Adobe进军生成式人工智能视频领域 推出文生视频AI模型
2024/10/15 06:46AI云资讯20767

(AI云资讯消息)Adobe公司正进军生成式AI视频领域。自今年年初以来,Adobe的Firefly视频模型就已开始预热,现在将在包括Premiere Pro在内的一些新工具中推出,使创作者能够扩展视频片段并从静止图像和文本提示中生成视频。
第一款工具是生成式延伸,现已在Premiere Pro中进行beta测试。它可以用于延长略短的镜头的结尾或开头,或者在拍摄过程中进行调整,比如纠正因眼神飘移或意外动作而产生的问题。
剪辑只能延长两秒钟,因此生成性扩展仅适用于小的调整,但它可以取代重新拍摄镜头以纠正细微问题的需要。扩展的剪辑可以以720p或1080p的分辨率和24帧每秒的帧率生成。它也可以用于音频,帮助平滑剪辑。比如它可以将音效和环境音延长至多10秒。
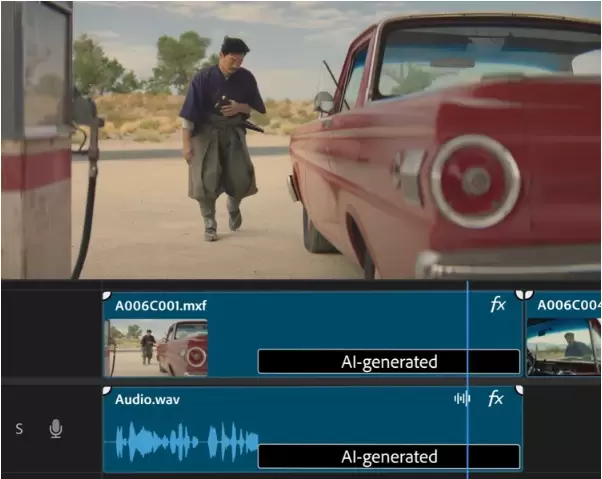
另有两款视频生成工具即将在网络上推出。Adobe的文本转视频和图片转视频工具于今年9月首次亮相,现已作为有限的公开测试版在Firefly网页应用中推出。
文本转视频的工作原理与Runway和OpenAI的Sora等其他视频生成器类似,用户只需将所需生成的内容的文本描述输入其中即可。它可以模拟各种风格,如常规的真实电影、3D动画和定格动画,生成的片段还可以通过一系列模拟摄像机控制的设置进一步细化,这些选项模拟了诸如摄像角度、运动和拍摄距离等元素。
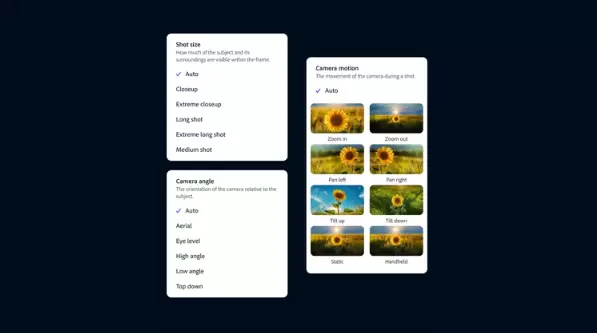
图像转视频功能更进一步,让用户在文本提示旁边添加参考图像,以更好地控制生成的结果。Adobe建议该功能可用于从图像和照片中生成备播片段,或通过上传现有视频中的静帧来帮助可视化重拍场景。然而,下图的前后对比显示,该功能实际上并不能直接替代重拍,因为在生成的结果中可以看到一些错误,如晃动的电缆和移动的背景等。

短期内也不可能用这项技术来制作完整的电影。目前,文本转视频和图片转视频的片段的最大长度为5秒,画质最高为720p和24帧每秒。相比之下,OpenAI表示Sora可以生成长达一分钟的视频同时保持视觉质量和遵循用户的提示,但这一功能虽然在几个月前就已宣布,但目前尚未对公众开放,比Adobe的工具晚了几个月。

文本转视频、图像转视频和生成式延伸功能都需要大约90秒的时间来生成,但Adobe表示正在开发加速模式来缩短这一时间。尽管目前存在局限,但Adobe表示其基于AI视频模型的工具在商业上是安全的,因为它们是基于创意软件巨头被允许使用的内容进行训练的。考虑到其他供应商如Runway的模型被指控训练数据来自数千个从YouTube上抓取的视频,对于某些用户来说,商业可行性可能是决定性的因素。
另一个好处是,使用Adobe的Firefly视频模型创建或编辑的视频可以嵌入Content Credentials,以帮助在发布到网上时披露AI的使用情况和所有权权利。目前这些工具还处于测试阶段,但至少它们已向公众开放——这比我们能对Open AI的Sora、Meta的Movie Gen和谷歌的Veo生成器说的要多。
Adobe在Adobe MAX大会上宣布了AI视频发布功能,还在其创意应用程序中推出了一系列基于AI的功能。
相关文章
- 趣链科技一工业案例入选2026世界人工智能大会“数据要素赋能智能体典型实践”项目
- 科华数据与多家主流AI芯片厂商携手亮相2026WAIC,全面展示人工智能时代的科华实力!
- GOAI 世界人工智能开源大赛官网上线,全球报名正式开启
- 场景为根 应用为王——世界人工智能大会上的海科方案
- 世界人工智能大会,慧博云通入选“数据要素赋能智能体”论坛典型实践项目
- 共赴AI原生新时代!思特奇携全栈AI体系能力亮相2026世界人工智能大会
- 上海智位机器人亮相WAIC 2026国际人工智能教育论坛 分享科技教育全球化实践
- 全球商用服务机器人出货量头部企业擎朗智能携人形机器人亮相2026世界人工智能大会
- 游族网络出席WAIC 2026人工智能引领产业变革思客会,并参与发起《人工智能发展与安全倡议书》
- 聚焦AI系统性进化 腾讯发布2026人工智能十大趋势报告
- 盛会启幕 | WAIC2026世界人工智能大会,数聚链具身智能“大小脑”协同技术重磅亮相!
- 2026世界人工智能大会开幕 “小巨人”凌雄科技AI算力业务和机器人租赁业务备受关注
- 智元酷拓携“灵越”与“灵途”两大核心技术亮相2026世界人工智能大会
- 昇腾950超节点斩获2026世界人工智能大会SAIL最高奖
- 智能伙伴 共创未来 | 2026世界人工智能大会在上海启幕
- 拯救者Y900获工信部认证,联想成唯一平板达标人工智能国标L3级的厂商
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


