智源推出大模型全家桶及全栈开源技术基座新版图,大模型先锋集结共探AGI之路
2024-06-14 15:14:56AI云资讯96402

2024年6月14日,第六届“北京智源大会”在中关村展示中心开幕。

北京智源大会是智源研究院主办的“AI内行顶级盛会”,以“全球视野、思想碰撞、前沿引领”为特色,汇聚海内外研究者分享研究成果、探寻前沿知识、交流实践经验。2024北京智源大会邀请到了图灵奖得主姚期智,OpenAI、Meta、DeepMind、斯坦福、UCBerkeley等国际明星机构与技术团队代表,以及百度、零一万物、百川智能、智谱AI、面壁智能等国内主流大模型公司CEO与CTO,汇聚了200余位人工智能顶尖学者和产业专家,围绕人工智能关键技术路径和应用场景展开精彩演讲和尖峰对话。

开幕式由智源研究院理事长黄铁军主持。

智源研究院院长王仲远做2024智源研究院进展报告,汇报智源研究院在语言、多模态、具身、生物计算大模型的前沿探索和研究进展以及大模型全栈开源技术基座的迭代升级与版图布局。
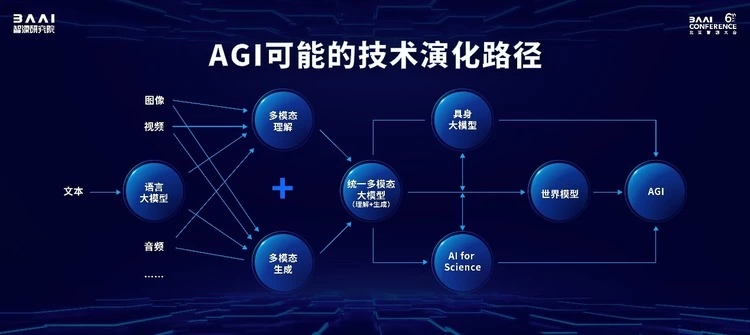
王仲远表示,现阶段语言大模型的发展已经具备了通用人工智能非常核心的理解和推理能力,并且形成了一条以语言大模型为核心对齐和映射其他模态的技术路线,从而让模型具备了初步的多模态理解和生成能力。但这并不是让人工智能感知、理解物理世界的终极技术路线,而是应该采取统一模型的范式,实现多模态的输入和输出,让模型具备原生的多模态扩展能力,向世界模型演进。未来,大模型将以数字智能体的形态与智能硬件融合,以具身智能的形态从数字世界进入物理世界,同时,大模型这一技术手段可为科学研究提供新的知识表达范式,加速人类对微观物理世界规律的探索与研究突破,不断趋近通用人工智能的终极目标。

智源语言大模型
全球首个低碳单体稠密万亿语言模型Tele-FLM-1T
针对大模型训练算力消耗高的问题,智源研究院和中国电信人工智能研究院(TeleAI)基于模型生长和损失预测等关键技术,联合研发并推出全球首个低碳单体稠密万亿语言模型 Tele-FLM-1T。该模型与百亿级的52B版本,千亿级的102B版本共同构成Tele-FLM系列模型。
Tele-FLM系列模型实现了低碳生长,仅以业界普通训练方案9%的算力资源,基于112台A800服务器,用4个月完成3个模型总计2.3Ttokens的训练,成功训练出万亿稠密模型Tele-FLM-1T。模型训练全程做到了零调整零重试,算力能效高且模型收敛性和稳定性好。目前,TeleFLM系列模型已经全面开源了52B版本,核心技术(生长技术、最优超参预测)、训练细节(loss曲线、最优超参、数据配比和GradNorm等)均开源,期望技术开源可以对大模型社区产生有益促进。Tele-FLM-1T版本即将开源,希望可以为社区训练万亿稠密模型提供一个优秀的初始参数,避免万亿模型训练收敛难等问题。
Tele-FLM-52B 版本开源地址 https://huggingface.co/CofeAI/Tele-FLM
Tele-FLM-Chat 试用(纯模型单轮对话版)地址https://modelscope.cn/studios/FLM/ChatFLM
在基础模型的性能方面:BPB 显示,英文能力上,Tele-FLM-52B接近Llama3-70B,优于 Llama2-70B和Llama3-8B;中文能力上,Tele-FLM-52B 为开源最强,优于 Llama3-70B 和 Qwen1.5-72B。在对话模型性能方面:AlignBench评测显示,Tele-FLM-Chat(52B)已经达到GPT-4 中文语言能力的96%,总体能力达到GPT-4 的80%。
通用语言向量模型BGE系列
针对大模型幻觉等问题,智源研究院自主研发了通用语义向量模型BGE(BAAI General Embedding)系列,基于检索增强RAG技术,实现数据之间精准的语义匹配,支持大模型调用外部知识的调用。自2023年8月起,BGE模型系列先后进行了三次迭代,分别在中英文检索、多语言检索、精细化检索三个任务中取得了业内最佳的表现,综合能力显著优于OpenAI、Google、Microsoft、Cohere等机构的同类模型。目前,BGE模型系列下载总量位列国产AI模型首位,并被HuggingFace、Langchain、Llama Index等国际主流AI开发框架以及腾讯、华为、阿里、字节、微软、亚马逊等主要云服务提供商集成,对外提供商业化服务。
二、智源多模态大模型
原生多模态世界模型Emu 3
行业现有的多模态大模型多为对于不同任务而训练的专用模型,例如Stable Diffusion之于文生图,Sora之于文生视频,GPT-4V之于图生文。每类模型都有对应的架构和方法,例如对于视频生成,行业普遍参照Sora选择了DiT架构。但是现有模型的能力多为单一分散的能力组合,而不是原生的统一能力,例如目前Sora还做不到图像和视频的理解。
为了实现多模态、统一、端到端的下一代大模型,智源研究院推出了Emu3原生多模态世界模型。Emu3采用智源自研的多模态自回归技术路径,在图像、视频、文字上联合训练,使模型具备原生多模态能力,实现了图像、视频、文字的统一输入和输出。Emu3从模型训练开始就是为统一的多模态生成和理解而设计的,目前具备生成高质量图片和视频、续写视频、理解物理世界等多模态能力。简单来说,Emu3既统一了视频、图像、文字,也统一了生成和理解。值得注意的是,Emu3在持续训练中,经过安全评估之后将逐步开源。
轻量级图文多模态模型系列Bunny-3B/4B/8B
为适应智能端侧的应用,智源研究院推出了轻量级图文多模态模型系列 Bunny-3B/4B/8B,该模型系列采用灵活架构,可支持多种视觉编码器和语言基座模型。多个榜单的综合结果表明,Bunny-8B 的多模态能力可达到 GPT-4o 性能的 87%。目前,Bunny 模型参数、训练代码、训练数据已全部开源。
开源地址:https://github.com/BAAI-DCAI/Bunny
三、智源具身大模型
智源研究院具身智能创新中心在机器人泛化动作执行和智能大小脑决策控制等方面取得了多项世界级突破性成果。
全球领先真机实验成功率突破95% 的泛化抓取技术ASGrasp
在具身智能通用抓取能力方面,针对跨任意形状和材质的泛化难题,智源率先突破95%的真机实验成功率,从而实现了全球领先的商业级动作执行水平。借助这项技术,即使在复杂光线透射、反射的情况下,我们的机器人依然能够准确感知包括透明、高反光物体的形状和姿态,并预测出高成功率的抓取位姿。
分级具身大模型系统之能反思、可随机应变的铰接物体操作大模型系统SAGE
在分级具身大模型系统方面,智源研发了能够从失败中重思考、再尝试的铰接物体操作大模型系统SAGE。该系统有效结合了三维视觉小模型对空间几何的精确感知能力和通用图文大模型的通用物体操作知识,使大模型驱动的机器人能够在任务执行失败时能够重新思考并再次尝试新的交互方式,实现了传统机器人技术无法企及的智能性和鲁棒性。
分级具身大模型系统之全球首个开放指令六自由度拿取放置大模型系统Open6DOR
在分级具身大模型系统方面,智源还研发了全球首个能做到开放指令控制六自由度物体拿取放置的大模型系统Open6DOR。该系统不仅像谷歌RT系列大模型一样按照自然语言指令中的要求将物体放到指定位置,还能够进一步对物体的姿态进行精细化控制。该项技术极大地提高了具身操作大模型的商业应用范围和价值。
全球首个端到端基于视频的多模态具身导航大模型NaVid
在面向技术终局的端到端具身大模型层面,智源发布了全球首个端到端基于视频的多模态具身导航大模型NaVid。该模型可直接将机器人视角的视频和用户的自然语言指令作为输入,端到端输出机器人的移动控制信号。不同于以往的机器人导航技术,NaVid无需建图,也不依赖于深度信息和里程计信息等其它传感器信号,而是完全依靠机器人摄像头采集的单视角RGB视频流,并在只利用合成导航数据进行训练的情况下,通过Sim2Real的方式,实现在真实世界室内场景甚至是室外场景的zero-shot真机泛化,是一项勇敢而成功的前沿技术探索工作。
智能心脏超声机器人
智源研究院联合领视智远研发了全球首个智能心脏超声机器人,实现了全球首例真人身上的自主心脏超声扫查,可解决心脏B超医生紧缺,诊断准确率不高,标准化欠缺,效率低的难题。基于超声影像和机械臂的受力信息,智能心脏超声机器人可在高速动态环境下,快速计算,提取心脏特征,实现了相当于自动驾驶L2、 L3 级的智能化水平。临床验证结果显示,准确性上,智能心脏超声机器人能和高年资医生保持一致;稳定性上,智能心脏超声机器人更高;舒适性上,智能超声机器人的力度可以控制在 4 牛以内,更舒适;效率上,智能超声机器人实验机可与人类医生持平。
通用计算机控制框架Cradle
为实现通用计算机控制,智源研究院提出了通用计算机控制框架Cradle,让智能体像人一样看屏幕,通过鼠标、键盘完成计算机上的所有任务。Cradle 由信息收集、自我反思、任务推断、技能管理、行动计划以及记忆模块等 6 个模块组成,可进行 “反思过去,总结现在,规划未来”的强大决策推理。不同于业界其他方法,Cradle不依赖任何内部API实现了通用性。目前,智源研究院与昆仑万维研究院等单位合作,在荒野大镖客、星露谷物语、城市天际线、当铺人生4款游戏,以及Chrome、Outlook、飞书、美图秀秀以及剪映5种软件上,对Cradle进行了验证。智能体不仅可以根据提示自主学习玩游戏,还能对图片、视频进行有想象力的编辑。
未来,智源将依托多模态大模型技术优势资源,联合北大、清华、中科院等高校院所,银河通用、加速进化等产业链上下游企业,建设具身智能创新平台,重点开展数据、模型、场景验证等研究,打造具身智能创新生态。
四、智源生物计算大模型
全原子生物分子模型OpenComplex 2
此外,智源研究院,还探索了生成式人工智能应用于分子生物学中的应用。智源研究院研发的全原子生物分子模型OpenComplex2,是世界领先的大分子结构预测模型,能有效预测蛋白质、RNA、DNA、糖类、小分子等复合物。在生物分子结构预测领域国际竞赛CAMEO(Continous Automated Model EvaluatiOn)中,OpenComplex 连续2年稳居赛道第一,并获得了CASP(Critical Assessment of Techniques for Protein Structure Prediction)15的RNA自动化赛道预测冠军。
OpenComplex 2 是基于全原子建模的生命分子基础模型,科研人员发现不仅可以预测大分子的稳定结构,还初步具备预测分子多构型以及折叠过程的能力。基于这样的能力,生命科学家可以进一步探索蛋白质的生物学功能。目前,智源已和研究伙伴在多项重要疾病上展开了研究,提供成药性和分子机理研究。未来,基于OpenComplex的能力,我们有望能够开启生命科学研究的新纪元,为进一步揭示如HIV病毒、神经元等复杂生命机理提供新的可能。
全球首个实时孪生心脏计算模型
智源研究院构建了全球首个实时孪生心脏计算模型,可实现高精度的前提下生物时间/仿真时间比小于1,位于国际领先水平。
实时心脏计算模型是虚拟心脏科学研究的开端,是孪生心脏走向临床应用的基础。基于这一模型,智源将创新性地采用物理-数据双驱动模型,融合第一性原理和人工智能方法,从亚细胞级、细胞级、器官级、躯干级仿真出一个“透明心脏”,且能根据患者的临床数据,构建出反映患者的个性化生理病理的孪生心脏,从而进行药物筛选、治疗方案优化、术前规划等临床应用。
目前,智源与北医一院共同成立了“北京大学第一医院-北京智源人工智能研究院心脏AI 联合研究中心”,正在开展基于超声影像的急性心肌梗死诊断、心衰的病理仿真、肾动脉造影等课题,与安贞医院合作进行室速疾病的无创心外膜标测技术的前沿研究,与斯高电生理研究院开展药物筛选平台的开发与应用以及与清华长庚医院和朝阳医院合作开展肥厚性心肌病课题。
智源研究院作为创新性研究机构,引领人工智能前沿技术的发展,也发挥第三方中立、非营利机构的优势,搭建公共技术基座,解决当前产业的痛点。
FlagOpen大模型开源技术基座2.0,模型、数据、算法、评测、系统五大版图布局升级
为帮助全球开发者一站式启动大模型开发和研究工作,智源研究院推出了面向异构芯片、支持多种框架的大模型全栈开源技术基座FlagOpen 2.0,在1.0的基础上,进一步完善了模型、数据、算法、评测、系统五大版图布局,旨在打造大模型时代的 Linux。
FlagOpen 2.0可支持多种芯片和多种深度学习框架。目前,开源模型全球总下载量超 4755 万次,累计开源数据集 57 个,下载量近9万次,开源项目代码下载量超 51 万次。
开源地址:https://github.com/FlagOpen

一、支持异构算力集群的大模型“操作系统”FlagOS
为满足不断攀升的大模型训练和推理计算需求,应对大规模AI系统和平台面临的集群内或集群间异构计算、高速互联、弹性稳定的技术挑战,智源研究院推出了面向大模型、支持多种异构算力的智算集群软件栈FlagOS。FlagOS融合了智源长期深耕的面向多元AI芯片的关键技术,包括异构算力智能调度管理平台九鼎、支持多元AI异构算力的并行训推框架FlagScale、支持多种AI芯片架构的高性能算子库FlagAttention和FlagGems,集群诊断工具FlagDiagnose和AI芯片评测工具FlagPerf。FlagOS如同“操作系统”一样,集异构算力管理、算力自动迁移、并行训练优化、高性能算子于一体。向上支撑大模型训练、推理、评测等重要任务,向下管理底层异构算力、高速网络、分布式存储。目前,FlagOS已支持了超过50个团队的大模型研发,支持8种芯片,管理超过4600个AI加速卡,稳定运行20个月,SLA超过99.5%,帮助用户实现高效稳定的集群管理、资源优化、大模型研发。FlagOS的推出将为中国新一代智算中心的建设提供助力,显著提升智算集群的能力水平,加速大模型产业的发展。

二、首个千万级高质量开源指令微调数据集 InfinityInstruct
高质量的指令数据是大模型性能的“养料”。智源研究院发布首个千万级高质量开源指令微调数据集开源项目,首期发布经过验证的300万条中英文指令数据,近期将完成千万条指令数据的开源。智源对现有开源数据进行领域分析,确保合理类型分布,对大规模数据进行质量筛选保留高价值数据,针对开源数据缺乏的领域和任务,进行数据增广,并结合人工标注对数据质量进行控制,避免合成数据分布偏差。当前开源的300万条指令数据集已经显示出超越Mistral、Openhermes等的SFT数据能力。我们期待在提升到千万级数据量级后,基座模型基于该指令微调数据集进行训练,对话模型能力可达GPT-4 水平。
三、全球最大的开源中英文多行业数据集IndustryCorpus
为加速推进大模型技术的产业应用进程,智源研究院构建并开源了IndustryCorpus中英文多行业数据集,包含总计3.4TB预训练数据集,其中中文1TB,英文2.4TB,覆盖18类行业,分类准确率达到80%,未来计划增加到30类。
智源通过构建多行业数据算子,训练行业分类和质量过滤模型,实现高效的高质量预训练数据处理流程,并提出了一套提升精调数据集问题复杂度、解答思维链和多轮问答质量筛选的方法,处理预训练、SFT和RLHF数据。
为验证行业数据集的性能表现,智源训练了医疗行业示范模型,对比继续预训练前的模型,客观性能总体提升了20%,而经过我们制作的医疗SFT数据集和DPO数据集的精调训练,相对参考答案的主观胜率达到82%,5分制多轮对话能力CMTMedQA评分达到4.45。
行业预训练数据集:https://data.baai.ac.cn/details/BAAI-IndustryCorpus
医疗示范模型地址:https://huggingface.co/BAAI/AquilaMed-RL
医疗示范模型SFT数据集地址:https://huggingface.co/datasets/BAAI/AquilaMed-Instruct
医疗示范模型DPO数据集地址:https://huggingface.co/datasets/BAAI/AquilaMed-RL
四、支持多元AI异构算力的并行训练框架FlagScale实现首次突破
FlagScale首次在异构集群上实现不同厂商跨节点RDMA直连和多种并行策略的高效混合训练,成为业界首个在多元异构AI芯片上同时支持纵向和横向扩展两阶段增长模式的训练框架。
FlagScale支持语言及多模态模型的稠密及稀疏训练,可实现1M长序列大规模稳定训练和推理;支持基于国产算力的8x16B千亿参数MoE语言大模型1024卡40天以上的稳定训练,实现端到端的训练、微调与推理部署;支持不同架构的多种芯片合池训练,基于业界领先的异构并行策略,可达到85%以上的混合训练性能上界,与同构芯片的模型训练效果一致;适配8款国内外不同芯片,可在不同集群进行规模训练验证,实现Loss逐位与收敛曲线严格对齐。
五、面向大模型的开源Triton算子库
为更好地支持多元AI芯片统一生态发展,智源研究院推出了面向大模型的开源Triton算子库,包括首个通用算子库FlagGems和大模型专用算子库FlagAttention,可基于统一开源编程语言,大幅提升算子开发效率,同时,面向多元芯片共享算子库。
目前主流语言和多模态模型需要的127个算子,通用算子库FlagGems已覆盖66个,预计2024年底实现全覆盖。大模型专用算子库FlagAttention,包含6种高频使用的且紧跟算法前沿的最新Attention类算子,为用户提供编程范例,可自定义算子。
应用了专为 pointwise 类别的算子设计的自动代码生成技术,用户只需通过简洁的计算逻辑描述,即可自动生成高效的 Triton 代码。该技术目前已经应用于31个pointwise类算子,占算子库整体的47%。同时,基于运行时优化技术,算子运行速度提升70%,保障了算子高性能。
六、FlagEval大模型评估全面升级
打造丈量大模型能力高峰的“尺子”乃是充满挑战的科研难题。智源秉持科学、权威、公正、开放原则,不断推动评估工具和方法的迭代优化。FlagEval大模型评估自2023年发布以来,已从主要面向语言模型扩展到视频、语音、多模态模型,实现多领域全覆盖,采用主观客观结合以及开卷闭卷综合的考察方式,首次联合权威教育部门开展大模型K12学科测验,与中国传媒大学合作共建文生视频模型主观评价体系。智源研究院已与全国10余家高校和机构合作共建评测方法与工具,探索基于AI的辅助评测模型FlagJudge,打造面向大模型新能力的有挑战的评测集,包括与北京大学共建的HalluDial幻觉评测集、与北师大共建的CMMU多模态评测集、多语言跨模态评测集MG18、复杂代码评测集TACO以及长视频理解评测MLVU等,其中与北京大学共建的HalluDial是目前全球规模最大的对话场景下的幻觉评测集,有18000多个轮次对话,和14万多个回答。
智源研究院牵头成立了IEEE大模型评测标准小组P3419,与hugging face社区合作发布多个榜单,并将先进的评测数据以及裁判模型与新加坡IMDA合作,共同贡献到AI Verify Foundation,以促进在大模型评估方法和工具上的国际合作。
大模型先锋集结共探AGI之路
2024北京智源大会开幕式上,OpenAI Sora及DALL·E团队负责人Aditya Ramesh,纽约大学助理教授谢赛宁,就多模态模型的技术路径以及未来演化方向进行了观点碰撞。

在智源研究院理事长黄铁军主持的Fireside Chat中,零一万物CEO李开复,中国工程院院士、清华大学智能产业研究院(AIR)院长张亚勤,分别分享了对通用人工智能技术发展的趋势判断。

百度CTO王海峰做“大模型为通用人工智能带来曙光”的报告分享。

在通往AGI的尖峰对话中,智源研究院王仲远,百川智能CEO王小川,智谱AI CEO张鹏,月之暗面CEO杨植麟,面壁智能CEO李大海针对大模型的技术路径依赖与突破、开放生态与封闭研究、商业模式探索等热点话题,展开深度讨论。

未来,智源研究院将继续坚持原始技术创新,做前沿方向的路线探索,广泛链接学术生态,赋能产业发展。
相关文章
- 中科闻歌重磅发布通用决策大模型Decitron决策机,内测邀请开启
- 端侧AI构筑“新丝路”:面壁智能大模型开源与端侧推理框架的出海实践
- 告别“数据枯竭”,迈向“价值坐标”——艺恩发布《全球大模型数据市场白皮书》
- 星辰大模型能力升级 天翼智铃推出30秒长视频动画制作
- 牧原携手阿里云共建养猪大模型 AI赋能传统产业升级
- 大模型落地“最后一公里“:Testin XAgent工程化评测实践
- 元戎 CEO 周光:大模型范式进入共识期,正在重构辅助驾驶行业
- 从ViP创新工艺到维擎垂域大模型,维信诺金砖论坛集中展示显示产业“中国方案”
- 卓世科技与戴盟机器人达成战略合作,共筑”行业大模型+具身智能”新生态
- 云工场科技推进CPU+GPU协同推理,推动大模型应用降本增效
- 东软添翼医疗大模型荣登“医疗AI大模型最具应用价值产品榜”
- 群核科技空间智能大模型完成国家备案,加速走向产业应用
- 破解大模型“幻觉”,徐剑军选择“可信”之道
- 携手共建“物理世界大模型”联合实验室,洞察时空与上海电信达成战略合作
- 东软添翼医疗大模型领跑 医疗AI进入“可信时代”
- 直接上智能体,还需要统一基座大模型吗?医院智能化走到十字路口
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力


