谷歌用新的语音数据扩增技术大幅提升语音识别准确率
2019-04-24 16:12:55AI云资讯1314
当对于图像分类任务,当训练数据的数量不足的时候我们可以使用各种数据扩增(dataaugmentation)方法生成更多数据,提高网络的表现。但是在自动语音识别任务中情况有所不同,传统的数据扩增方法一般是对音频波形做一些变形(比如加速、减速),或者增加背景噪声,都可以生成新的训练数据,起到把训练数据集变大的效果,帮助网络更好地学习到有用的特征。不过,现有的传统音频数据扩增方法会带来明显的额外计算能力开销,有时也避免不了需要使用额外的数据。
在谷歌 AI 的近期论文《SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition》(SpecAugment:一个用于自动语音识别的简单数据扩增方法,https://arxiv.org/abs/1904.08779)中,谷歌的研究人员们提出了一种扩增音频数据的新方法,主要思路是把它看做是一个视觉问题而不是音频问题。具体来说,他们在 SpecAugment 不再直接使用传统的数据扩增方法,而是在音频的光谱图上(音频波形的一种视觉表示)施加扩增策略。这种方法简单、计算力需求低,而且不需要额外的数据。它能非常有效地提高语音识别系统的表现。雷锋网 AI 科技评论根据谷歌技术博客介绍如下。
新的音频数据扩增方法 SpecAugment
对于传统语音识别系统,音频波形在输入网络之前通常都需要编码为某种视觉表示,比如编码为光谱图。而传统的语音数据扩增方法一般都是在编码为光谱图之前进行的,这样每次数据扩增之后都要重新生成新的光谱图。在这项研究中,作者们尝试就在光谱图上进行数据扩增。由于直接作用于网络的输入特征,数据扩增过程可以在网络的训练过程中运行,而且不会对训练速度造成显著影响。
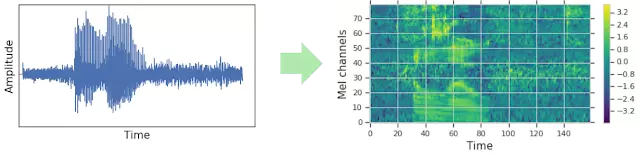
音频波形(时间-振幅)关系转化为梅尔频谱图(时间-梅尔频率),然后再输入网络
SpecAugment 对光谱图的修改方式有:沿着时间方向扭曲,遮蔽某一些频率段的信号,以及遮蔽某一些时间段的发音。作者们选择使用的这些扩增方式可以帮助网络面对时间方向的变形、部分频率信号的损失以及部分时间段的信号缺失时更加鲁棒。这些扩增策略的示意图如下。
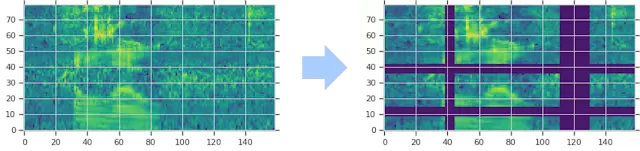
图中的梅尔频谱图经过了时间方向扭曲、多个频率段信号遮蔽(横条)以及多个时间段遮蔽(纵向条)。图中的遮蔽程度有所夸张。
作者们在LibriSpeech 数据集上用实验测试了SpecAugment 的效果。他们选取了三个语音识别常用的端到端 LAS 模型,对比使用数据扩增和不使用数据扩增的网络表现。自动语音识别模型表现的测量指标是单词错误率(WER),用模型输出的转录文本和标准文本对比得到。在下面的对比试验中,训练模型使用的超参数不变、每组对比中模型的参数数量也保持固定,只有训练模型用的数据有区别(使用以及不使用数据扩增)。试验结果表明,SpecAugment 不需要任何额外的调节就可以提高网络的表现。
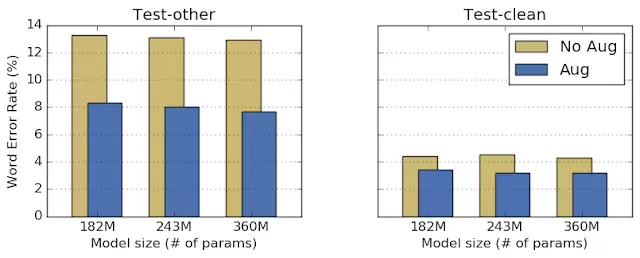
在LibriSpeech 数据集上的测试中,每组测试中经过数据增强(蓝色条)都取得了更低的单词错误率。Test-other 数据集含有噪声,Test-clean 数据集不含有噪声
更重要的是,由于 SpecAugment 扩增后的数据里有故意损坏的部分,这避免了模型过拟合到训练数据上。作者们进行了对比试验如下,未使用数据扩增的模型(棕黄色线)在训练数据集上取得了极低的单词错误率,但是在 Dev-other(有噪声测试集)和 Dev-clean(无噪声数据集)上的表现就要差很多;使用了数据扩增的模型(蓝色线)则正相反,在训练数据集上的单词错误率较高,然后在Dev-other 和 Dev-clean 上都取得了优秀的表现,甚至在 Dev-clean 上的错误率还要低于训练数据集上的错误率;这表明 SpecAugment数据扩增方法不仅提高了网络表现,还有效防止了过拟合的发生。
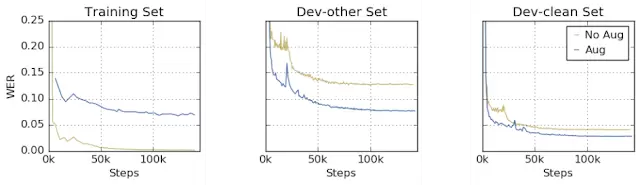
借助SpecAugment 取得前所未有的模型表现
由于SpecAugment 可以带来没有过拟合的表现提升,研究人员们甚至可以尝试使用更大容量的网络,得到表现更好的模型。论文作者们进行了实验,在使用 SpecAugment 的同时,使用参数更多的模型、更长的训练时间,他们分别在LibriSpeech 960h和 Switchboard 300h 两个数据集上都大幅刷新了此前的最佳表现记录(SOTA)。

作者们也为这种方法的出色表现感到惊讶,甚至于,以往在 LibriSpeech和 Switchboard 这样较小的数据集上有优势的传统语音识别模型也不再领先。

借助语言模型再上一层楼?甚至都不需要
自动语音识别模型的表现还可以通过语言模型进一步提高。在大量纯文本数据上训练出的语言模型可以学到一些语言规律,然后用它来更正、优化语音识别模型的输出。不过,语言模型通常需要独立于语音识别模型训练,而且模型的体积很大,很难在手机之类的小型设备上使用。
在SpecAugment 的研究中,作者们意外发现借助SpecAugment 训练的模型,在不使用语言模型增强的情况下就已经可以击败之前的所有使用语言模型增强的模型。这不仅意味着语音识别模型+语言模型的总体表现也被刷新,更意味着未来语音识别模型完全可以抛弃语言模型独立工作。
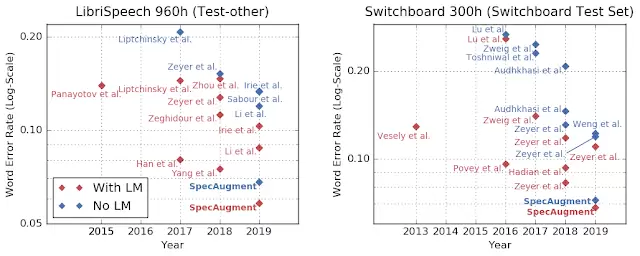
以往的自动语音识别系统研究多数都关注于找到更好的网络结构,谷歌的这项研究也展现了一个被人忽略的研究方向:用更好的方法训练模型,也可以带来大幅提升的网络表现。
相关文章
- 苹果在新版Siri上作出妥协:依靠英伟达B200 GPU加密技术,防止谷歌窃取用户数据
- 谷歌Beam抢滩多人会议全息赛道,微美全息以AI+5G解锁虚实融合视觉新想象
- Google I/O 2026亮点回顾:晶晨股份携手谷歌共拓端侧AI新生态
- 谷歌搜索的人工智能进化包含更多广告
- 谷歌的未来是一个无所不能的搜索框
- Google I/O 2026:Gemini 将成为谷歌年度开发者大会的主角
- 2026智能眼镜“百镜争鸣”,谷歌/阿里/微美全息引领AR/XR产业全面升级
- 谷歌发布 Chromebook 后继产品——Googlebook
- 谷歌称其首次发现并阻止了一个利用AI开发的零日漏洞
- 谷歌首款AI眼镜即将呼之欲出,微美全息(WIMI.US)扎实推进AI+AR生态落地
- 谷歌母公司发布2026年一季度财报,搜索查询量创下历史新高
- 英伟达Rubin芯片落地谷歌A5X实例,多站点集群规模扩展至近百万颗GPU
- Siri悄然接入Gemini大模型,苹果反成谷歌云2026 Next大会主角
- 联合谷歌共建:戴盟发布数百万小时触觉具身数据集
- 谷歌将Marvell纳入双芯片TPU计划,ASIC AI推理格局或将重塑
- 谷歌推出Mac版Gemini人工智能应用
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


