忆联×英特尔×新华三:以“存算协同“破局AI智算性能瓶颈
2026-06-22 20:01:25AI云资讯1639
近日,忆联携手英特尔、新华三,三方联合发布面向AI智算场景的新一代分布式存储解决方案。该方案以新华三AI原生存储UniStor X20000为基座,搭载英特尔至强® 6处理器与忆联UH812a企业级PCIe 5.0 SSD,通过存算协同的多层次技术创新,系统性攻克AI训练与推理中高吞吐、高带宽、低延时及多数据类型并存的复杂挑战,为千亿参数级大模型筑牢数据存力底座。

该存储解决方案,搭载英特尔至强® 6处理器,以高性能、高效率、高可靠"三高"标准,从容应对海量数据挑战。
•架构级性能突破
采用RDMA与SPDK全用户态技术栈,实现数据交互零拷贝,结合分布式全局缓存,从架构层面释放极致性能。
•全场景统一存储
实现非结构化协议无损互通,提供可扩展的统一存储方案,一套架构同时满足AI智算、结构化及海量非结构化等多类型数据存储需求。
•弹性扩展,业务随行
精简架构支持性能与容量随集群规模线性增长,灵活匹配业务发展的弹性需求;端到端数据保护能力保障业务永续。
•智能运维,安全可信
支持集群快速批量部署与灵活数据分布策略,允许用户自定义故障域隔离与存储位置选择,确保数据可靠性与访问安全。
软硬协同,构筑高性能存储基座
该方案基于3节点新华三AI原生存储UniStor X20000,单节点搭载2颗英特尔至强® 6 GNR-SP 6530P处理器、18块忆联UH812a PCIe 5.0 NVMe SSD,并通过400GbE CX-7 RDMA网卡实现高速互连。存储系统采用RDMA 与SPDK 全用户态技术,各模块间数据交互实现零拷贝,配合分布式全局缓存机制,最大化释放硬件潜能。
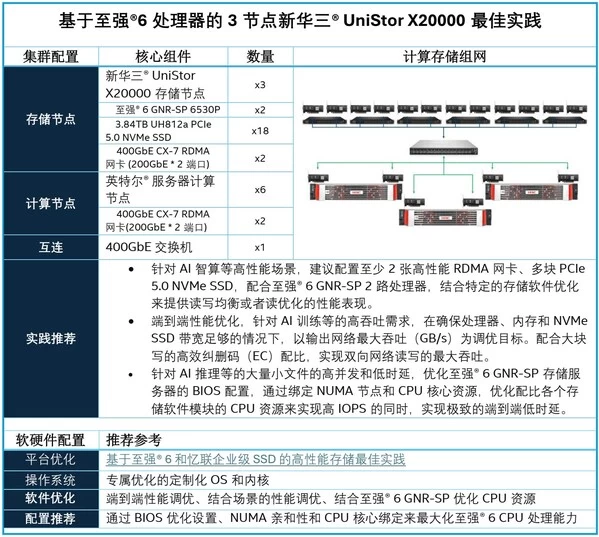
实测数据力证方案硬实力。在3节点存储集群、2.4TbE网络配置下:
•大块数据吞吐惊人——1M顺序读吞吐达260GB/s,EC 4:2配比下1M顺序混合读写更实现317GB/s的极致吞吐,为AI大模型数据加载扫清通路;
•小IO响应极速——4K随机读端到端平均时延严控500µs以内,集群IOPS逼近600万;4K顺序写平均时延低于2ms,IOPS近150万。
无论大块数据搬运还是小IO密集访问,该方案均以业界领先的数据交出亮眼答卷。
三方协同 直击智算瓶颈
AI大模型参数规模持续膨胀,传统存算一体架构已难以满足智算场景的严苛需求。训练阶段需频繁读取海量小文件并写入大规模检查点(Checkpoint),存储带宽与IOPS面临双重压力;推理场景中KVCache等关键数据的存取延迟直接影响GPU利用率,昂贵的算力资源常因存储等待而闲置。与此同时,块、文件、对象、HDFS等多类型数据并存,协议孤岛问题日益突出,管理复杂度持续攀升。存储系统亟待一场从架构到协议的全面革新。
忆联携手英特尔、新华三,交出了一份"全链路协同"的答卷——以忆联UH812a SSD为性能基石、英特尔至强® 6处理器为算力中枢、新华三AI原生存储UniStor X20000为系统载体,实现从介质到处理器再到存储软件栈的深度协同:
•存储介质端,忆联UH812a PCIe 5.0 SSD凭借自研主控架构与极致可靠性,为数据高速流转提供坚实底座,充分释放PCIe 5.0带宽潜力。
•处理器端,英特尔至强® 6处理器内置AI加速引擎,内存带宽提升最高2.3倍,I/O能力全面升级,高效承担算力中枢角色。
•存储系统端,新华三AI原生存储UniStor X20000依托自研统一存储引擎,集成块、文件、对象、HDFS四协议于一体,实现非结构化协议间无损互通,灵活应对AI训练与推理中多数据类型并存的混合负载。
此外,方案支持上千节点线性扩展,容量达EB级别,性能随集群规模同步增长;端到端数据保护与灵活故障域隔离机制,确保业务连续性与数据安全。相较基于上一代至强® EMR 6530处理器的配置(同等SSD、网卡及客户端环境),新一代方案在关键场景中的性能峰值提升可达25%。
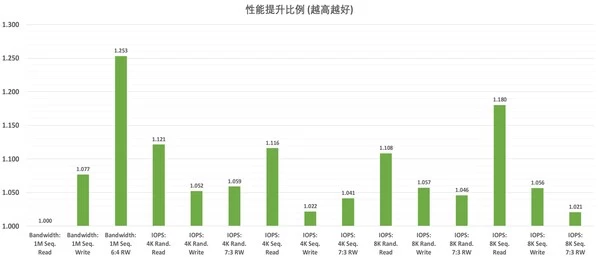
基于3节点方案配置:GNR-SP 6530P VS EMR 6530
UH812a硬核赋能筑牢性能底座
作为该方案的核心性能基石,忆联UH812a企业级PCIe 5.0 SSD采用自研7nm主控芯片,支持NVMe 2.0协议与双端口设计,顺序读/写高达14900/10500 MB/s,4K随机读/写性能达3500K/520K IOPS,为AI数据高速流转提供强劲支撑。
可靠性层面,UH812a搭载LDPC+DSP纠错算法引擎,将闪存寿命延长5倍;动态功耗调节技术实现顺序读峰值功耗控制在18W以内、待机功耗低至5W。产品已通过英特尔全面验证及中子辐照测试,MTBF超过250万小时,年失效率低于0.35%,在AI集群高负载、长时间运行等严苛环境下依然保持稳定输出。

目前,忆联 UH812a 已完成AI训练、多模态数据处理、实时推理、大模型加载、边缘计算等主流AI场景的充分验证,积累了丰富的落地经验,能够全面匹配 AI原生存储UniStor X20000 的多元化业务需求。
忆联与英特尔 联合方案共创价值
作为英特尔在中国区首家国产SSD战略合作伙伴,忆联UH812a产品与至强平台已完成深度适配。双方此前已携手推出基于至强® 6与UH812a的高性能存储方案及RDMA+NVMe网络存储方案,充分验证了软硬协同在高吞吐、低延迟场景下的显著成效。
在新华三AI原生存储UniStor X20000方案中,忆联与英特尔的协同创新获得系统级实践验证,方案可帮助用户在AI智算、大数据分析、数据仓库、企业核心应用等场景中快速复制落地。
此次,忆联携手英特尔与新华三,正式发布面向AI智算场景的联合存储方案。实测数据有力印证了"以存强算"的技术路径——即以高性能存储充分释放昂贵GPU算力,有效消除数据读写瓶颈,确保算力投入的每一分价值都得以兑现。展望未来,忆联将持续深耕存储技术,深化与生态伙伴的协同创新,以坚实的存储底座赋能AI在千行百业中加速落地。
相关文章
- 忆联亮相2026移动云大会,以全场景AI存储方案共筑Token智能新生态
- IDC报告:忆联连续四年稳居国产企业级SSD市场榜首,全栈技术实力持续领航
- 突破PCIe 5.0能效边界:忆联AM6D1以DRAMLess架构重塑性能与成本平衡
- 忆联UH812a以极致存力破局大模型载入瓶颈,释放算力潜能
- 英特尔与忆联共同推出企业级网络存储解决方案,全面赋能AI训练与推理效率跃升
- 忆联发布新款SATA SSD UM311d:以卓越性能与更低TCO,从容应对海量存储需求
- 忆联消费级PCIe 5.0力作AM6D0:11.3GB/s的性能王者,高效创意随行
- 直面DDR5升级挑战,忆联以全系SSD驱动产业高效跃迁
- 行业首发!忆联消费级PCIe 5.0 SSD AM6D1,以11GB/s强劲性能释放AI应用新势能
- PCEVA深度评测:忆联AE531 QLC SSD以高效稳定,从容应对多元应用场景挑战
- 忆联AE531 QLC SSD以三重创新,破局存储密度与能效
- 用户需求驱动的革新:忆联消费级SSD如何从“均衡之选“跃升为“全能标杆“
- 忆联首款消费级QLC SSD AE531重磅发布!以超强可靠性与广泛兼容性,强力打造用户极致TCO
- 忆联参与制定消费级SSD团体标准正式出版! 以“高可靠”引领行业提质增效与用户体验升级
- 破局产能焦虑!忆联全国产SSD M.2自动化方案驱动生产效率跃升
- 忆联 Docker+MySQL 流控方案:打造安全高效存储底座,释放 AI 极致性能
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


