码隆科技CurriculumNet:提高噪声数据价值的方法
2018-11-02 11:12:34AI云资讯1577
专注于人工智能技术创新的科技周报Import AI,长期关注并报道科技领域的重要事件。在最近一期周报中,码隆科技自研的CurriculumNet算法在计算机视觉技术创新领域的应用获得了Import AI的关注。

作为数万名业内专家的重要读物,Import AI一直专注于人工智能技术创新领域。其作者Jack Clark为OpenAI现任战略及传播总监,曾任Bloomberg唯一一位专注于神经网络学习领域的记者。OpenAI是众多硅谷大亨联合建立的人工智能非盈利组织,在技术界有广泛影响力。
如下是报道的中文译文:
中国计算机视觉创业公司码隆科技于近期开源了基于弱监督学习的CurriculumNet代码和模型。CurriculumNet是一种可通过从互联网上收集大量带有噪声标签的数据来训练出一个鲁棒性很强的深度神经网络模型技术,这一方法对那些缺少大型已标注数据集的研究人员十分有帮助。但是,这种从互联网上按照标签语义收集来的数据往往带有大量噪声。因此,若要在这些数据上训练出高性能的深度神经网络模型,研究人员需要面临着从噪声中提取足够多有用信息的挑战。
CurriculumNet:研究人员在WebVision数据库上训练他们的模型结构,该数据库包含了超过2,400,000张带有噪声标签的图像。他们的方法是在整个数据集上训练一个Inception_v2模型,之后研究所有图像映射到的特征空间;此后,CurriculumNet将这些图像分组,根据特征空间中所有图像的相似程度将每个类聚成三个子集。接着,他们开始使用具有相似图像特征的子集用于模型训练,再混合到噪声较大的子集中训练。通过高质量的标注数据迭代学习分类器,随后添加具有噪声的数据来加强分类器,研究人员表示这种增加噪声数据训练的方式不仅能提高模型的性能还能增强其泛化能力。
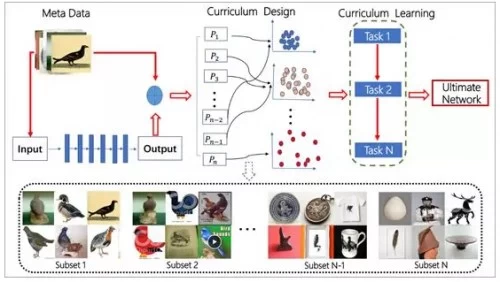
测试效果:研究员用CurriculumNet测试了四个基准:WebVision、ImageNet、Clothing1M和Food101。他们发现,使用最大量的噪声数据训练的系统比那些没有噪声数据训练的系统甚至有着更高的准确度。这一方法使WebVision上的错误率减少了多个百分点(“这些进步对于如此大规模的挑战是至关重要的,”研究人员表示)。更进一步,CurriculumNet在WebVision上的准确度最高,而且训练数据越多(例如结合ImageNet和WebVision的数据集进行训练时),性能越好。
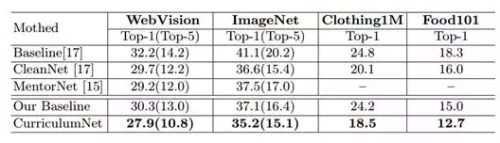
码隆科技在四个公开数据集中的实验结果
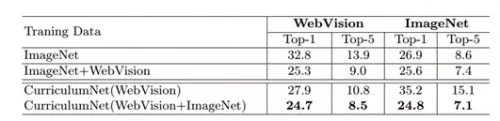
训练模型在WebVision和ImageNet上合集的效果
技术意义:类似于CurriculumNet的系统很好地展示了研究人员可以如何利用标注不佳的数据,结合前沿训练理念来,提高低质量标注数据的价值。这样的方法就类似于在自然资源中提取有用物质时所采取的“萃取”手法,很有现实意义。
相关文章
- CCFA零售创新大会丨码隆科技智慧零售业态详解
- 入选率仅 0.44%,CVPR 2020 码隆科技获最佳论文奖提名
- 微软加速器校友码隆科技携手沃尔玛,以AI赋能零售
- 艾瑞2019中国AI产业研究报告发布,码隆科技商品识别领跑新零售
- 码隆科技亮相HSBC中国研讨会 行业前沿力量共议AI零售未来
- “2018 深圳创新榜”聚焦人工智能,码隆科技蓄力技术落地
- 码隆科技CTO码特:AI发展离不开协同合作
- 码隆科技为联发科新芯片Helio P90提供AI支持
- 码隆科技助力联发科全球首款AI识物芯片P90发布
- 码隆科技荣获36氪“新经济之王——人工智能图像识别奖”
- 丰元资本吴军与码隆科技黄鼎隆,对话第四次工业革命
- 伯尔尼大学-码隆科技智能医疗联合实验室正式启动
- 码隆科技亮相机器智能大会 前沿力量共议AI未来
- 世界互联网大会人工智能分论坛,码隆科技展望AI打造智能“龙骨”
- 埃森哲全球创新研发中心启动 码隆科技受邀共谈AI未来发展
- 码隆科技CurriculumNet:提高噪声数据价值的方法
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


