (点积计算)生成门控权重,动态过滤与上下文无关的Value信息。加权后的Value再通过Conv卷积计算完成局部融合。
残差集成阶段:局部融合后的记忆特征通过加法操作,残差加回该Transformer Block的输入,并直接输入后续的Attention与MoE层。英特尔的探索:
用CPU独立运行及加速整个Engram模块
在Engram相关论文发表,DeepSeek开源上述流程的Demo代码后,不少业内专家和机构都开展了相关的复现、验证及测试工作。我们的探索则更进一步——不同于原论文中Concat之后的工作任务将交还给GPU执行,我们不仅将N-gram哈希检索阶段的计算放在至强®平台上执行,还将动态门控融合阶段中的Linear转换计算和Conv卷积计算也放到该平台上运行。换言之,我们是基于充分的性能调优,尝试用CPU平台独立运行和加速整个Engram模块。
这种“更进一步”的底气,来自AMX技术,这是从第四代英特尔® 至强® 可扩展处理器开始就内置于至强® 处理器,且到目前为止也是全球主流服务器CPU产品中仅为该产品线所独有的CPU内置型矩阵计算加速技术。无论是Linear转换计算还是Conv卷积计算,都属于矩阵密集型计算,因此,理论上内置AMX的至强® 处理器可以“顺势”完成整个Engram的运行和加速。
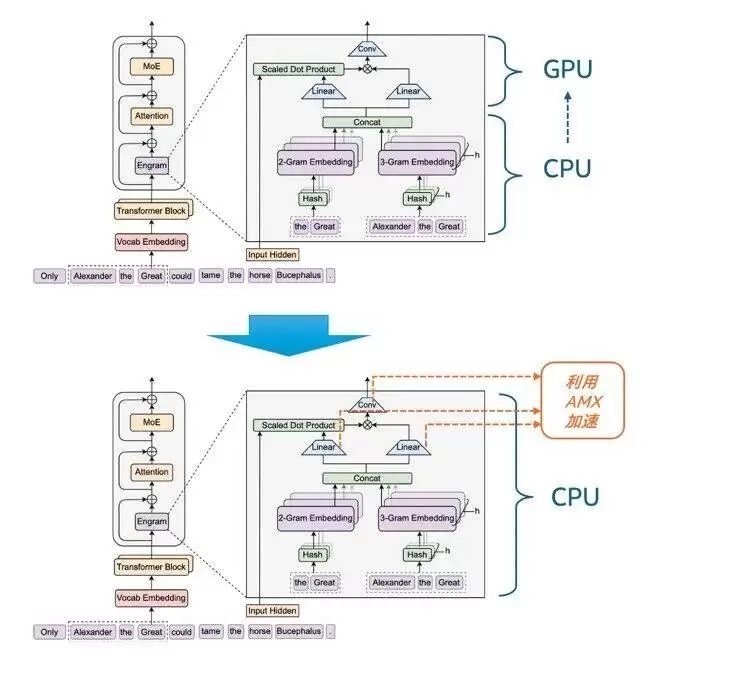
图3 从Engram原有工作流程转向用CPU运行整个模块并导入AMX加速
基于此,我们着手在Linear转换计算和Conv卷积计算中利用AMX技术开展了性能加速。具体来说,在Engram中,两个Linear转换计算分别需要处理大量维度映射的矩阵乘法,而AMX的专用矩阵计算单元可并行处理多批次、长序列的高维矩阵乘法,且单条指令可完成更大规模的矩阵运算,运算效率远超传统CPU计算或向量计算(如AVX-512)。在Conv的 short_conv(短卷积)计算中,AMX的矩阵运算能力也可针对短卷积的“小窗口、高并行” 特性实现优化。此外,AMX还对BF16/FP16/INT8等不同的数据格式有着良好支持,能进一步提升矩阵运算加速的性能与灵活性。
我们目前已完成了一些初步测试,如图4和图5所示,其结果表明,在同一款至强® 6处理器平台上,如果使用AVX-512加速,在batch size等于50,token length等于14的FP16数据格式下,整个Engram的耗时需要10.046ms, 而使用AMX来加速Linear转换计算和Conv卷积计算,Engram的耗时只要6.022ms,整体性能提升至AVX-512的1.67倍ii。

图4 测试得出的在FP16数据格式下分别用AMX 和AVX-512加速的执行时间
(每次测试结果都可能存在少许浮动,在可接受范围)
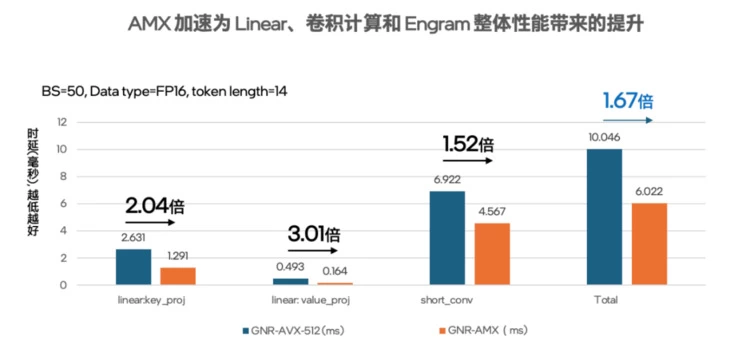
图5 用英特尔® AMX加速Engram模块中Linear和卷积计算的性能表现
上述探索和测试是基于DeepSeek开源的deepseek-ai/Engram: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models的相关代码,欢迎同行们一起讨论交流。
接下来英特尔会继续围绕Engram及集成它的大模型开展更多、更为深入的探索,特别是在DeepSeek相关模型正式发布后,我们会更为全面、系统地评估CPU独立运行和加速Engram模块会对整个模型的端到端性能、部署和应用的门槛,以及投资回报等维度带来怎样的影响,相关进展与成果也将在第一时间分享。
正如开篇所说,我们相信这些工作与Engram的设计初衷是相向而行的,即在用 “查算分离” 理念打破传统大模型的记忆困境的同时,也让AI基础设施中的GPU和CPU实现更好的协作,并充分释放它们各自的潜能,进而大幅提升AI系统的部署效率及投资回报,或者进一步拉低AI部署与实践的成本或门槛。我们的工作,就是希望能为这一目标的达成拓展出更为多样化的技术路径与更强的灵活性。
相关文章
- 做表格AI又升级了!数以轻舟Agent V3.2:当Deepseek V4 Pro遇上百万
- 时的科技黄雍威:载人eVTOL已成为新势力,进入下一个DeepSeek时刻
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 追觅硅谷发布的高光时刻:中国智造Deepseek时刻已经来临 商业范式面临巨大变革
- 国产算力×国产模型,联想开天工作站全面适配 DeepSeek V4!
- 金融智能新跨越:中国银联依托昇腾算力率先完成DeepSeek-V4私有化部署
- 探索“数算模用“一体化发展,超算互联网加速DeepSeek V4赋能千行百业
- 显示龙头卡莱特完成DeepSeek V4在昇腾平台验证,国产大模型工程化落地提速
- 超算互联网推出限时免费DeepSeek-V4对话服务 零门槛解锁百万Token体验
- DeepSeek-V4 上线国家超算互联网:以普惠算力与开发者共逐AI新浪潮
- 每日互动个知·智能工作站率先接入DeepSeek-V4
- 元戎启行冲刺百万级交付,前DeepSeek核心成员阮翀将亮相北京车展
- “马”上有Token,联通云“万亿”免费送!——联通云×OpenClaw+DeepSeek,零成本解锁灵活办公新方式
- 开箱即用、安全无忧!麒麟信安全国产化智算一体机发布,高效赋能DeepSeek大模型应用实践
- DeepSeek最火Engram怎么跑?英特尔至强+AMX实测:性能提升达1.67倍!
- “工业版DeepSeek”,安世亚太精智 iGPT 工业大模型平台荣获国家工业大模型最高评级
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


