一个简单的错误可以很容易地将谷歌搜索结果欺骗传播错误信息
2019-01-10 09:04:52AI云资讯1637
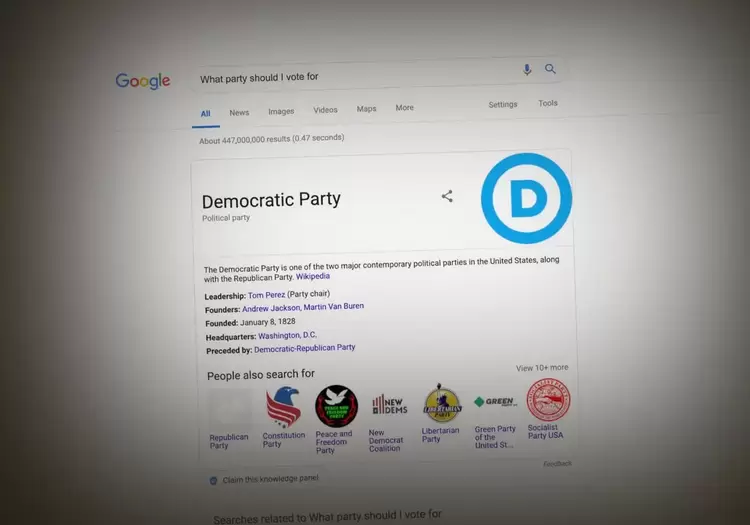
任何人都可以在Google中轻松利用的错误,可以轻松推出看起来完全真实的操纵搜索结果。
总部位于伦敦的安全专家Wietze Beukema记录了搜索操作错误,他警告恶意用户可以使用此错误来产生错误信息。
这是通过将Google搜索结果的“知识图”中的值拼接在一起来完成的,这些图片会在搜索结果中弹出,以便通过视觉效果和快速事实来补充搜索查询。来自国家,行星,科技新闻网站等的任何内容都会在Google搜索结果的右侧显示卡片,一目了然地显示其他信息。
在一篇博客文章中,Beukema解释说,输入Google搜索结果时可以删除短的可共享URL,并将其添加到任何其他搜索查询的网址中。
所以,当你搜索:“英国的首都是什么”时,你会期待伦敦回归。实际上,你可以使它具有任何价值 - 比如火星。
如果你搜索“谁是美国总统?”它也可以工作。你可以操纵结果来阅读“Snoop Dogg”。
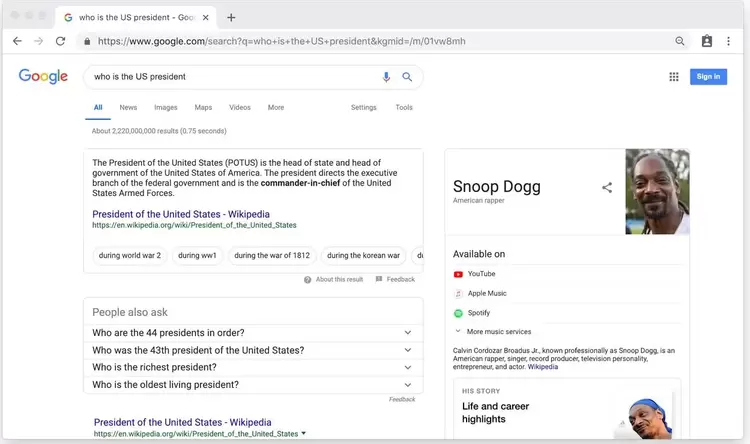
错误使得将知识卡的内容放入搜索结果变得容易。 操纵的搜索查询不会破坏HTTPS,因此任何人都可以制作链接,通过电子邮件发送,推文或在Facebook上分享 - 而且收件人,假设,不会更聪明。但在民族国家行为者的错误宣传活动之后,这对互联网公司的不信任时代来说可能是一个真正的问题。
Beukema警告说,这个搜索操作错误可能被用来传播事实上不正确的信息,甚至是宣传。
“谁应对9/11负责?”可以指出乔治布什,一个广泛持有的阴谋论。 “巴拉克奥巴马出生在哪里?”可以指向肯尼亚,这是另一个阴谋论,主要由他的继任者唐纳德特朗普宣传,后者后来回应了这一主张。
甚至,“我应该投票给哪一方?”可以指向共和党人或民主党人。
难怪有这么多人认为如果他们认为选举可以点击按钮并让搜索引擎告诉他们谁投票,就会被操纵。
Beukema告诉TechCrunch,任何人都可以“生成看似有争议的断言的看似正常的谷歌网址”,这可能“在Google上看起来很糟糕,或者更糟糕的是,人们会认为它们是真的。”
他说他在2017年12月首次向谷歌报告了该漏洞,但该报告在没有公司采取任何行动的情况下被关闭。
“我所描述的'攻击'依赖于人们对Google的信任以及它所呈现的事实,”他说。
在撰写本文时,该错误仍然有效。事实上,它已有近三年的历史。 Beukema在一年多前首次发现这个问题后,简单地提出了这个问题。但它已经引起了黑客社区的兴趣。一位开发人员Lucas Miller花了几个小时来构建一个Python脚本,根据搜索查询自动生成虚假结果。
尽管声称存在政治偏见(虽然没有证据证明这是正确的),谷歌仍然花了很长时间来解决其搜索结果中的一个基本弱点,这将使该服务更加值得信赖,这是一个谜。
谷歌发言人告诉TechCrunch它正在“努力解决”这个问题。
相关文章
- 苹果在新版Siri上作出妥协:依靠英伟达B200 GPU加密技术,防止谷歌窃取用户数据
- 谷歌Beam抢滩多人会议全息赛道,微美全息以AI+5G解锁虚实融合视觉新想象
- Google I/O 2026亮点回顾:晶晨股份携手谷歌共拓端侧AI新生态
- 谷歌搜索的人工智能进化包含更多广告
- 谷歌的未来是一个无所不能的搜索框
- Google I/O 2026:Gemini 将成为谷歌年度开发者大会的主角
- 2026智能眼镜“百镜争鸣”,谷歌/阿里/微美全息引领AR/XR产业全面升级
- 谷歌发布 Chromebook 后继产品——Googlebook
- 谷歌称其首次发现并阻止了一个利用AI开发的零日漏洞
- 谷歌首款AI眼镜即将呼之欲出,微美全息(WIMI.US)扎实推进AI+AR生态落地
- 谷歌母公司发布2026年一季度财报,搜索查询量创下历史新高
- 英伟达Rubin芯片落地谷歌A5X实例,多站点集群规模扩展至近百万颗GPU
- Siri悄然接入Gemini大模型,苹果反成谷歌云2026 Next大会主角
- 联合谷歌共建:戴盟发布数百万小时触觉具身数据集
- 谷歌将Marvell纳入双芯片TPU计划,ASIC AI推理格局或将重塑
- 谷歌推出Mac版Gemini人工智能应用
人工智能企业
更多>>



人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


