人工智能图像生成技术:短短5年内如何飞速发展?
2021-04-03 09:33:53AI云资讯1132

图源:unsplash
OpenAI曾创建出一些AI行业最具未来感的技术,并因此而享誉盛名。这一研究机构获得了微软的支持,现由Y Combinator创始人Sam Altman领导,以其强大的文本生成器GPT-3而闻名。
在过去几年内,该机构还制造出一只可以通过自学还原魔方的机器手、一组超人电子竞技算法、一种合理生成人类音乐的算法,以及多种可以玩游戏和使用工具学习复杂策略的算法。
近期,OpenAI发布了DALL-E,一个可以根据书面文本生成图像的人工智能系统。例如,系统响应提词“一个牛油果形状的皮包。一个仿造牛油果样式的皮包”,可以产生几十次关于牛油果皮包的迭代。
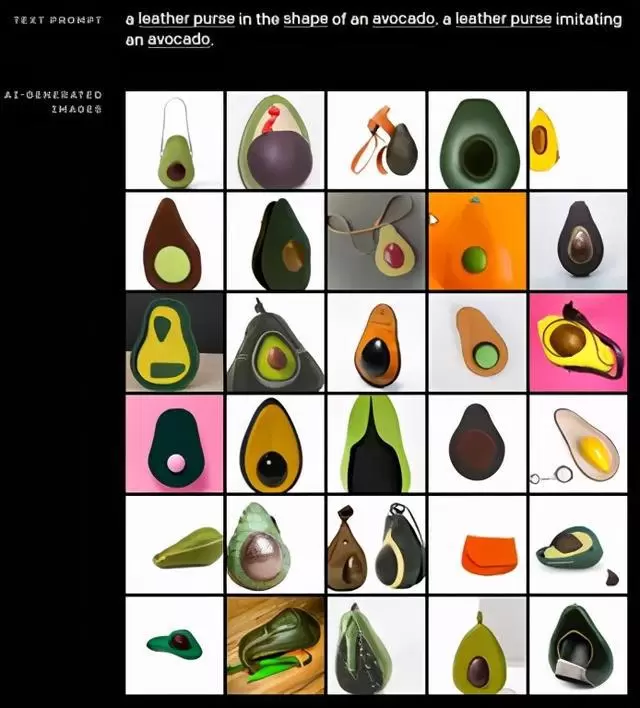
图源: OpenAI
该公司还未将DALL-E(Salvador Dalí和WALL-E名字的结合)公之于众,甚至也尚未邀请其特定开发者群体来试用新软件,但据其网站上的案例所示,该系统可以创建极其逼真且细致的图像。
DALL-E精通各种艺术风格,包括插图和风景画。它还可以生成文本,在建筑物上进行标记,并将同一场景的素描线条和全彩图像分离。研究人员把这种影响深远的能力称为泛化能力,即算法并非专门针对某一种任务或艺术风格。
OpenAI将算法的神通广大归功于两个主要因素:其一,算法非常庞大。它使用了120亿个参数,数量大到令人惊异。而这些参数可以被认为是算法转动的旋钮,用来调整其理解想法的方式。这120亿个参数在分析图像和文本时能够分辨出诸多特异性,令人难以置信。
然后,这些图像和文本材料被输入到算法中,并且被翻译成更易于算法理解的标记或文本。OpenAI解释说,一个标记就像英语字母表中的一个字母——它们代表碎片化的概念,这一方式更易于机器计算,并且以它们以算法的语言模式排列。
这一机器字母表包含16384个文本标记和8192个图像标记。这种将人类可读文本自动转换为机器可读文本的方法称为“转换器模型”。一个字幕或带有文本的图像转换为算法,最多会被翻译成256个标记,而图像最多能被翻译成1024个标记。这使得算法能够为相对较少的文本输入匹配到更复杂的图像。
之后,算法将通过分析成对的图像和字幕不断进化。通过表面上数百万次迭代,它能够将文本片段与图像的特定特征联系起来。但OpenAI还未公布这一数据集的容量或其包含的图像内容。
该公司并不是第一个尝试从文本中生成图像的公司,甚至这也不是OpenAI的首次尝试。这只是此类算法的最新版本,似乎也是最可行的一个版本。虽然该公司还未发表过任何文章来描述该系统,但这一算法的创造者确实曾在其博客上引用了DALL-E的前置任务。
通过对算法的沿袭进行考察,我们可以追踪到这项技术实际上的发展程度。
2016
OpenAI引用了这篇由密歇根大学和马普研究所撰写的论文,为当前文本到图像生成的研究注入了活力。
这篇论文使用了生成式对抗网络(generative adversarial networks generative,简称GANs)来生成图像。GANs的功能是将两种算法相互对立:一种生成图像,另一种将不够真实的图像驳回。

图源: Reed et. al
2017
一年后,罗格斯大学、里海大学和中国香港大学的研究人员采取了另一种 GAN 方法——“堆叠”成对的算法。第一对算法列出场景的形状和颜色,然后第二对算法细化细节。

图源: Zhang et. al
2019
2019年,另一支主要隶属于微软的团队尝试了不同的“两步走”方法。第一步是生成场景中对象所在位置的示意图,第二步是使用该示意图作为向导生成构成目标图片所需的对象。

图源: Li et. al
2020
去年年底,美国人工智能艾伦研究所发表了一项使用转换器模型的研究,与OpenAI使用的转换器模型相同。艾伦研究所的研究人员没有追求模型的规模,而是依赖于“隐蔽”。
在《麻省理工学院科技评论》上有一篇文章详细解释了这一概念,Karen Hao将“隐蔽”描述为“把不同的单词隐藏在句子中,让模型填补空白”。算法掌握这些直观性跳跃后,研究者发现生成的图像质量得到显著提升。

图源: Cho et al.
回溯过去这些研究案例,我们可以发现OpenAI的DALL-E确实是一项飞跃。从模糊不清的斑点开始,最先进的技术已发展到能够生成牛油果形状的椅子,OneZero专栏作家欧文·威廉姆斯表示他真的愿意购买这样的椅子。
这些进步足以让一代家具设计师、图库艺术家以及其他网络艺术家感到害怕。
相关文章
- 智汇瓯江 智引未来:2025中国人工智能数字创新大会在温州成功举办
- 苹果人工智能服务器芯片Baltra或将用于执行人工智能推理任务
- 人工智能数据处理和质量测评中心全栈服务体系正式发布
- 中国开发区协会人工智能产业专业委员会在京成立
- 中国信通院政策与经济研究所李强治:我国人工智能治理迈入务实新阶段,场景与工具同步落地
- 中国信通院产业与规划研究所张桢:人工智能与城市全域数字化转型融合,正成为推动城市高质量发展的核心引擎
- 中国信通院产业与规划研究所徐志发:人工智能驱动数字消费深度变革,“十五五”时期将进入壮大发展的关键阶段
- 中国信通院云计算与大数据研究所栗蔚:智能算力重塑计算和网络架构,普惠化服务人工智能
- 中国信通院信息化与工业化融合研究所刘默:人工智能技术创新赋能制造业智能化迈入新阶段
- 中国信通院人工智能研究所魏凯:人工智能正从工具升级为伙伴,全面赋能高质量发展
- 中国心理科技园开园暨中国心理人工智能算力中心在京成立 心理产业迈入2.0时代:“心理AI产教融合生态”
- 蘑菇云荣膺教育强国论坛2025年度科技创新教育品牌 以创新产品赋能人工智能通识教育
- 英伟达在AI图形处理器上部署训练OpenAI的GPT-5.2,为人工智能产业提速
- 2025 全国人工智能应用场景创新挑战赛AI Agent全球专项赛线下半决赛新闻发布会在深圳召开
- 美图公司RoboNeo入选2025人工智能年度榜单
- 贵港移动公司共建人工智能联合实验室,推动产学研融合与产业数字化
人工智能企业
更多>>





人工智能硬件
更多>>- 忆联UH812a以极致存力破局大模型载入瓶颈,释放算力潜能
- 讯飞翻译机登陆MWC 2026,同传级沟通体验,多语种交流无压力
- 普恩志引领:2026半导体与高端制造前瞻——核心备件如何驱动产业革新与市场机遇
- 超旗舰降噪,殿堂级音质 索尼双芯超旗舰真无线降噪耳机WF-1000XM6正式发售
- 当AI学会“隐身”,手机才真正智能:三星Galaxy S26系列开启AI哲学的降维打击
- 全球首秀!讯飞AI眼镜亮相MWC,多模态同传大模型与极致轻量化设计 引领智能穿戴新风向
- 全球瞩目!荣耀携Robot Phone、Magic V6系列、荣耀MagicBook Pro 14 2026震撼亮相MWC 2026
- MWC直击:荣耀双旗舰搭载第五代骁龙8至尊版,助力智能手机下一代技术演进
人工智能产业
更多>>人工智能技术
更多>>- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench
- 在MoltBot/ClawdBot,火山方舟模型服务助力开发者畅享模型自由
- 教程 | OpenCode调用基石智算大模型,AI 编程效率翻倍
- 全国首个!上海上线规划资源AI大模型,商汤大装置让城市治理“更聪明”
- 昇思人工智能框架峰会 | 昇思MindSpore MoE模型性能优化方案,提升训练性能15%+


