新东方AI研究院院长瞿炜:AI要在教育场景落地必须克服20个挑战
2018/11/16 09:32AI云资讯1740
11月15日,“全球AI+智适应教育峰会”在北京嘉里中心大酒店盛大开幕,峰会由雷锋网联合乂学教育松鼠AI,以及IEEE(美国电气电子工程师学会)教育工程和自适应教育标准工作组共同举办,汇聚国内外顶尖阵容。
AI智适应学习是目前产学研三界关注度最高的话题之一。此次峰会,主办方邀请了美国三院院士、机器学习泰斗Michael Jordan,全球公认机器学习之父Tom Mitchell,斯坦福国际研究院(SRI)副总裁Robert Pearlstein、美国大学入学考试机构ACT学习方案组高级研究科学家Michael Yudelson等顶尖学者。

图为:新东方AI研究院院长 瞿炜博士
在大会下午主论坛上,新东方AI研究院院长瞿炜博士发表了精彩演讲。瞿炜博士在人工智能领域有近20年的丰富研究经历,此前在西门子公司有过工作经历。新东方作为中国最早在美上市的教育公司,在全球已经有超过2000万的学生使用他们的平台。翟炜博士在现场的演讲正是新东方在AI时代的最新思考。
翟炜博士认为,通用AI已经走向瓶颈,场景AI将迎来新的蓬勃发展。而对于AI+教育来说,尽管是极具潜力的市场,但是依然面临着诸多挑战,比如语音识别、人脸识别、文字识别、视频分析等。新东方AI研究院虽然刚刚成立,但会在整体战略上走向“开放”,并将以N-Brain联盟为基点,在数据、场景、资源层面做更多与业界、学界的合作。
以下大部分为翟炜的演讲原文,雷锋网做了不改变原意的编辑与整理。
作为一个接触AI接近20年的老兵,根本就没有想到AI能成为一个行业,甚至在2016年左右的时候,随着AlphaGo为公众所熟悉,AI几乎是指数级地变成了一个行业,所有的互联网公司都在拥抱AI,所有的行业也越来越多地去touch AI。
但是新东方很冷静,俞老师(雷锋网注:俞敏洪)很冷静,并没有着急,给大家的感觉是新东方在做什么?其实我们一直在做AI,各个BU一直在应用AI,但是我们很冷静地在思考教育+AI到底应该怎么做?什么才是最好的时机来拥抱AI?
AI的冬天来了,但春天也不远
事实上,AI在两年的火热之后,冬天已经来临了,就像外面北京的冬天来到了一样。
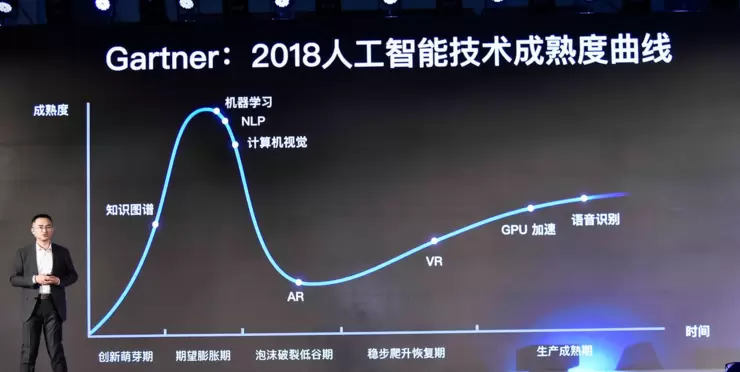
语音识别其实已经很成熟,但是机器学习、NLP、计算机视觉这几个技术(占到AI最重要部分的分支)其实已经过了它的顶峰。以深度学习为例,经过几年大规模的应用,其实越来越多的研究者已经发现,它已经到达了一个瓶颈。我们发现AI并不是像我们想像的那样真的能去替代人。
中国有一句固话叫“冬天来了,春天还远吗”?AI的一个冬天来了,它的下一个春天是什么呢?其实,很多AI行业中的人也意识到了是场景化的AI。
通用化的AI在过去的两年中得到了极大的普及,为公众所接受,很多创业公司如雨后春笋般地兴起,获得了大量的投资,这两年大家都感受到了,甚至融资的速度超越了前几年互联网的速度。
但是,它的冬天来了,因为很多AI的公司并没有商业化变现,当他们落地的时候发现,变现是如此地困难。尤其是在ToC领域。这是为什么呢?
实际上是因为AI和行业的结合非常非常困难,不是那么容易的。所以我们看到通用的AI的发展将会变成这样一个趋势,但是场景化的AI在AI和行业的结合领域会产生无穷无尽的机会。
AI+教育将会是对整个教育科技的重构

AI+汽车已经形成了垂直的平台,百度的阿波罗、谷歌的Waymo都产生了这样的平台,AI+生活催生了Facebook的出现,AI+教育会出现什么呢?我们非常期待。这也新东方对AI+教育这件事深度的思考。
我们认为AI+教育并不一定就是通用AI技术直接嫁接到教育领域,像出现了很多产品级的应用一样,更多的AI+教育将会是对整个教育科技的重构。很多数据都已经准备好,比如说大数据、云计算,但在AI+教育领域必将出现一个新的大脑,我们姑且称之为教育大脑,也必将会出现新的操作系统,这种操作系统可能是在云,也可能在端,因为所有的AI系统肯定是一个软硬结合的系统。
个性化的学习平台将会雨后春笋地涌现
个性化的学习平台将会雨后春笋地涌现。我们认为它一定是开放的,为什么?因为个性化的学习太难了,很难一个公司把它实现。因为这么多的国家,这么多的人群,不同的年龄段、不同的学科,这个问题对研究界而言,几乎是没有唯一解的,所以不可能由一家公司来完成。
新东方AI研究院在“新东方AI+教育战略”基本的步骤,大家可以关注教育大脑的具体应用。
这张图很多在座的朋友们可能都已经看到很多次了,不光是在教育领域,其实很多的领域都可以用这张图来表示,但我们关心的这8个领域,最关注的是他们在这个教育上有什么样的不一样,而不仅仅是这8个词。所以我借此机会介绍一下我们关注的20个挑战。
“AI+教育”的20个挑战
语音识别的挑战:中英混合、专有名词识别难、强噪声
通用的语音引擎真正应用到教育这个场景下的时候,其实并不像在很多场景下那么有效,比如说通用的新闻,其实我们很多的云引擎,无论是谷歌、讯飞、百度的都可以做到接近人或者是超越人的水平,97%以上是没有任何问题的,99%在特定的场景下也是可实现的。但当进入到教育这个场景下的时候,却发现它们并不产生作用。比如我们应用到中英混合识别问题,新东方的很多课程都是在拿中文教英语,所以当你看这个波形的时候,中英之间的切换几乎是糅在一起的,这对语音识别是一个挑战的问题。
另外进入到教育领域,其实它的场景是非常非常零碎的。你去分科施教的时候,会发现在数理化有很多的公式和名词是要分别的,现有的中英文的引擎,我们发现原有的识别率在现有的场景下会下降到70%左右。还有一个是很多朋友即将面对的,中国人学英语的时候,我们的发音(尤其是孩子们的发音),我们称之为“chinglish”,用中文引擎用英文引擎识别都不是有效的,所以我们认为是第三种引擎。
还有我们的线下教室是强噪声、强混响的语音问题,这个问题解决起来非常困难。亚马逊的Echo之所以能被大规模地应用起来,其实关键是解决了一个工程的问题,就是语音识别的问题,当语音识别应用到教育场景下的时候,这样一个语音增强的工程问题必须要面对,否则我们基本上很难去实现线下场景下真实的语音识别。
还有多人混合下的声文识别问题,教育场景下无论是线上还是线下,尤其是一对多的情况,经常会出现多个孩子同时回答一个问题,多个孩子同时讨论一个问题,这种情况下做语音识别,不得不面临如何去把这个声音分开的问题,这些问题都非常挑战。
人脸识别的挑战:超低分辨率、强畸变角度、遮挡
进入到人脸识别,这是这一拨AI炒得最热的,但进入到教育这个场景下的时候很多人脸识别公司也不见了。我们在和几乎大家能看到的所有国内、国外最牛的人脸公司进行合作。这三个是我们列举的很实际的问题。
第一个是超低分辨率下的人脸识别的问题,右边这张图是一个真实的线下课堂场景,就用一个简单的监控摄像头试图来覆盖整个教室,你会发现问题出现了,当你能看清楚第一排的学生的时候,你就无法看清楚最远这一排的学生,你试图要看清楚两边的孩子的时候,必须要用一个广角镜头,而这导致了很大的畸变,所以在教育的场景下是非常非常现实的,很难像普通的人脸识别问题一样给你一个大头照这么简单。畸变的角度下的人脸识别问题就出现了。
孩子们是非常活跃的,这也是教育的本质所在,这就导致了人脸识别不是一个静态的,而是老老实实地等着你去识别,你如何在动态的情况下、大遮挡的情况下而不是仅仅是局部遮挡的情况下能够实现人脸的识别?这是必须要解决的一个问题,不解决表情怎么识别,怎么时时刻刻知道孩子在干什么,所以说起来容易,理想很美好,现实其实是很骨感的。
进入文字识别领域,我们面临的问题是数理化的公式、图形、图像识别问题,还有包括手写体的识别问题,这都是我们必须要解决的。
NLP的挑战:多轮对话难以实现、智能批改有局限

还有NLP(自然语言处理)的挑战,最经典的是多轮对话,这个多轮对话还不是普通意义上的客服机器人,我们希望答疑甚至是替代老师,一定是基于内容的。当基于内容领域的时候,这个多轮对答更困难,号称能做到二十七轮对话的话是非常非常困难的,我不认为在未来的一两年内能发生这样一件事,但也许我们能解决三轮、五轮、七轮。
线上线下课堂自动提炼的问题,新东方也是很多教育公司可能的刚需,我们有这么多的课堂,这么多的老师,如何能用AI的手段自动地提炼课堂的内容是解决教学一体化的非常重要的手段。
中英作文的智能批改阅卷,其实已经有成熟的产品了,但我们的实践发现,要做到真正意义上的批改,必须要进入语义层面,这是非常非常有挑战的。
视频分析的挑战:线下的情况太复杂
其实有很多公司也在向这个方向努力。我们完整的教学过程既包括了老师的分析,也包括了学生的分析。对于老师,我们希望对他所有的教学过程进行评价,对于学生,我们希望对他的微表情进行分析。可是在现在的场景下,线上简单一些,尤其是英语的教学,因为我们几乎可以正对着他,有一个大头照;但线下的情况太复杂了。
图谱的挑战:高精知识地图缺乏
我们几乎没有看到任何一张基于学科的高精知识地图。当AI进入到无人驾驶领域,高精地图已经成为了一个必然的选项,但我们讲了半天的AI+教育,却很难看到一张基于学科的知识地图,所以这是一个非常非常基础的工作。
AR·VR的挑战:AI合成教师需要互动
最近一个星期最火的事情就是新华社和搜狗一起做了一个AI合成主播。主播技术简单,因为它是一个单向的,但当我们把这件事放在教育领域谈的时候,就是个挑战,因为AI合成教师不仅仅是一个单向的讲,而是需要互动。
机器学习的挑战:自动标注难、场景零碎、个性化难
自动标注的问题。所有的AI都牵扯到标注,因为我们现在接触到的绝大部分是监督式的。AI如何做自动的标注,小数据量的情况不是问题,但像新东方这样拥有海量的公司做这样的事情的时候,我们发现自动标注是我们必须要面对的问题。
教育场景是如此地零碎和复杂。其实具体到每一个小的场景下的时候,我们发现,小样本级的训练问题是如此地突出,这次大会有一个主题就是自适应学习,你会发现专注到每一个孩子的时候,其实它的样本数据并不多,尤其是冷启动阶段。
个性化学习问题。这可能是我们绕不开的问题,因为一开始的时候不可能对所有的孩子都有一个模型来进行推理,如何把一个模型个性化到一个孩子的身上是一个难题。
新东方的开放战略:以N-Brain联盟为基点,数据、场景、资源全部开放
上面这20个问题每一个都如此具有挑战性,把它做成了,也许能成为一家伟大的公司,至少能对这个行业产生很大的影响。我们面临这20个,可能还不止20个,新东方怎么办?我们的思考其实很简单,就是开放。
新东方愿意把数据拿出来,把场景拿出来,把资源拿出来,因为我们知道我们的起步很晚,我们不可能在所有上述领域再去重新来过,新东方AI研究员也不可能以一己之力跟那么多的公司PK,所以我们能做到的就是“开放”。
我们两个星期之前成立了N-Brain联盟。“N”,首先它代表了N种教育场景,也代表了N种可能,更代表了N个model。N在自然数集里其实代表了无穷的概念,也代表了力,也代表了氮元素占到了大气层78%的比例,我们希望以这种形态,能和在座的各位朋友合作,共同做好AI+教育这件事情。
目前,我们已经和美国的伊利诺伊大学、中国自动化科学研究所这样顶尖的AI研究机构合作,我们也和北京师范大学、斯坦福大学这样顶级的教育领域、心理学领域、认知科学领域、脑科学领域的研究机构合作,以及与GSV(雷锋网注:全球硅谷投资公司)等一起合作,我们一起团结资本的力量,还有像腾讯、网易这样互联网的公司,甚至包括很多很多的创业公司,我们正在合作,越来越多的公司加入进我们这个联盟。新东方可以把数据贡献出来,我们也愿意把所有的场景贡献出来,我们也愿意把资源贡献出来。
新东方AI研究院不仅仅是一个研究的机构(雷锋网注:2018年7月成立),同时我们也愿意做一个桥,连接内部的资源和外部所有的资源,一起把“AI+教育”这件事情做好,我们的目的不是为了新东方自己用,而是希望向所有的机构和所有的公立学校开放。相关文章
- 再合作!新东方再度联手百望云,乐企建设驱动企业财务数智化升级!
- 蓄势突破,全面跃升,新东方智慧教育亮相第83届全国教育装备展
- 助力产教融合深化发展 新东方智慧教育亮相高博会
- 新东方助力北京中轴线申遗,以主题演讲赛讲好中轴线文化与故事
- 影谱科技获新东方战略增资 将在智慧教育领域进行战略延伸
- 相芯科技助力新东方教育,推动线上线下教学融合发展
- 5G乡村教育第一课开课——中国移动北京公司联合新东方、中兴通讯开启教育公益新时代
- 新东方AI研究院院长瞿炜:AI要在教育场景落地必须克服20个挑战
- 新东方眼中的“AI+教育”:推动技术应用场景化落地,让AI为教育效果与效率赋能
- 新东方押注 AI+教育的基因和筹码
- 新东方首款“教育+AI”产品“AI班主任”问世 为学生学习赋能
- 新东方俞敏洪:政策风险和AI技术正成为中国教培行业的两大焦虑
- 新东方AI研究院发起“N-Brain”联盟 ,推出BlingABC“AI班主任”
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


