超越华为盘古千亿模型,搜狗搜索再创中文语言理解评测CLUE世界第一
2021-05-29 14:38:28AI云资讯1045
近日,搜狗搜索技术团队在CLUE(中文语言理解测评基准)的任务比赛中,基于自研的中文预训练模型击败了包括华为盘古在内的一众强劲对手,在CLUE总榜、分类总榜、阅读理解榜再次获得第一名,刷新业界记录。
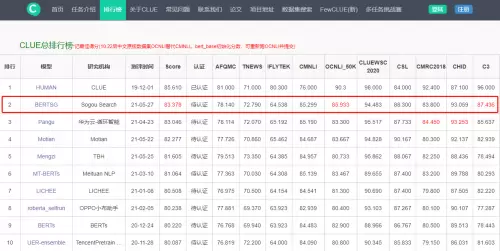
“BERTSG”为搜狗搜索自研模型,“HUMAN”为人类成绩(不计入选手)
不惧业内强劲挑战搜狗搜索用技术与算法彰显实力
作为中文语言理解领域最具权威性的测评基准之一,CLUE基于原始的中文文本语料共开设了8个方向的比赛,由文本相似度、分类、上下文推理、阅读理解等共11个子任务组成。此前,搜狗搜索曾长期霸榜CLUE多个任务比赛冠军宝座,但在今年4月遭遇到来自华为、阿里达摩院等竞争对手的强劲挑战,华为更是利用其两千亿参数模型盘古一度取得领先。
就在近日,搜狗搜索技术团队基于自研的中文预训练模型,一举超越华为盘古,再度在CLUE总榜、分类总榜、阅读理解榜获得冠军,展示了其在自然语义理解领域强大的技术创新实力和领先的AI算法能力。
据了解,搜狗搜索技术团队近一年来在预训练模型研发上加强投入,已完成从亿级到百亿级中文预训练模的研发,目前正开展千亿级中文预训练模型及多模态预训练模型的研发工作。搜狗搜索技术团队自研的预训练模型之所以能够比参数量更大的华为盘古在CLUE榜单取得更好的效果,主要是在训练语料、模型结构、训练方法三个方面进行了创新突破。
训练语料方面,凭借自身作为第二大搜索引擎的基础优势,搜狗搜索技术团队首先从万亿网页中筛选出10T优质语料,依托搜狗搜索的内容理解技术、大规模聚类等系统,进而从10T优质语料中精选出2T最终语料,这样在保证语料内容质量的同时,还可以确保内容的多样性,从训练语料上提升了模型的训练效率和泛化能力。
模型结构方面,原始的BERT模型使用了Post-LN的结构,该结构的弊端是在训练超大模型时,若没有设置好warmup,会导致收敛效果变差。而搜狗的预训练模型在结构上采用了Pre-LN的方式,大大提升了训练效率。
而在训练方法方面,搜狗搜索技术团队做了两方面的创新优化。第一,采用了cross thought预训练方法,同时引入对比学习训练方法,解决原始BERT模型学习出来的cls token向量存在各向异性的问题,大大增强预训练模型的表征能力,使得下游任务效果得到明显提升。第二,加入了根据文章标题生成和段落顺序预测两个任务,进一步增强预训练模型的文章理解能力。具体而言,在标题生成任务上,输入一篇文章的内容和标题,并且对文章和标题都做词语级别的mask操作,文章mask策略与Roberta-wwm采用的策略一样,标题则mask超过80%的词。而段落顺序预测任务的目标是预测段落之间的上下文关系,在加入这两种预测任务后,预训练模型的效果得到明显提升。
搜狗搜索NLP技术长期领先,成功落地产品、加速赋能行业
与此同时,此次搜狗搜索自研预训练模型在CLUE总榜、分类总榜、阅读理解榜再度获得冠军,也意味着搜狗搜索在自然语言预训练、语义理解、长文本和短文本分类、阅读理解、问答等领域皆持续处于业界领先水平,展现了其在NLP的超群实力。在此之前,搜狗搜索还曾在国际阅读理竞赛CoQA等竞赛中取得了冠军的成绩。
事实上,搜狗搜索之所以在NLP领域长期处于领先地位,与搜狗公司长期专注在自然语言处理领域进行深耕细作密不可分。作为一家将AI作为企业基因的公司,搜狗基于搜狗搜索、搜狗输入法等核心产品,一直坚持其以语言为核心的AI战略,并成功进行了一系列AI技术创新和产品落地实践。
据了解,搜狗自研的预训练模型已在搜狗搜索产品中落地,大幅提升了用户的搜索效率和体验。此外,相关技术在语言翻译、聊天机器人、知识图谱等领域也具有广泛的应用空间。
相关文章
- 哈利波特手游联动搜狗输入法!表情包为何能火爆出圈?
- 腾讯搭建公益平台免费开放无障碍输入技术,搜狗输入法发布眼动方案
- 金山文档联合搜狗输入法推出定制皮肤 实力诠释反差萌
- 完美适配Windows 11 搜狗输入法智能输入助手体验再升级
- 召唤搜狗输入法智能汪仔,精彩国庆节文案速度get
- 搜狗输入法手机版五笔新升级:业界主流方案全支持
- 搜狗完成私有化交易 搜索和输入法等保持搜狗品牌运营
- 搜狗宣布完成私有化交易并与腾讯完成合并
- 有口难言?搜狗输入法教你如何在七夕支棱起来
- 七夕朋友圈狗粮吃太多 看搜狗输入法如何教单身汪绝地反击
- 真会玩:搜狗输入法居然上线了这么多运动员表情包
- 跨界连线马斯克,搜狗AI合成主播惊艳亮相“全球数字经济大会”
- 从搜狗输入法智能汪仔的进化 看AI输入法的蜕变进阶之路
- 用搜狗输入法心情模板 快速获取朋友圈运动盛会加油文案!
- 搜狗输入法小米定制版更新,“智能汪仔”变身MARA助手啦
- 越加油越热爱!搜狗输入法智能汪仔解锁助威新姿势
人工智能企业
更多>>



人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench
- 在MoltBot/ClawdBot,火山方舟模型服务助力开发者畅享模型自由


