韩国AI芯片企业FuriosaAI下一代AI加速器采用2nm芯粒架构,支持HBM4/E内存
2026-05-28 09:01:12AI云资讯1839

(AI云资讯消息)韩国AI芯片企业FuriosaAI 与博通联手打造高性能 AI 加速器芯片,搭载下一代 HBM4/E 内存。
FuriosaAI 已发布其第三代 AI 加速器,该产品基于目前正在台积电 5nm 制程上量产的二代 RNGD 平台打造。二代 RNGD AI 平台采用 180W PCIe 板卡形态设计,专攻大语言模型与智能体 AI 工作负载。随着智能体 AI 需求持续激增,下一代产品将全面发力 AI 推理市场。
FuriosaAI 第三代 AI 加速器平台将 2nm 计算技术与 HBM4/4E 内存相结合,旨在为大规模 AI 计算集群提供高带宽、机架级互联网络。它的架构针对高要求的推理工作负载进行了优化,专注于高带宽数据搬运,从而提供比最高效的 GPU 更出色的每瓦性能和更高的令牌密度。此外,它基于 Furiosa 当前已进入量产阶段的 RNGD 芯片打造,客户包括三星 SDS 和 LG AI 研究院。
根据 FuriosaAI 分享的部分细节,该芯片平台将采用先进的 2nm 计算芯片和 HBM4/E 内存标准。该公司正与博通合作,利用先进的封装技术,将多个硅芯片集成到单一的高性能 AI 芯片(系统级芯片)中。
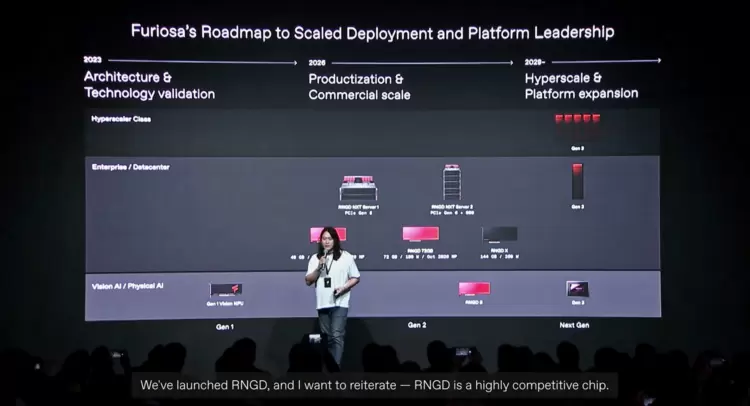
在预告图中,公司展示了第三代 AI 芯片,配备 12 个 HBM4/E 内存位点、两个大型计算芯粒(2nm)和两个 IO 控制器。如果 Furiosa 采用 12 层堆叠、每堆叠 36 GB 的内存模块,总内存容量将达到 432 GB。
除了计算架构之外,FuriosaAI 还将采用博通的以太网和 PCIe IP,从而在大规模 AI 计算集群中实现更高带宽的机架级互联。该 AI 芯片针对后训练采样等高要求的真实 AI 工作负载进行了优化,高带宽是核心关注点,这正是公司选择采用最新 HBM4/E 标准的原因。
FuriosaAI公司声称,其专注于带宽而非线程管理的设计理念,将使其能够提供比现代 GPU 架构更高的效率和更高的令牌吞吐量。此外,公司还表示其软件栈可让开发者快速部署新的 AI 模型,同时满足吞吐量和延迟要求。
Furiosa 的 SDK 采用通用编译器,可自动将高层级 PyTorch 代码映射到芯片硬件。对于需要更精细控制的开发者,Furiosa 的虚拟 ISA 提供了一种声明式编程模型,既能实现对硬件的掌控,又避免了传统 GPU 编程中的不确定性复杂性。
关于上市时间,FuriosaAI 第三代加速器预计将于 2028 年上半年开始提供样片,届时将满足下一代 AI 数据中心的计算需求。相关文章
- AI芯片散热告急!三安光电解锁先进封装“降温密码“
- AI芯片竞争战火升级,特斯拉/Meta/微美全息自研硬核实力发起行业冲锋革命!
- OpenAI新模型发布,Meta/微美全息以AI芯片+模型布局加速行业创新进程
- 中昊芯英“刹那®”TPU AI芯片Day0适配智谱GLM-5
- OpenAI首次采用Cerebras的AI芯片运行Codex模型,成功实现了每秒1000次事务处理量
- 英伟达已瞄准台积电1.6nm产能,特斯拉/微美全息加速扩展AI芯片集群生态!
- 微软正式发布第二代自研AI芯片Maia 200
- AI芯片技术演进的双轨路径:从通用架构到领域专用的并行演进
- 马斯克建造超大型AI芯片工厂的计划初见端倪:先进封装与PCB工厂建设已启动
- OpenAI与博通合作生产自研AI芯片,英伟达独占市场的局面将逐步打破
- 智能汽车+机器人双线布局,黑芝麻智能锚定端侧AI芯片创新
- OpenAI或于2026年推出自研AI芯片
- 信锐极智网络:独立AI芯片加持,引领交换机智能运维新范式!
- 特朗普与英伟达达成协议,仅向我国出售性能降级版AI芯片,并在营收额中抽成15%
- 云天励飞亮相2025WAIC,宣布未来将全面聚焦AI芯片
- 英伟达及其供应链合作伙伴或放弃重启H20 AI芯片生产,转而聚焦新一代解决方案
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源


