CVPR 2021 | 腾讯优图20篇论文入选,含人脸识别、时序动作定位、视频动作分割等领域
2021-03-11 08:55:22AI云资讯1452
计算机视觉世界三大顶会之一的CVPR2021论文接收结果出炉!本次大会收到来自全球共7015篇有效投稿,最终有1663篇突出重围被录取,录用率约为23.7%。本次,腾讯优图实验室共有20篇论文被收录,其中Oral论文4篇,涵盖人脸识别、对抗攻击、时序动作定位、视频动作分割、无监督人脸质量评估等前沿领域。
01
基于超球流形置信度学习的人脸识别
Spherical Confidence Learning for Face Recognition
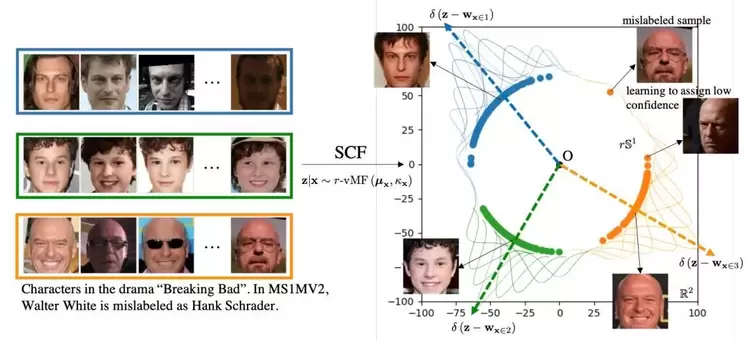
本论文已被CVPR 2021接收为Oral论文。最新的研究发现,球形空间可以更好地匹配人脸图像的基本几何形状,这一点已经在目前最先进的人脸识别方法中得到证实。然而,这些方法依赖于确定性的特征表达,因此会遇到特征歧义性的表达难题。PFE是解决这一难题的首次尝试。为了进一步解决PFE应用时的不足,我们提出了一种用于球形空间中人脸置信度学习的新颖框架。在数学上,我们将von Mises Fisher密度推广到其r半径对应项,并导出优化目标的闭式解。我们从理论上表明,所提出的框架具有更好的可解释性,进一步推导出了特征融合与特征比对的数学表达式。在多个具有挑战性的基准上广泛的实验结果证实了我们的假设和理论,并展示了我们的框架在风险控制的识别任务以及人脸验证和识别任务中相对于先前的概率方法和常规球形确定性嵌入的优越性能。
02
在开放的人像集合中学习3D人脸的聚合与特异化重建
Learning to Aggregate and Personalize 3D Face from In-the-Wild Photo Collection
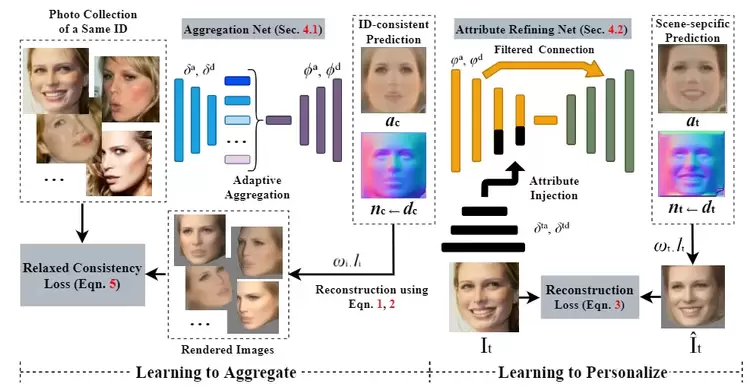
本论文已被CVPR 2021接收为Oral论文。非参数化的人脸建模旨在不依赖几何假设的情况下从图像中重建3D人脸。尽管这类方法能够预测一定的细节,但其倾向于过度依赖局部颜色表观,且易受到噪声的干扰。为处理该问题,本文提出一种新的聚合与特异化学习框架(LAP)以实现无监督的3D人脸建模。该方法从无约束的人像集合中隐式的解耦ID一致和场景特异的人脸。具体地,为学习ID一致人脸,LAP基于一种新的带有松弛一致性损失的课程学习方法,自适应地聚合同一身份的本征人脸元素。为了使人脸适应于某一特异的场景,我们提出了一个新的属性调整网络以使用目标属性和细节修改ID一致人脸。基于本文的方法,使得无监督的3D人脸受益于有意义的人脸结构信息和更高的分辨率。在公开数据库上的大量实验表明,与当前最优方法相比,LAP可以重建更好的或有竞争力的人脸几何和纹理。
03
在图像到图像翻译上实现层次风格解耦
Image-to-image Translation via Hierarchical Style Disentanglement
本论文已被CVPR2021接收为Oral论文。近年来,图像到图像翻译在实现多标签(以不同标签作为条件)和多风格(生成多种样式的输出)任务中都取得了重大进展。但是,由于未开发标签中的独立性和排他性导致的翻译结果不可控导致了这些方法的失败。在本文中,我们提出了层次风格解耦(HiSD)来解决此问题。具体来说,将标签重新排列成分层的树状结构,从上到下依次是独立的标签,互斥的属性和解耦的风格。相应地,我们设计了一种新的翻译过程来适应上述结构,将风格与特定标签或属性对应起来,实现可控的翻译。CelebA-HQ数据集上的定性和定量结果都证明了HiSD的能力。我们希望我们的方法将作为层次风格解耦的基准,帮助未来的图像到图像翻译的研究。
04
基于特征校准的表征批规范化方法
Representative Batch Normalization with Feature Calibration
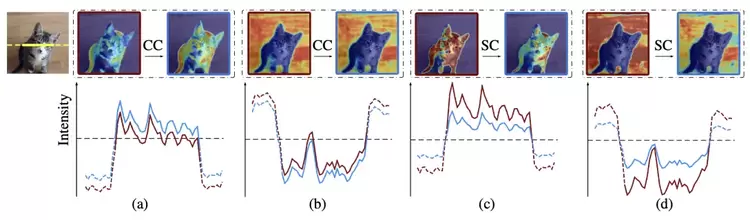
本论文已被CVPR2021接收为Oral论文。批规范(BatchNorm,简称BN)已经被视为神经网络训练的默认组件之一,尽管BN是有益于稳定模型训练以及模型的整体表征能力,但是也不可避免地忽视了训练数据个体之间的特征差异。我们提出了一个简单有效的特征校准策略用来增强数据个体的特征表达能力,并几乎不增加额外的耗时。我们提出的这个中心校准方法可以增强有效的特征信息,而减少噪声特征。缩放校准方面,则能够通过约束特征强度以学习得到一个更加稳定的特征分布。我们将上述提出的BN变种方法,命名为Representative BN,这一方法能够帮助提升多种计算机视觉任务的效果,如分类、检测和分割等。
05
基于对比学习的紧凑图像去雾方法
Contrastive Learning for Compact Single Image Dehazing
本文提出了一种基于对比学习的新颖对比正则化(CR)技术,以利用模糊图像和清晰图像的信息分别作为负样本和正样本。CR确保在表示空间中将还原后的图像拉到更接近清晰图像,并推到远离朦胧图像的位置。
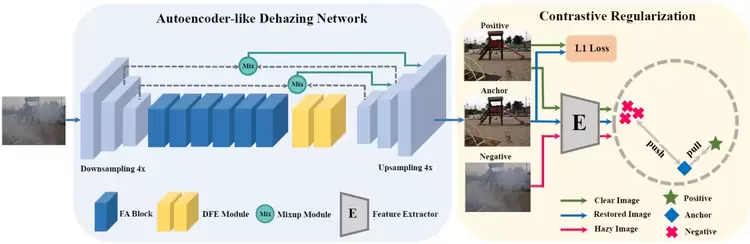
此外,考虑到性能和内存存储之间的权衡,开发了一个基于类自动编码器(AE)框架的紧凑型除雾网络,可分别受益于自适应地保存信息流和扩展接收域以提高网络的转换能力。将具有自动编码器和对比正则化功能的除雾网络称为AECR-Net,在合成和真实数据集上进行的广泛实验表明,我们的AECR-Net超越了最新技术。
06
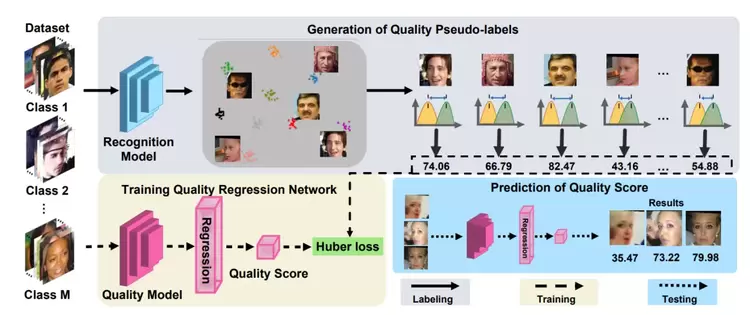
基于相似度分布距离的无监督人脸质量评估
SDD-FIQA: Unsupervised Face Image Quality Assessment with Similarity Distribution Distance
近年来为了确保非受限场景的稳定性和可靠性,人脸质量评估(Face Image Quality Assessment, FIQA)已经成为人脸识别系统不可或缺的一部分。这种方式只使用了类内信息,而忽略了类间信息。在本工作中,我们认为高质量的人脸应该与其类内样本相似并与其他样本不相似,因此提出了一种新的无监督FIQA方法,该方法结合了相似分布距离进行人脸图像质量评估(SDD-FIQA)。我们通过计算正负样本相似度分布间的Wasserstein距离生成高质量的伪标签,并以此训练用于质量预测的回归网络。实验结果表明,我们提出的SDD-FIQA显著超过了SOTA方法。同时,我们的方法在不同的识别系统上显示出良好的泛化性。后续我们将开源该工作。
07
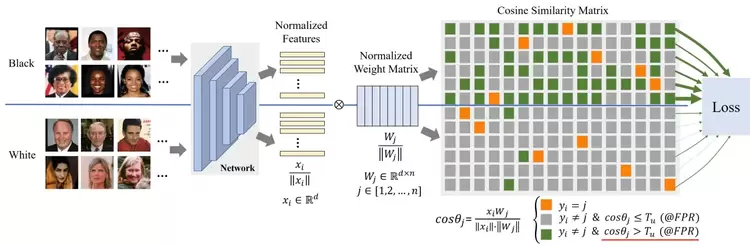
基于实例误报一致性的人脸识别公平性提升方法
Consistent Instance False Positive Improves Fairness in Face Recognition
人群偏差是实际人脸识别系统中的重大挑战。现有方法严重依赖准确的人群标签,还不够通用。于是,我们提出了基于误报率惩罚的损失函数,它通过增加实例误报率(FPR)的一致性来减轻人脸识别偏差。具体来说,我们首先将实例FPR定义为高于统一阈值的非目标相似度数量与非目标相似度总数之间的比率。通过给定总FPR,可以估计出统一阈值,然后将实例FPR与总FPR的比例惩罚项引入基于softmax的损失函数分母中。实例FPR越大,惩罚越大。利用这种不平等性的惩罚,使得实例FPR具有一致性。该方法不需要人群标签,并可减轻群体之间因各种属性划分的偏差,而这些属性在训练中无需预先定义,在主流实验基准上的广泛测试结果表明,此方法已达到了SOTA。
08
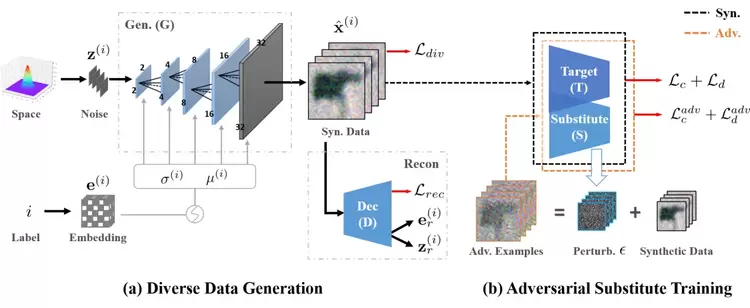
基于高效训练替代模型的黑盒攻击方法
Delving into Data: Effectively Substitute Training for Black-box Attack
在处理对抗样本时,深度神经网络显得非常敏感,容易输出错误的预测结果。而在黑盒攻击中,攻击者并不知道被攻击目标模型的内部结构和权重,因此训练一个替代模型去模拟目标模型内部结构就是一种非常高效的方法。
在本文,我们提出了一个全新的替代模型训练方法,即在替代模型训练过程中引入更好的数据分布。首先是提出的多样性,更加多样性的训练数据分布可以获取更加丰富的特征表述;其次,提出一个对抗替换模型训练框架,将分布在分界面的对抗样本引入到替代模型训练过程中。通过结合两种思路,可以进一步提升替代模型和目标模型之间的相似性,从而提升黑盒攻击的成功率。实验结果表明,我们的方法达到了SOTA,相关的可视化结果也证明了所提出方法的优势。
09
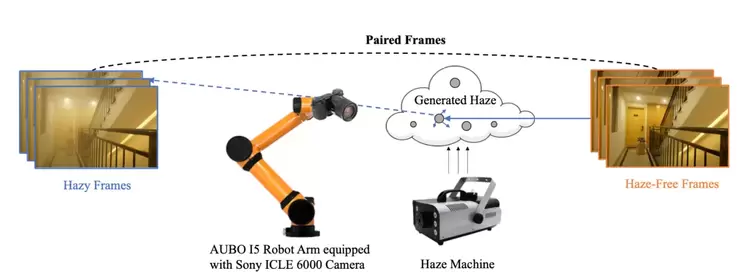
学习复原有雾视频:一种新的真实数据集及算法
Learning to Restore Hazy Video: A New Real-World Dataset and A New Method
现有的深度学习去雾方法多采用单帧去雾数据集进行训练和评测,从而使得去雾网络只能利用当前有雾图像的信息恢复清晰图像。另外一方面,理想中的视频去雾算法却可以使用相邻的有雾帧来获取更多的时空冗余信息,从而得到更好的去雾效果,但由于视频去雾数据集的缺失,视频去雾算法鲜有研究。
为了实现视频去雾算法的监督训练,我们首次提出了一组真实的视频去雾数据集(REVIDE)。使用精心设计的视频采集系统,成功地在同一场景进行两次采集,从而同时记录下真实世界中成对且完美对齐的有雾和无雾视频。考虑到获取有雾视频帧间时空冗余信息的挑战性,我们还设计了一个由置信度引导的改进型可变形卷积网络(CG-IDN)来处理有雾视频。实验证明,REVIDE数据集中采集的有雾场景远比合成雾更为贴近真实场景,并且我们提出的方法也优于现有的各种去雾算法。
10
基于显著边界特征学习的无锚框时序动作定位
Learning Salient Boundary Feature for Anchor-free Temporal Action Localization
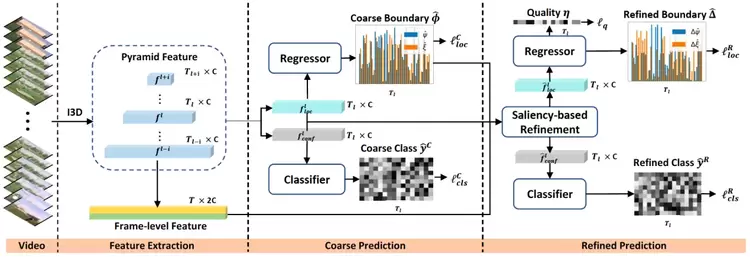
时序动作定位在视频理解中仍然是一个备受挑战的任务。该任务的目的是在一个未剪辑且较长的视频中找到每个动作的起始与结束时间,以及改动作的分类结果。和预设锚框或者枚举分数的方式对比,无锚框的方法无需依赖一些冗余的超参数,显得更轻量。
因此,我们提出了第一个高效高性能且完全无锚框的时序动作定位方法。模型包括:(1) 端到端可训练的基础预测器;(2) 基于显著性优化的模块,该模块通过一种新颖的边界池化方法去为每个时序动作提名获取更有价值的边界特征;(3) 使用边界一致性约束来保证我们的模型能够找到精准的边界信息。另外,在THUMOS14数据集上,该方法相比于之前基于锚框或运动分数指导的方法在性能上有显著的提升,在ActivityNet v1.3数据集上也取得了最好的结果。
11
通过添加背景来去除背景影响:背景鲁棒的自监督视频表征学习
Removing the Background by Adding the Background: Towards a Background Robust Self-supervised Video Representation Learning
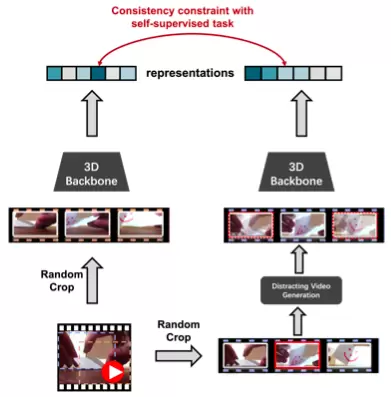
自监督学习通过从数据本身来获取监督信号,在视频表征学习领域展现出了巨大潜力。由于一些主流的方法容易受到背景信息的欺骗和影响,为了减轻模型对背景信息的依赖,我们提出通过添加背景来去除背景影响。具体而言,给定一个视频,我们从中随机选择一个静态帧,并将其添加到其它的每一帧中,以构建一个分散注意力的视频样本,然后要求模型拉近分散注意力的视频样本与原始视频样本之间的特征距离,如此使得模型能够更好地抵抗背景的影响,而更多地关注运动变化。我们的方法命名为背景消除(BackgroundErasing,BE)。值得注意的是,我们的方法可以便捷地添加到大多数SOTA方法中。BE在MoCo的基础上,对具有严重背景偏见的数据集UCF101和HMDB51,分别带来了16.4%和19.1%的提升,而对具有较小背景偏见的数据集Diving48数据集带来了14.5%的提升。
12
基于自监督三维重建和重投影的纹理不敏感行人重识别
Self-supervised 3D Reconstruction and Re-Projection for Texture Insensitive Person Re-identification
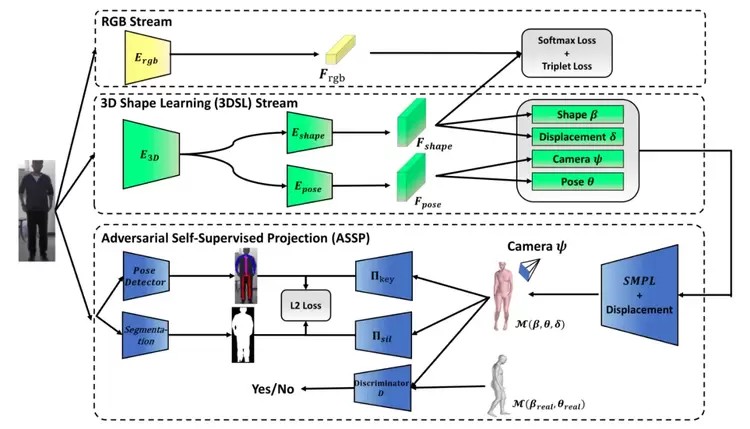
众所周知,行人重识别(PersonReID)高度依赖于服装纹理等视觉信息。但是,实际应用中存在多种纹理混淆的情况,这超出了大多数现有ReID方法的能力范围。因此,我们提出利用人的三维形状和身材信息来提高ReID对纹理混淆的鲁棒性,而不仅依赖于图像纹理信息。现有的personReID使用的形状学习模型要么忽略了人的真实三维信息,要么需要额外的物理设备来采集三维源数据。在本文中,我们提出了一种新颖的学习框架,即结合三维形状学习(3DSL)模型:加入三维人体重建作为正则化,直接从二维图像中提取纹理不敏感的3D模型编码信息。基于正则化的三维重建迫使ReID模型将三维形状信息从视觉纹理中解耦,获得具有判别性的三维形状ReID特征。为了解决缺乏三维ground truth的问题,我们提出了一种对抗式自我监督投影(ASSP)方法以拟合不需要ground truth监督训练的三维重建模块。在通用ReID数据集和纹理混淆数据集上的大量实验验证了我们模型的有效性。
13
基于结构信息保持的弱监督目标定位
Unveiling the Potential of Structure-Preserving for Weakly Supervised Object Localization
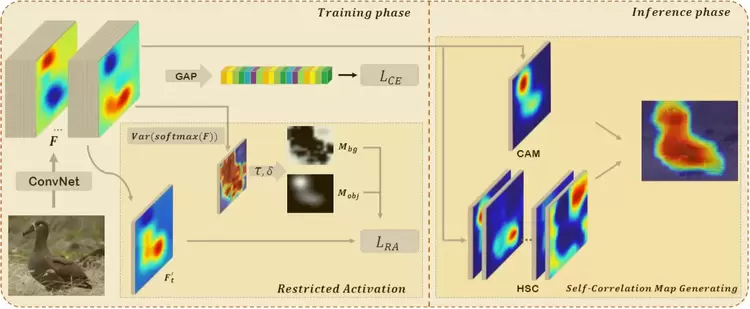
由于仅使用分类任务对目标进行定位的不足,弱监督目标定位(WSOL)仍然存在一些挑战。已有的工作通常利用空间正则化策略提高目标定位精度,但往往忽略了如何从训练好的分类网络中提取目标结构信息。
本文提出了一种两阶段的方法,称为结构保持激活(SPA),以充分利用WSOL卷积特征中包含的结构信息。在第一阶段,设计了受限激活模块(RAM)来缓解由分类网络引起的结构缺失问题。该模块基于观察:无约束的分类激活图和全局平均池化层导致网络仅关注目标的局部区域。在第二阶段,提出了一种称为自相关图生成(SCG)模块的后处理方法,基于第一阶段获取的激活图获得结构保持的定位图。具体地,我们利用高阶自相关(HSC)提取保留在模型中的固有结构信息,之后聚合多个位置的HSC得到精确的目标定位结果。在包括CUB-200-2011和ILSVRC在内的两个公开基准上进行的大量实验表明,与基准方法相比,本文提出的SPA方法取得了显著的性能提升。
14
RSTNet: 基于可区分视觉词和非视觉词的自适应注意力机制的图像描述生成模型
RSTNet: Captioning with Adaptive Attention on Visual and Non-Visual Words
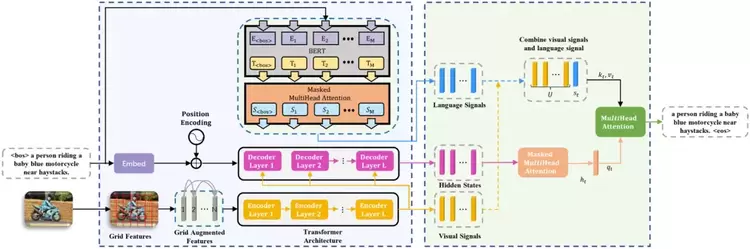
本文提出了一个视觉信息增强和多模态信息敏感的Transformer结构,利用网格与网格之间相对位置的几何关系解决了特征展平操作造成的空间信息损失的问题,并且利用一个额外的注意力层度量视觉特征与语义特征的贡献,从而充分引导图像描述中视觉词和非视觉词的生成,在该任务的线上线下公开数据集上均证明了此模型的优势。
15
联合物体和物质挖掘的弱监督全景分割
Toward Joint Thing-and-Stuff Mining for Weakly Supervised Panoptic Segmentation
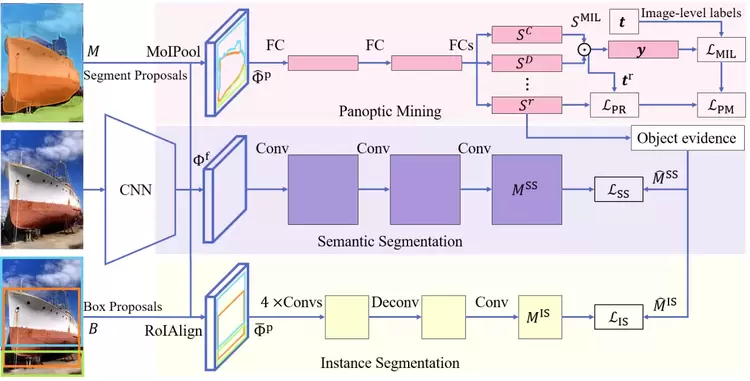
全景分割旨在将图像分别分割为物体类别的目标实例和物质类别的语义内容。这种复杂的全场景解析任务需要昂贵的实例级和像素级注释来进行模型训练。迄今为止,仅用图像级标签学习的基于弱监督学习的全景分割(WSPS)仍未被探索。
本文为弱监督全景分割提出了一个有效的联合物体与物质挖掘(Jointly Thing-and-Stuff Mining, JTSM)框架,明确地推理了目标前景和物质背景之间的语义和共现关系。为此,算法设计了一种新颖的感兴趣掩模池化(Mask of Interest Pooling, MoIPool),用于提取任意形状分割的固定尺寸的像素精确特征图。MoIPool使全景挖掘分支能够利用多实例学习(Multiple Instance Learning, MIL),并以统一的方式识别物体和物质。算法引入并行实例和语义分割分支,通过自训练进一步修正的分割掩模,其让从全景挖掘中挖掘的掩模和以自底向上的目标线索协作生成伪真实标签,以提高空间一致性和轮廓定位。
16
基于Transformers 从序列到序列的角度重新思考语义分割
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
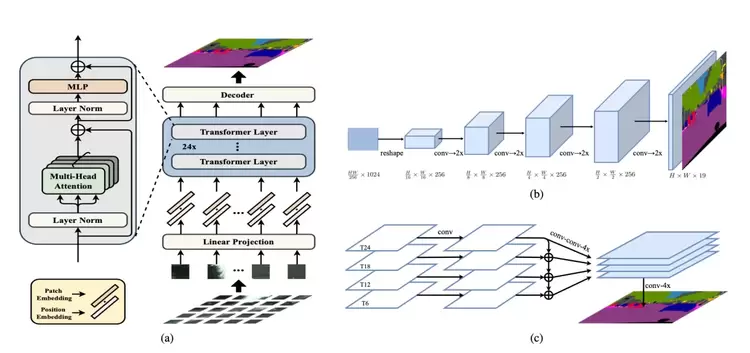
我们希望为语义分割方法提供另一种思路,将语义分割转变为序列到序列的预测任务。在本文中,我们使用transformer(不使用卷积和降低分辨率)将图像编码为一系列patch序列。transformer的每一层都进行了全局的上下文建模,结合常规的Decoder模块,我们得到了一个强大的语义分割模型,称之为Segmentation transformer(SETR)。大量实验表明,SETR在ADE20K(50.28%mIoU),Pascal Context(55.83%mIoU)上达到SOTA,并在Cityscapes上取得了较好结果。
17
通过元卷积核实现基于动态对齐的小样本学习
Learning Dynamic Alignment via Meta-filter for Few-shot Learning
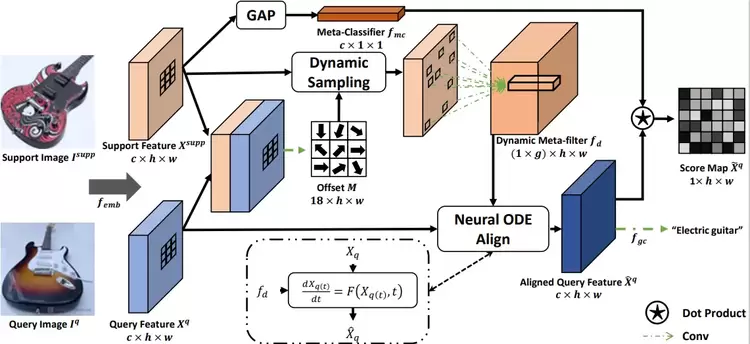
小样本学习(FSL)旨在通过利用极为有限的支持集样本来适应所学知识,从而识别新的样本,是计算机视觉中的一个重要开放问题。小样本学习中用于特征对齐的大多数现有方法仅考虑图像级或空间级对齐,而忽略了通道差异。
在本文,我们提出了一种动态对齐方式,可根据不同的本地支持信息有效地突出显示查询区域和渠道。具体而言,这是通过首先动态采样以输入的少量镜头为条件的特征位置的邻域来实现的,基于此,我们可以进一步预测依赖于位置和依赖于通道的动态元滤波器用于将查询功能与特定于位置和特定于通道的知识对齐。此外,我们采用神经网络常微分方程(Neural ODE)来实现更精确的对齐控制。通过上述方法,我们的模型能够更好地捕获支持集样本的的细粒度上下文语义。
18
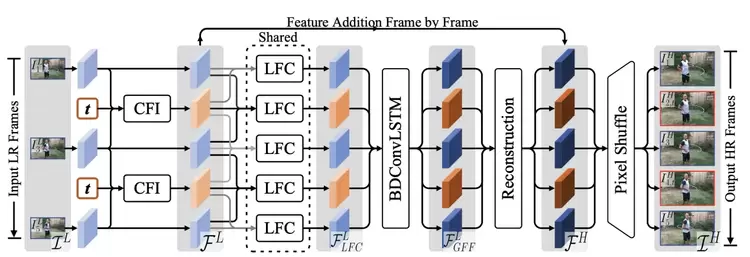
基于时空特征可控插值的视频超分辨率网络
Temporal Modulation Network for Controllable Space-Time Video Super-Resolution
在本文,我们提出了一种称之为TMNet的时间建模网络,该模型能够对视频中间帧任意插值高分辨率帧。具体而言,我们提出了TMB模块用以调节可变形卷积作用在可控特征插值中。为了更好的挖掘时间信息,我们还提出了一个基于局部特征比对的LFC模块,该模块与双向可变形ConvLSTM模块一同作用,用以提取视频中的短时和长时运动信息。在3个权威标准数据集上我们提出的方法都比过去STVSR方法在效率和效果上都要更加好,文中的消融实验比对进一步验证了我们创新点的贡献。
19
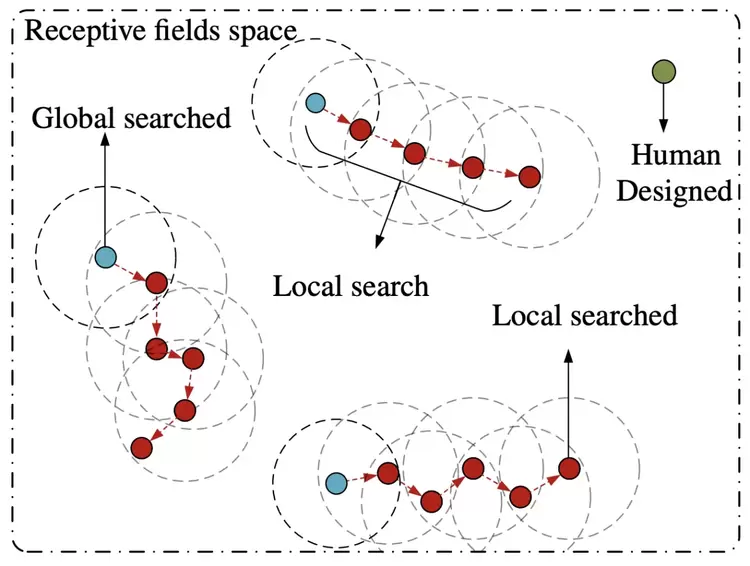
从全局到局部:面向视频动作分割的高效网络结构搜索
Global2Local: Efficient Structure Search for Video Action Segmentation
为了回答“是否可以通过高效地搜索不同感受野的之间的组合来替代手工设计的模式呢?”的问题,在本文中,我们提出一种基于从全局到局部的搜索策略来寻找更合适的感受野组合。具体而言,我们的搜索策略将利用全局搜索的优势来找到粗粒度的参数组合,而后在利用局部搜索来精细化感受野的组合模式。值得指出的是,全局搜索并非是通过手工设计模式来寻找潜在的粗粒度参数组合。在全局搜索的基础上,我们将会使用一种基于期望引导迭代的方式来有效地精修参数组合。最后,我们的这一结果可以即插即用地使用在当前动作分割的模型中,并取得了SOTA的效果。很快我们也将开源我们的代码实现。
20
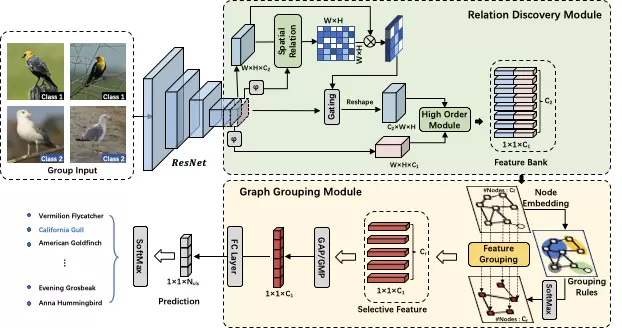
基于特征间高阶关系挖掘的细粒度识别方法
Graph-based High-Order Relation Discovery for Fine-grained Recognition
细粒度识别的主要目的是通过学习类别间区分性特征表达来分辨表观高度相似对象,但一般情况下,现有的大多数工作在背景复杂下效果不稳定,且忽略了不同语义特征之间的内在联系。对此,我们提出一种高效的基于图的关系挖掘方法来构建高阶关系间的上下文理解。该方法首先通过特征间语义和位置感知来构建高维特征库(feature bank),同时进行正则化约束。其次本文提出一种基于图的语义分组方法(graph grouping),将高维特征映射到低维空间中,保留其中高区分性特征。在训练过程中,本文还提出一种分组学习策略(group-wise learning),对特征聚类中心进行约束。通过以上三个模块的协作,该方法可学习到细粒度类别间更丰富的区分性信息。实验结果表明,该方法在4个细粒度数据集上均超过SOTA。
CVPR 作为计算机视觉领域的顶会之一,每年录取的论文几乎都代表了本年度计算机视觉领域最新、最高科研水平以及未来发展趋势。
此次入选了20篇论文,也是对腾讯优图实验室现阶段科研及创新能力的一种认可。未来,优图将继续努力,为大家带来更多可能的“视”界。
相关文章
- SOTA达成!腾讯优图D-Search算法登顶国际AI权威榜单
- PRCV2025大会顺利召开,腾讯优图携前沿科技成果亮相现场
- 腾讯优图携Youtu-Agent开源项目亮相上海创智学院首届TechFest大会
- 拿下SOTA!腾讯优图联合厦门大学提出AIGI生成图像检测新方法
- Interspeech 2025 | 腾讯优图实验室4篇论文入选,涵盖超声波活体检测、神经语音编解码、语音合成等方向
- ICCV 2025 | 腾讯优图实验室大模型8篇论文入选,涵盖风格化人脸识别、AI生成图像检测、多模态大语言模型等方向
- 最高10倍加速!北京大学联合腾讯优图实验室将 GQA 改造成 MLA形式
- ACL 2025 | 腾讯优图实验室大模型4篇论文入选,涵盖智能体、角色扮演、自动推理等方向
- 超越ControlNet!腾讯优图实验室联合复旦大学提出AI生图新框架,解决多条件生成难题
- 喜报!腾讯优图联合项目获CSIG科技进步奖一等奖
- PRCV 2021 | 视觉AI飞速发展,腾讯优图分享内容理解新实践
- AAAI2022腾讯优图14篇论文入选,含语义分割、图像着色、人脸安全、弱监督目标定位、场景文本识别等前沿领域
- AICon2021 | 腾讯优图鄢科:以AI技术助力内容安全 促进互联网环境健康发展
- 腾讯优图人脸安全能力再获认可!优图专家入选“护脸计划”专家委员会
- 腾讯优图斩获ICCV2021 LVIS Challenge Workshop冠军及最佳创新奖
- CCAI 2021 | 腾讯优图汪铖杰:用AI生成更优更新的内容
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


