云工场科技推进CPU+GPU协同推理,推动大模型应用降本增效
2026-05-25 12:03:57AI云资讯2228
随着大模型应用从训练走向规模化推理,算力供给正在面临新的结构性挑战。
一方面,高性能 GPU 资源持续紧张,推理调用成本居高不下;另一方面,大量存量 CPU 服务器在传统通算场景之外,仍有进一步释放价值的空间。如何让通用计算资源与智能计算资源形成协同,成为提升大模型推理效率、降低应用成本的重要方向。

围绕这一趋势,云工场科技正在推进“面向大模型推理的通算智算融合调度与协同推理平台”相关研究与建设。
平台依托云工场现有边缘云与智算基础设施,将 CPU 通用计算资源、英伟达 GPU、AMD GPU、国产 GPU 等多架构资源纳入统一资源池,探索面向大模型推理场景的异构算力协同调度能力。
该平台的核心思路,是让 CPU 不再仅作为传统通用计算资源,而是参与到 AI 推理服务链路之中。
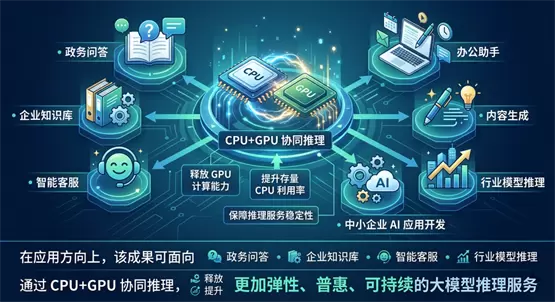
在大模型推理过程中,CPU 可承担请求接入、任务队列、数据预处理、上下文管理、KV Cache 管理、服务编排、轻量推理、Token 计量等环节;GPU 则重点承担大参数模型计算、高并发矩阵运算等核心推理任务。通过“CPU 负责组织与辅助计算、GPU 负责核心推理计算”的协同架构,平台有望提升整体资源利用效率,缓解单一 GPU 推理模式下的资源压力。
与传统 GPU 推理服务不同,云工场科技此次研究的重点不只是资源层面的统一纳管,而是围绕推理链路进行协同优化。平台将根据模型规模、并发请求、响应时延和成本目标,动态匹配 CPU、GPU 或 CPU+GPU 协同执行方式,推动通算资源与智算资源在实际业务场景中的融合使用。
在应用方向上,该成果可面向政务问答、企业知识库、智能客服、办公助手、内容生成、行业模型推理、中小企业 AI 应用开发等场景。通过 CPU+GPU 协同推理,平台可在保障推理服务稳定性的基础上,进一步提升存量 CPU 服务器的 AI 化利用效率,释放 GPU 核心计算能力,并为政府、园区、企业、开发者和 ISV 提供更加弹性、普惠、可持续的大模型推理服务。
后续,云工场科技将按照“资源接入—链路拆解—协同调度—场景验证—规模应用”的路径持续推进相关能力建设,并结合裸金属、容器云、弹性算力、模型服务、API 调用、Token 计量等产品形态,逐步形成面向城市级 AI 应用场景的通算智算融合推理服务体系。通过持续推进 CPU+GPU 协同推理研究,云工场科技将进一步探索存量算力资源盘活、高端 GPU 资源优化使用以及大模型应用成本下降的可行路径,为 AI 应用规模化落地提供更加坚实的算力支撑。
相关文章
- 云工场科技将携AIoT道路巡查与算力体系,亮相大湾区智慧交通大会
- 云工场科技硬核筑基!无锡市算力调度运营平台正式亮相
- 云工场科技建设沐曦国产GPU万卡智算集群,一期正式点亮
- 云工场科技打造异构算力调度平台,推动 AI 算力从建设走向运营
- 无锡3x3篮球联赛燃动宜兴陶二厂,云工场科技以算力赋能赛事活力
- 云工场科技:让AI给公路做“巡查”,每一公里都心中有数
- 云工场科技推进CPU+GPU协同推理,推动大模型应用降本增效
- 云工场科技拟投入数亿元加码算力调度平台+算力基础设施
- 云工场科技成为海淀3x3超级争霸赛与无锡杯官方算力支持伙伴
- 云工场科技(02512.HK)落子无锡 携手沐曦股份+AMD双线发力国产智算新赛道
- 云工场科技携手沐曦股份:25亿打造无锡国产万卡算力新标杆
- 云工场科技连续四年入选“中国边缘计算企业20强”,引领行业趋势
- AMD 发起百万美金黑客松,云工场科技一站式算力解决方案来助力
- 云工场科技携鲸智社区共同推进OPC服务平台建设,加速AI创业生态落地
- 云工场科技中标逾5亿元算力项目,推动国产AI算力集群规模化建设
- 云工场科技荣获2025年度上市公司卓越 ESG 价值榜“ ESG 卓越影响力企业”
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


