“千亿参数“大模型再卷风云,成功实现CPU通用服务器上运行
2024-07-26 17:28:59AI云资讯7652
不久前,浪潮信息的研发工程师基于2U4路旗舰通用服务器NF8260G7,采用领先的张量并行、NF4模型量化等技术,实现服务器仅依靠4颗CPU即可运行千亿参数 "源2.0" 大模型,成为通用AI算力的新标杆。
NF8260G7在2U空间搭载4颗32核英特尔至强处理器,主频2.4GHz,支持8个内存通道,3路UPI总线互联,采用32根32G的DDR5内存,内存容量1024GB,实测内存读带宽995GB/s,运行效率82.94%。框架和算法方面,NF8260G7支持PyTorch、TensorFlow等主流AI框架和DeepSpeed等流行开发工具,满足用户更成熟、易部署、更便捷的开放生态需求。浪潮信息算法工程师还基于Yuan2.0千亿参数大模型的研发积累,为NF8260G7部署张量并行环境,提升4倍计算效率,并通过NF4等量化技术,将1026亿参数的Yuan2.0大模型容量缩小至1/4,首次实现单机通用服务器,即可运行千亿参数大模型,为千亿参数AI大模型在通用服务器的推理部署,提供了性能更强,成本更经济的选择。
【出题】
算力智变:通用服务器挑战「千亿参数」大模型
科技的进步,最终目的是"落入凡间"。AIGC正以超乎想象的速度渗透进千行百业,对企业的算力基础设施也提出了更高的要求。为了满足最广泛的通用业务与新兴AI业务融合的需求,目前金融、医疗等许多行业用户正在基于通用算力构建AI业务,实现了通用算力的"AI进化"。从效果来看,目前通用服务器单机已能够承载几十到几百亿参数规模的AI模型应用。
但算力需求仍在爆发式增长,随着大模型技术的不断发展,模型参数量不断攀升,千亿级参数是智能涌现的门槛,通用算力能否运行千亿参数AI大模型,是衡量其能否支撑千行百业智能涌现的关键。
千亿参数大模型要在单台服务器中高效运行,对计算、内存、通信等硬件资源需求量非常大,如果使用以GPU为主的异构加速计算方式,千亿参数大约需要200~300GB的显存空间才放得下,这已经远超过当前业界主流的AI加速芯片的显存大小。放得下只是基础,千亿参数大模型在运行过程中,对数据计算、计算单元之间及计算单元与内存之间通信的带宽要求也非常高。千亿参数大模型按照BF16的精度计算,运行时延要小于100ms,内存与计算单元之间的通信带宽至少要在2TB/s以上。
不同参数规模服务器硬件资源需求对比
参数规模 | 100亿 | 1000亿 |
显存空间 | 20~30GB | 200~300GB |
内存带宽 (BF16精度 时延100ms) | 200~300GB/s | 2~3TB/s |
除了硬件资源的挑战,为了让通用服务器运行千亿大模型,软硬协同优化也是一大难题。比如AI大模型一般基于擅长大规模并行计算的AI加速卡设计,通用服务器的处理器虽然拥有高通用性和高性能的计算核心,但没有并行工作的环境。AI大模型需要频繁地在内存和CPU之间搬运算法权重,但通用服务器默认模型权重只能传输给一个CPU的内存,由该CPU串联其他CPU进行权重数据的传输。这就导致CPU与内存之间的带宽利用率不高,通信开销大。

通用服务器要运行千亿参数大模型面临重重挑战。要填补这一空白,浪潮信息研发工程师亟需提升通用服务器AI计算性能,优化CPU之间、CPU与内存之间的通信效率,建立通用服务器的大规模并行计算的算法环境等软硬协同技术,系统释放通用服务器的AI能力。
【解题】
软硬协同创新,释放通用服务器的智算力
首先,硬件资源方面,为支撑大规模并行计算,浪潮信息研发工程师采用2U4路旗舰通用服务器NF8260G7,对服务器处理器、内存、互连以及框架和算法的适配性等方面进行了全面优化。
本次运行千亿参数大模型的通用服务器NF8260G7采用如下配置:
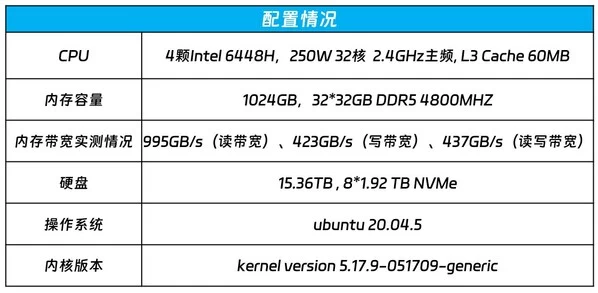
NF8260G7在2U空间搭载4颗英特尔至强处理器6448H,具有AMX(高级矩阵扩展)AI加速功能,核心数达到了32核心,基准主频2.4GHz,L3 Cache 60MB,支持8个内存通道,3路UPI总线互联,功耗250W。内存方面,NF8260G7配置32根32G DDR5 4800MHZ的内存,内存带宽实测值分别为995GB/s(读带宽)、423GB/s(写带宽)、437GB/s(读写带宽),为满足千亿大模型低延时和多处理器的并发推理计算打下基础。
在高速信号互连方面,浪潮信息研发工程师优化了CPU之间,CPU和内存之间的走线路径和阻抗连续性,依据三维仿真结果调整过孔排列方式,将信号串扰降低到-60dB以下,较上一代降低50%,通过DOE矩阵式有源仿真找到通道所有corner的组合最优解,充分发挥算力性能。框架和算法方面,浪潮信息通用服务器也支持PyTorch、TensorFlow等主流AI框架和DeepSpeed等流行开发工具,满足用户更成熟、易部署、更便捷的开放生态需求。
仅依靠硬件创新还远远不够。算法层面,浪潮信息算法工程师基于Yuan2.0的算法研发积累,将1026亿参数的Yuan2.0大模型卷积算子进行张量切分,把大模型中的注意力层和前馈层的矩阵计算的权重分别拆分到多个处理器的内存中,为通用服务器进行高效的张量并行计算提供了可能。这种权重的拆分改变了传统CPU串联传输的模式,4颗CPU可以与内存实时传输获取算法权重,协同并行工作,计算效率提升4倍。
同时,千亿参数大模型在张量并行计算过程中,参数权重需要200-300GB的内存空间进行存储和计算,在100ms的时间内,完成CPU与内存数据的通信,内存带宽需求至少在2T/s。而4路通用服务器的内存带宽极限值为1200GB/s,还差一半左右。面对巨大的内存带宽瓶颈,浪潮信息算法工程师需要在不影响模型精度的情况下对模型进行量化"瘦身"。浪潮信息研发工程师们尝试了不同精度int8、int4、NF4等先进量化技术,最终选择了更高数据精度的NF4量化方案,将模型尺寸瘦身到原来的1/4,在满足精度需求的条件下,大幅度降低大规模并行计算的访存数据量,从而达到实时推理的解码需求。

【交卷】
填补行业空白,树立AI算力新标杆
通过系统优化,浪潮信息NF8260G7在业界首次实现仅基于通用处理器,支持千亿参数大模型的运行,让通用算力可支持的AI大模型参数规模突破千亿,填补了行业空白,成为企业拥有AI的新起点。
人工智能的发展,是算力、算法和数据三要素系统突破的结果。浪潮信息研发工程师基于通用服务器NF8260G7的软硬件协同创新,为千亿参数AI大模型在通用服务器的推理部署,提供了性能更强,成本更经济的选择,让AI大模型应用可以与云、大数据、数据库等应用能够实现更紧密的融合,从而充分释放人工智能在千行百业中的创新活力,让人工智能真正"落入凡间",推动社会和经济的发展。
相关文章
- 人人都有大模型,千匠网络押注的是落地能力
- AI大模型产业应用创变营顺利举办,智数集团携东莞软协共探AI产业落地路径
- 全球前三!中国电信网络大模型及智能体 斩获GSMA多项国际权威认证
- 大模型重塑视觉 AI,商汤获Gartner认定为全球前沿技术创新者
- 国内首家!浩鲸科技鲸智大模型Token运营平台获信通院双认证
- 天数智芯全栈算力底座Day0适配GLM-5.2 自主创新架构铸就国内大模型长程推理新标杆
- 越疆将发布下一代陪伴交互AI人形机器人,以自研大模型重新定义家庭具身智能
- 联想ThinkPad P14s/P16s AI 2026移动AI工作站发售,轻松驾驭大模型和专业创作
- 科技照进现实 鸿蒙原生首个3D大模型AI应用V2Fun正式发布
- 大模型驱动算力需求扩容 寒武纪产品落地多行业
- 斑马智能董事长张建锋:全模态端侧大模型将实现座舱主动智能
- 云知声发布 U2:为执行而生的原生智能体大模型,可自主拆解并完成 100+ 步复杂真实工作流
- 中科闻歌重磅发布通用决策大模型Decitron决策机,内测邀请开启
- 端侧AI构筑“新丝路”:面壁智能大模型开源与端侧推理框架的出海实践
- 告别“数据枯竭”,迈向“价值坐标”——艺恩发布《全球大模型数据市场白皮书》
- 星辰大模型能力升级 天翼智铃推出30秒长视频动画制作
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


