桥介数物跨本体全身运动数据工厂:通用全身运动模型的数据基础设施
2026-05-22 20:10:28AI云资讯1907
01
写在前面
我们建设了一座跨本体全身运动数据工厂(Cross-Embodiment Whole-Body Motion Data Factory),打通了从动作设计、同步采集、跨本体重定向、数据增强到训练反馈的完整链路。数据工厂作为一座持续运转的基础设施,能够为人形机器人操作系统提供数据燃料,让系统里的全身运动模型不断获得跨本体、可训练、可复用的数据资产。
模型能力的提升正在越来越明显地受到数据制约。数据规模不够,模型很难覆盖足够多的动作;数据质量不稳,模型会学到错误的接触关系和身体协调方式;数据不能跨本体复用,机器人硬件一换,很多训练资产就要重新生产。
对通用全身运动模型来说,数据已经不只是训练材料,而是决定能力边界的重要资产。
基于这次试点和过去两年在多种足式机器人上的工程实践,我们正在把数据工厂从内部验证推向正式规模化建设。它要解决的是如何持续规划动作、同步采集多源信号、跨本体重定向、做物理验证和数据增强,并把训练结果反馈回下一轮生产。
这篇文章分享我们对运动控制数据工厂的阶段性思考:什么是跨本体全身运动数据,我们为什么要专门为它建一座工厂,以及这座工厂内部应该如何运转。
02
从运动能力出发
我们需要什么数据
要回答“需要什么数据”,先要回答“我们想要什么运动能力”。
对通用全身运动模型来说,我们要的是一种能够向上兼容多模态动作意图、向下兼容不同本体硬件、安全可靠、并且可以在复杂环境中持续进化的运动能力。
这种能力对数据提出了更高的要求:模型需要的是能同时保留全身协同、任务意图、接触关系、环境上下文、物理可行性和跨本体复用价值的数据。
但现有的数据形态,单独看都很难自然满足这些要求:
动捕数据可以准确、结构化地记录人体运动状态,但缺失环境信息以及人和环境之间的精确交互;
遥操作数据严格绑定特定机器人本体,硬件一换,复用价值就会显著下降;
第一人称视频集中在末端和物体交互,不能完整表达躯干、下肢、重心和接触之间的全身协调关系;
第三人称视频虽然能看到整体动作,但难以从中提取出准确合理的人体动作。这些数据各自都有价值,但单独都不足以支撑通用全身运动模型需要的数据闭环。
基于这个判断,我们把真正面向通用全身运动模型训练的数据资产,定义为跨本体全身运动数据(Cross-Embodiment Whole-Body Motion Data,CWM),要求 CWM 至少同时满足以下四个性质:
跨本体可重定向性(Cross-embodiment retargetability)
同一段动作必须能够通过统一的处理管线,在连杆长度、关节配置、质量分布和驱动能力差异显著的多种目标本体上,产出物理自洽的训练样本。这意味着原始数据本身需要带有足够的拓扑与运动学信息,以支持对不同本体的统一构型映射,而不是绑死在某一台机器人的关节空间里。机器人硬件会持续迭代,如果数据只服务某一代本体,它就会跟着这一代硬件一起折旧;CWM 把数据价值绑定在人类全身运动语义和可迁移规律上,让一份数据能在多代硬件上反复结算。
全身覆盖性(Whole-body coverage)
数据必须完整表达躯干、四肢、手部、手指以及它们之间的协同关系,而不能只保留上半身末端轨迹或下半身步态。真实任务往往不是局部动作的简单拼接,例如“蹲下捡物—抱起—转身行走”,同时涉及下肢支撑、重心转移、躯干姿态、手臂伸展、手指抓握和接触切换。只有把这些身体部位的耦合关系作为一个整体记录下来,模型才能学习移动、操作和姿态变化之间的协同规律。
物理可行性(Physical feasibility)
一条合格的数据,不只是运动学平滑合理,还需在目标本体上的动力学具备物理可行性,不能出现浮空、穿透、滑移、失稳、力矩超限等问题,这是 CWM 资产从候选轨迹升级为训练样本的硬门槛。
多模态性(Multi-source augmentability)
CWM数据在录制阶段就同步采集人体动作、语义标签、第一人称视频、第三人称视频、环境资产和物体资产,使动作带有完整的身体、任务和场景上下文。随后,我们会在仿真环境中回放并增强数据,通过自定义摄像机位置、更换场景与物体材质贴图、采集全身接触力和运动状态,将单次采集扩展为多视角、多场景、多物理状态的训练样本。
满足这四个性质的 CWM 数据,不是简单的采集就能得到,这也是我们建设跨本体全身运动数据工厂的出发点。
03
为什么要建一座数据工厂
我们定义了什么是 CWM 数据,但对模型训练来说,仅有“正确”的数据并不足够,数据规模同样至关重要,这一点在大模型领域已成共识。
Generalist AI 的研究指出,VLA 模型同样存在明确的数据 scaling law;SONIC 也在人形机器人全身运动跟踪上系统验证了,运动数据量的扩大会带来运动控制能力的显著提升。对于全身运动控制来说,这意味着数据要覆盖的不只是几个标准动作,而是行走、转身、下蹲、搬运、抓取、支撑、避障、恢复平衡、接触切换等大量连续动作组合。
按我们内部的判断,要训练出一个真正通用的全身运动模型,最终需要数十万小时级别的高质量 CWM 数据;在这个量级面前,少量数据几乎没有长期训练价值,真正有价值的是能够不断扩张的数据规模。
与此同时,数据的多样性同样重要,因为再多的走路数据也训不出一个会后空翻的模型。全身运动数据的复杂性在于,它不只是“动作越多越好”,而是必须有正确的数据配方和严格的数据质量控制。
模型需要看到足够多的动作类别、接触状态、任务语义、环境变化和目标本体差异;同时,每条数据还必须经过清洗、标注、重定向和物理验证。否则,大规模数据很容易变成大规模噪声。脚底滑移、身体穿透、浮空、失稳、力矩超限等问题是直接拉低模型质量的数据污染,它们会让模型学习到错误的接触关系、错误的身体协调方式和不可执行的控制模式。
这条标准也意味着外部数据无法成为主力:公开动捕和网络视频可以作为补充,但在数量和质量上都不足以支撑通用全身运动模型的训练。
因此,CWM 数据生产必须被设计成一套工业化生产体系,而采集只是其中一环。一段动作从被设计出来,到能进入训练集,还必须经过质检、跨本体重定向、动力学与仿真增强、语义标注,以及来自模型训练侧的反馈闭环。
这条产线需要同时定义数据配方、生产流程和质量标准:哪些动作必须优先覆盖,哪些场景和接触状态最稀缺,哪些目标本体需要验证,哪些样本应该剔除,哪些数据在训练中产生了最高收益,都需要被持续追踪和反馈。数据规模越大,越不能依赖手工经验;模型目标越通用,越需要可复现、可审计、可迭代的生产流程。
这也是 CWM 数据工厂的核心价值:用稳定的场地、设备、流水线、专业团队和质检体系,把通用全身运动数据变成一种可持续生产能力。
专业动作设计人员负责定义动作谱系,采集团队负责高质量同步录制,工程团队负责清洗、格式化、重定向和仿真回放,算法团队负责物理验证、训练反馈和数据筛选,质检团队负责把不可用样本挡在训练集之外。
只有这样的工厂级体系,才能持续产出足够大、足够准、足够干净,并且能随模型训练和机器人迭代不断更新的 CWM 数据资产。
04
数据工厂不是“采集场地”
而是“基础设施”
桥介数物跨本体全身运动数据工厂是一套围绕 CWM 数据资产生产的全流程基础设施。
它从动作设计开始,明确动作类别、接触状态和任务场景;在采集阶段,同步获取人体动作、视频、接触、环境和物体等多源数据;随后通过跨本体重定向、物理验证和仿真增强,把原始素材转化为可训练样本;最后,再用训练反馈持续修正数据配方。
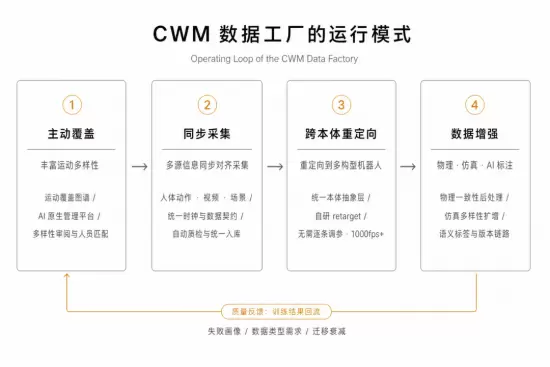
主动覆盖:丰富运动多样性
数据工厂第一件要回答的事是“采什么”。通用全身运动模型需要见到一套持续扩展、能够覆盖身体协同方式的运动空间。这套空间不能只是动作目录的堆叠,而要沿几条相互独立的主线持续填充:
能力维度的横向铺开
采集计划要按身体使用方式来组织,而不是按动作名称凑数。移动、姿态转换、肢体协同、接触切换和物体操作这些基础维度,是后续复杂能力的底盘。我们关心的是身体如何被调用、不同身体部位如何协同、重心和接触如何变化,而不是某一个具体动作是否被采到。
复杂地形、多人交互与环境交互
这三类场景是基础维度之外难度最高、最贴近真实部署的需求,但是又最容易被漏掉的场景,必须被显式安排进采集计划。复杂地形会改变支撑和落脚策略,多人交互会引入节奏对齐和空间协商,环境交互会让身体运动与物体、接触面和可达空间深度耦合。它们不能靠平地单人动作自然外推,必须被显式安排进采集计划。
下意识行为与自由发挥
剧本只能定义任务边界,真实运动里还有大量没有被写下来的部分:个体动作习惯、临场调整和应对意外的本能反应。专业动作设计人员会在录制中给出意图与约束,同时保留表演者按自身习惯完成动作的空间,让数据既覆盖任务目标,也保留真实身体差异。
动作恢复与失败兜底
模型在真实环境里能不能被部署,很大程度上取决于失败时能不能稳住。因此动作恢复要单独进入采集计划,包括失衡后的再平衡、碰撞后的避障回缩、跌倒或非理想姿态下的起身恢复。这类样本通常稀缺,但直接关系到模型的安全边界。
采集多样性同样需要在源头被显式管理。采集人员与采集设备的多样性会直接影响 CWM 数据的多样性与丰富度:不同身形、年龄、性别、体态的表演者会带来差异化的运动姿态、关节角度范围和重心控制方式;不同采集设备(惯性动捕、光学动捕、电磁动捕)在精度、覆盖范围、佩戴约束和适用场景上的差异,本身也会成为数据的一种维度。只有让人员和设备的多样性都进入采集计划,模型才不会只学到“某一类人在某一种设备下”的运动方式。
这些方向通过一份持续更新的运动覆盖图谱被组织和度量,记录哪些组合已经被覆盖、哪些维度仍然稀疏、哪些样本在跨本体迁移后反复失败。
除了按图谱主动覆盖,数据工厂还会显式接收来自模型训练侧的数据类型需求反馈:哪些动作类别在哪些本体上学得不稳、哪些接触状态训练收益最低、哪些样本通过了质检却没有带来实际增益,都会被翻译成新的数据类型需求回写到采集计划,让“采什么”持续被训练结果校准。
为了把上面这些需求真正转化成可执行的采集任务,我们在工厂内部建设了一个AI 原生的数据设计与录制管理平台,把动作需求、覆盖图谱、场景资产、录制计划、数据状态和训练反馈放进同一个系统里管理。
平台的核心使用者是一组全职的专业动作设计人员,他们负责定义动作语义、拆解身体协同、判断表演可执行性,把全身交互、动作恢复、工具使用和场景任务转化为可录制的动作方案。
平台借由内置的 AI 能力,沿三件事辅助设计人员把动作方案做出来:
动作方案的生成与扩增上,平台基于覆盖图谱缺口和训练反馈起草动作描述、做语义级泛化,按速度、体型、节奏等维度衍生出大量变体;
方案的可视化呈现上,可以选择使用AI直接通过文本描述或者动作关键帧生成动作示例,把抽象描述变成可演示的参考动作;
多样性审阅与人员匹配上,平台比对当前批次相对覆盖图谱的分布偏差,提示设计人员哪些维度被过度采集、哪些仍然稀疏,并按身形、年龄、性别和体态,辅助设计人员把每条方案分配给最合适的表演者、采集设备。
这条工具链让覆盖图谱、设计人员判断和模型训练反馈在同一个系统里闭环,把“哪些动作已经学稳、哪些动作迁移失败率高、哪些场景还缺覆盖”持续转化为可采、可查、可反馈的生产任务。
同步采集:多源信息同步对齐采集
CWM 的同步采集不是单纯录一段人体动作,而是要在同一段动作中同步回答四件事:运动意图、身体运动方式、交互目标与环境。“全身”意味着移动、操作、姿态控制、接触变化等子任务在同一段动作里同时成立,不能退化成躯干、手、腿轨迹的简单拼接。这天然要求人体动作、视频、语义、场景被同步记录。按当前的采集规范,一条完整记录会尽量同步以下四类信号,具体哪些可用取决于采集场景和目标本体。
人体动作(BVH)
跨本体重定向的主要参考信号,承载动作语义、身体协同、重心变化和姿态转换。我们在录制不同类型的动作时选用不同设备:
低动态动作和复杂地形下的运动适合惯性动捕,对场地、遮挡和地形不敏感;
高动态动作适合光学动捕或精度更高的光惯混合设备,能在快速运动下稳住关节位置;
末端手部的精细动作(抓握、操作工具、按键、拧动)适合电磁动捕,能在小空间内提供高精度位姿。
原始视频
不直接进入重定向流程,但在数据工厂里是高价值的辅助信号:它支撑视频动作补全与人体动作提取,让海量互联网视频可以被纳入训练资产,也为导航与操作预备视觉模态;同时被用于训练 SLAM、估计人与物体之间的接触状态。设备上以头戴式相机与外部 RGB / RGB-D 相机并行采集,分别提供第一人称和第三人称视角。
场景交互资产
提供动作发生的环境与物体上下文,是把动作放进仿真环境的前置条件。
我们采集两类:一类是地形与场景资产——房间结构、地面起伏、固定家具,决定动作可达空间和接触面;一类是可交互物体资产——被搬运、推拉、使用的物体,决定操作任务的目标几何。
技术上以 3D 高斯泼溅 + Mesh 提取做整体重建,对需要精确位姿的物体进一步使用光学 Marker 标记。资产进入仿真环境后支撑强化学习训练和模型评估。
语义标签
由专业动作设计人员、现场记录员和 AI 标注系统协同生成,定义动作边界、动作类别、场景和意图,决定每条样本如何进入训练集,以及在训练里如何被采样、加权和评估。
之所以必须同步,是因为全身运动的价值不在某一个单独模态,而在不同模态之间的对应关系。 同一个“蹲下捡物”动作,人体 BVH 只能说明身体姿态如何变化;视频说明物体在哪里、手是否真的接触;场景资产说明物体所在的环境和可交互面;语义标签说明动作边界和任务意图。如果这些信号没有对齐,我们就无法判断手部轨迹对应的是哪一帧物体接触,也无法判断脚底受力是否对应当前姿态,更无法验证这段动作是否真的可以进入训练集。
为此,数据工厂为所有采集设备建立统一的采集时钟和时间戳体系:所有设备在采集前完成空间标定和时间校准,采集过程中由主控系统统一管理任务编号、动作编号、设备状态和开始 / 结束信号;能够硬件同步的设备优先使用触发信号、帧同步、时间码或 PTP 等方式对齐,不能硬件同步的设备则在本地记录高精度时间戳,并通过同步动作、标定事件或后处理算法做时间同步校正。
同步之后,每一条数据需要被整理成可以直接进入下游流水线的资产,这部分工作同样由前述录制管理平台完成。
平台一边做现场自动质检——检查时间同步、标定、轨迹完整性、骨长稳定、关键点异常和动作段边界,AI 辅助检查动作语义、表演一致性和明显录制异常;一边做统一入库——把同一段动作下的所有模态打包成统一数据包,绑定会话、设备状态、标定版本、时间偏差、丢帧情况和质检结果,并以主时钟为基准完成对齐、重采样和切片,形成能够直接进入重定向与训练流水线的最小数据契约。
跨本体重定向:重定向到多构型机器人
异构性问题的核心解法是动作重定向(motion retargeting):把一段以人体或某一参考本体为坐标系的动作,转化为目标机器人本体上的轨迹。到了工业化生产里,难点不再只是“能不能把一个动作转到一台机器人上”,而是能不能在大量动作和大量本体之间,持续、稳定、低成本地完成这件事。
算法层面,我们自研的重定向引擎面向“任意动作 × 任意机型 × 任意地形”。输入侧覆盖任意动作、上半身 / 下半身 / 全身,可以处理离线动捕文件、实时动捕流,也支持视频动作等不同来源的动作信号;输出侧覆盖结构、关节配置、尺度和驱动能力差异显著的足式、人形、上肢和复合构型机器人,并能把平地、斜坡、楼梯、不平地面等地形约束纳入统一求解,不需要为每条动作、每台机器人或每类地形单独写一套专用解算逻辑。求解器以运动学求解和几何约束为主干,把接触状态、支撑关系、空间约束、地形约束、关节限制和身体交互关系纳入同一个求解过程,输出语义一致、结构可达、质量稳定的候选轨迹。
工程层面,它有三个直接服务于工厂化生产的优势。
第一,无需逐条调参、无需动作模版:跨本体能力来自一层统一本体抽象层——新机器人接入时,我们只依赖该机器人的 URDF 定义,算法就能在这层抽象上自动快速适配多种构型,不需要为每条动作或每台机器人写专用解算逻辑,也不依赖逐条动作的人工微调。
第二,流式与离线双模式:既能消化采集端实时进入的动作流,也能批量处理已有的动作库;这一点让重定向不再是“采完再处理”的离线工序,而可以做到边采边重定向——动作刚被记录下来,目标本体上的候选轨迹就已经可用,质检和后续动力学增强可以紧接着接入。流模式下,我们的重定向工具支持Noitom和Xsens等多种设备的输出数据。
第三,跨平台稳定分发:从工程站点、采集现场、训练集群到目标机器人侧都能以一致的形式部署和回放,让动作流在生产链路上始终基于同一份算法实现。
产能层面,它已经是工厂的主干生产服务。 按当前统计口径,这套重定向算法在单 CPU 核心上可以超过 1000 帧每秒,约为常规录制帧率的十数倍;我们为这条路线准备了一个算力集群,让它能持续消化采集端进入的动作流,并支撑同一段动作向多构型机器人并行派发。落到生产口径上,它把“每条动作都需要人工适配”的隐性成本,压缩成新本体接入时的一次性工程标定,把“采集 → 重定向 → 候选训练样本”的链路时间从天级压缩到接近实时。
数据增强:动力学、仿真与 AI 标注增强
跨本体重定向输出的是高质量候选轨迹,但候选轨迹还不是最终训练资产。数据增强要做的是继续把这些候选轨迹变成更可验证、更可训练、更容易被模型消费的数据。我们沿三条主线推进:动力学增强、仿真多样性增强、语义标注。
动力学增强把最有价值、最困难、最需要物理一致性的样本放进目标本体的动力学与接触模型里,通过 RL 动力学后处理同时控制跟踪误差和物理违背,让候选轨迹从“运动学上像”升级为“在目标本体上能跟踪、不穿透、不超扭矩、不违反摩擦锥”。被判定不可行的样本会带着具体失败原因进入质量反馈,而不是被直接丢掉。
仿真多样性增强则把同一段动作放进不同的虚拟环境里反复执行,让 CWM 资产的覆盖密度成倍放大。
一方面补齐缺失模态:通过物理仿真和渲染管线,给原本只采到动作和视频的样本补出力学信号、深度图、语义分割、多视角图像等本来没有采到的模态;
另一方面扩增视觉与场景多样性:替换物体和环境的贴图资产、调整材质和光照、变换房间布局、引入新的交互对象和初始状态、施加不同方向和强度的外力扰动。同一段动作可以在多个目标本体、多套场景、多种光照和多组扰动条件下派生出大量新样本,让模型见到的不是“做这个动作的一种方式”,而是“做这个动作的一个分布”。
语义标注让数据成为能被训练流水线检索、加权、筛选和复用的资产。AI 标注系统辅助生成动作切片、动作类别、接触状态、场景对象、任务语义、失败原因和能力维度等标签,专业动作设计人员负责复核语义边界和关键样本,把标注产出收敛到可用于训练采样和评估分桶的标准格式。
三类增强共用同一套版本与来源记录:每一条增强后的样本都会标记它来自哪条原始动作、经过哪个目标本体、哪一次动力学后处理、哪一轮仿真扩增、哪个标注版本,以及是否通过物理验证。这样训练系统能在不同版本之间安全地复用、对照和回滚增强样本,质量反馈也能在出问题时把责任定位到具体的增强环节。
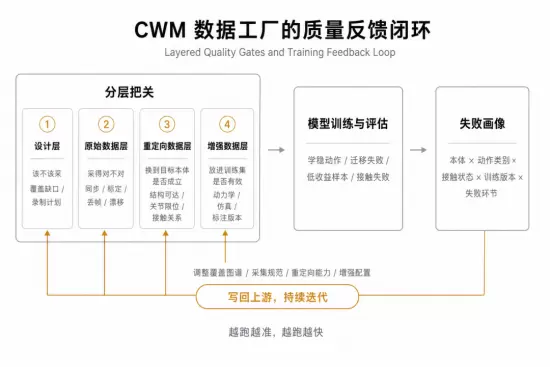
质量反馈:让模型训练结果回到生产系统
传统动捕质检多看轨迹是否干净;CWM 数据工厂的质量管理则要走两步:先沿生产链路做分层把关,再用模型训练的结果做闭环反馈。
第一步是分层把关。 一条样本从动作需求走到训练集,要顺序通过四道独立的质检,四层把关共同把一条候选样本筛成可入训练集的资产,但真正能不能训练出通用全身运动能力,最终只能由模型告诉我们。
设计层
动作需求是否真的对齐能力缺口、是否覆盖运动覆盖图谱里仍然稀疏的格子、是否能落到现场可执行的动作方案上。这一层把控“该不该采”。
原始数据层
表演者是否完整表达了设计意图,采集是否同步、标定是否到位,是否存在丢帧 / 漂移 / 关键点异常 / 骨长不稳等基础录制问题。这一层把控“采得对不对”。
重定向数据层
候选轨迹在目标本体上是否结构可达、关节是否越限、接触关系是否成立、动作语义在重定向后是否仍然成立。这一层把控“换到目标本体上是否还成立”。
增强数据层
动力学后处理后是否仍然可跟踪、不穿透、不超扭矩、不违反摩擦锥;仿真扩增和语义标注是否带上正确的版本与来源记录。这一层把控“放进训练集是否真的有效”。
第二步是结果闭环。 训练侧会把每一次模型评估结果,例如哪些动作类别在哪些本体上学稳了、哪些迁移失败、哪些接触状态训练收益最低、哪些样本通过了四层把关却没有带来实际增益,汇总成一份可回写的失败画像:在哪个本体、哪个动作类别、哪个接触状态、哪个训练版本下出问题,问题归因到设计、原始采集、重定向还是增强环节。
失败画像会被直接写回到上游每一层:设计层据此调整运动覆盖图谱的优先级和录制计划;原始数据层据此调整采集规范、同步策略和现场质检阈值;重定向层据此迭代算法能力;增强层据此调整动力学后处理强度、仿真多样性配置和标注口径。
两步合在一起,数据工厂就形成了持续迭代闭环。 它在实际运行中是双线推进:一条线是基于长期判断的主动覆盖,按运动覆盖图谱不断扩展人类全身运动库;另一条线是模型训练侧的反馈补洞,按失败画像回填上游每一层。每跑一轮,数据资产的质量、跨本体覆盖密度和训练收益都会同时往上抬一点:越跑越准、越跑越快,是 CWM 数据工厂随时间复利的核心来源。
05
写在最后
我们数据工厂的现状和未来
过去三个月,我们在内部试点中跑通了跨本体全身运动数据工厂的端到端链路。这一阶段的目标不是追求最大产能,而是把整套生产系统真正运行起来:动作设计能否被系统化管理、多源采集能否稳定对齐、重定向能否快速适配新本体、增强和质检能否把候选轨迹变成可训练资产、训练反馈能否回到下一轮生产。
沿着这条链路,我们累计产出了近千小时高质量 CWM 数据;用这批数据训出的全身运动模型,最终在十多款结构、驱动性能、质量分布和惯量分布差异显著的足式机器人上完成了关键验证。
现在,这套方案已经完成内部可行性验证,数据工厂也即将完成正式建设。下一阶段的重点,是从试点验证转向规模化生产——把场地、采集棚、动捕设备、动作设计团队、表演者编制和算法 / 仿真 / 训练算力集群同时扩容,让前面跑通的产线在更大规模上稳定运转。
我们的目标是在新工厂落地后,形成每月数千小时级、面向多构型机器人的高质量 CWM 数据产出能力,并沿“数千小时 → 数万小时”分阶段爬升;在这一过程中,数据质量、跨本体复用率和训练增益会作为同一套生产标准被持续考核,让每一批新数据都能回答它在多少种本体上能跑通、在哪些动作类别上贡献了真实训练收益,而不只是“采到了多少小时”。
相关文章
- 践行算力普惠 赋能中小企业 | 易信“易Token”模型服务平台重磅发布
- 东软添翼医疗大模型荣登“医疗AI大模型最具应用价值产品榜”
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 群核科技空间智能大模型完成国家备案,加速走向产业应用
- 破解大模型“幻觉”,徐剑军选择“可信”之道
- 携手共建“物理世界大模型”联合实验室,洞察时空与上海电信达成战略合作
- 东软添翼医疗大模型领跑 医疗AI进入“可信时代”
- 不止于降本提效:微盟AI重构零售经营,驱动商业模型从“费用”走向“资产”
- 直接上智能体,还需要统一基座大模型吗?医院智能化走到十字路口
- 云知声 U2-ASR 2.5上线:首个中文方言语义转写大模型
- 全国首个内容审核大模型过审 云从科技破解Agent时代谣言难题
- 湖北移动AI实验室让中小企业零门槛用上大模型
- 数据的第三种形态:艺恩如何为大模型提供多模态的数据弹药?
- 荆华密算入选主流价值语料生态联盟首批成员,护航大模型时代,为AI系上“安全带”
- OpenAI 新模型密集更新,Meta/微美全息强化布局AI核心需求迎爆发增长!
- 稳居第一梯队!东软添翼医疗大模型用实力回应“医疗AI”
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源


