Socionext联手大阪大学合作开发新型深度学习算法
2020-08-28 15:54:20AI云资讯1098
近年来尽管计算机视觉技术取得了飞速发展,但在低照度环境下车载摄像头、安防系统等获取的图像质量仍不理想,图像辨识性能较差。不断提升低照度环境下图像识别性能依旧是目前计算机视觉技术面临的主要课题之一。CVPR2018中一篇名为《Learning to See in the Dark》[1]的论文曾介绍过利用图像传感器的RAW图像数据的深度学习算法,但这种算法需要制作超过200,000张图像和150多万个批注 [2]数据集才能进行端到端学习,既费时又费钱,难以实现商业化落地(如下图1)。
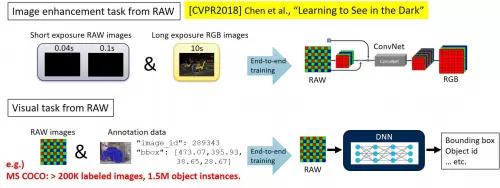
图1:《Learning to See in the Dark》及RAW 图像识别课题
为解决上述课题,Socionext与大阪大学联合研究团队通过迁移学习(Transfer Learning)和知识蒸馏(Knowledge Distillation)等机器学习方法,提出采用领域自适应(Domain Adaptation)的学习方法,即利用现有数据集来提升目标域模型的性能,具体内容如下(如图2):
(1)使用现有数据集构建推理模型;
(2)通过迁移学习从上述推理模型中提取知识;
(3)利用Glue layer合并模型;
(4)通过知识蒸馏建立并生成模型。
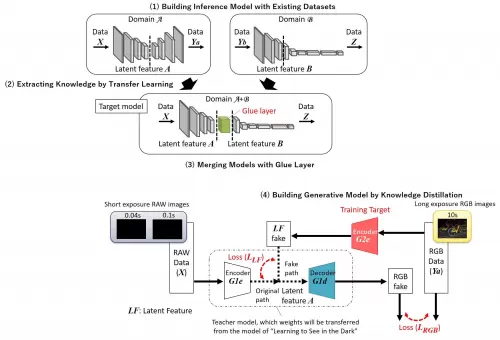
图2:本次开发的领域适应方法(Domain Adaptation Method)
此外,结合领域自适应方法和物体检测YOLO模型[3],并利用在极端弱光条件下拍摄的RAW图像还可构建“YOLO in the Dark”检测模型。YOLO in the Dark模型可仅通过现有数据集实现对RAW图像的对象检测模型的学习。针对那些通过使用现有YOLO模型,校正图像亮度后仍无法检测到图像的(如下图a),则可以通过直接识别RAW图像确认到物体被正常检测(如下图b)。同时测试结果发现,YOLO in the Dark模型识别处理时所需的处理量约为常规模型组合(如下图c)的一半左右。

图3:《YOLO in the Dark》效果图
本次利用领域自适应法所开发的“直接识别RAW图像”可不仅应用于极端黑暗条件下的物体检测,还可应用于车载摄像头、安防系统和工业等多个领域。未来,Socionext还计划将该技术整合到公司自主研发的图像信号处理器(ISP)中开发下一代SoC,并基于此类SoC开发全新摄像系统,进一步提升公司产品性能,助力产业再升级。
相关文章
- HD-PLC最新应用案例! Socionext通信芯片助力打造智慧城市再添新亮点!
- 面向车载毫米波雷达市场,Socionext究竟有何“利器”?
- Socionext推出全新60GHz超小型低功耗车载毫米波雷达
- Socionext推出适用于5G Direct-RF收发器应用的7nm ADC/DAC
- Socionext高端车载定制化SoC闪耀美国CES2023
- 革新践行 再聚ICCAD—Socionext携创新科技亮相ICCAD2022
- Socionext再获2022年度中国IC设计成就奖之年度杰出IC设计服务公司
- Socionext成功开发第四代车载显示控制器
- Socionext荣获第73届年度技术与工程艾美奖
- Socionext 和日本东北大学显著加快基于深度学习的 SLAM 处理
- Socionext为下一代云标签开发LSI 加速物流数字化转型
- Socionext和合作伙伴发表由宇宙射线介子和中子引起的半导体软误差之间的差异
- Socionext 在DesignCon 2021展示领先的SoC设计解决方案
- Socionext与多家公司合作 开发下一代远距离电力线通信LSI
- 新基建时代下,Socionext用“芯”助推5G加速发展
- Socionext联手大阪大学合作开发新型深度学习算法
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


