容联云与南开大学联合论文被人工智能国际顶会AAAI收录
2021-03-12 16:05:19AI云资讯879

近日,人工智能领域的全球顶级学术会议AAAI公布了2021年论文录用结果,容联云人工智能实验室(Cloopen Research)与南开大学的联合研究成果提出了基于双向阅读理解框架的情感三元组抽取模型,联合论文《Bidirectional Machine Reading Comprehension for Aspect Sentiment Triplet Extraction》已被AAAI 2021收录。

AAAI会议由国际人工智能促进协会主办,被中国计算机学会列为A类会议,是业界广泛认可的顶级AI学术盛会。AAAI 2021投稿论文总数达到“惊人的高技术水平”,9034篇投稿论文中,7911篇接受评审,最终1692篇被录取,录取率为21%,录取难度高。
此次容联云与南开大学合作开展的研究目标是针对各类网站上积累的海量的用户评论、对话等数据进行语义挖掘。这些数据包含消费者对各类商品或服务的评价、观点以及态度,越来越多的企业与机构开始关注并收集用户的意愿,迫切地想了解用户对于企业的产品和其服务的反馈信息,对这些数据进行细粒度意见挖局具有重要的应用价值。
细粒度意见挖掘是NLP中一个重要的研究方向,涉及评价方面抽取(Aspect term extraction)、评价词抽取(Opinion term extraction)、属性级情感分类(Aspect-level sentiment classification)等诸多任务。
细粒度意见挖掘存在诸多挑战:
第一,经典细粒度意见分析通常是基于多步骤的方法,通过逐一地完成独立子任务,形成一个流水线。如何设计一个整体模型同时完成这些密切关联的任务,减少错误传递,并使他们相互促进是一个重要挑战。
第二,评价方面和评价词之间的对应关系通常是复杂多样的,比如一对多、多对一、甚至会出现重叠和嵌套的情况。因此,如何灵活、准确地检测评价方面和评价词之间的对应关系是一个重要挑战。
第三,一个意见句中可能会包含不同的评价方面,而不同的评价方面又可能对应不同的情感极性。考虑到这些情感极性通常是由评价方面和其对应的评价词共同决定的,因此如何恰当地利用评价方面和评价词之间的对应关系来指导属性级情感分类任务也是一个重要的挑战。
在本篇论文中,创新性地将意见三元组抽取形式化为一种多轮阅读理解(Multi-Turn Machine Reading Comprehension, MTMRC)任务,并提出一种双向阅读理解框架(Bidirectional Machine Reading Comprehension, BMRC)。通过设计三个轮次阅读理解问答,BMRC可以灵活地建立意见实体抽取、关系检测、情感分类三个子任务之间的关联,进而有效解决上述挑战。通过设计双向的MRC框架,论文模型可以更好地模拟人的阅读行为,确保评价方面或评价词均可触发一个意见三元组,进而提升识别效果。
为了验证BMRC模型的有效性,论文在来自SemEval ABSA Challenges的四个公开数据集上进行了实验,实验结果如图所示。实验表明,论文所提方法在意见二元组抽取(下图中“P”列)和意见三元组抽取任务(下图中“T”列)上的多个指标均取得了最优的性能。
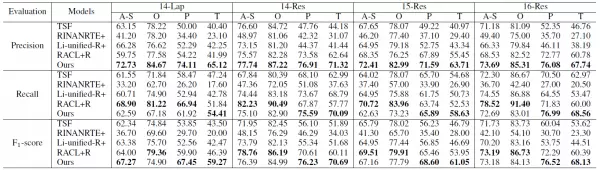
四个公开数据集上的实验结果(%)
本研究提出创新的双向阅读理解抽取框架,打破了传统法的局限,更符合人类阅读行为和思维模式,从而提升了识别效果,取得了显著优于现有方法的识别性能。
细粒度情感分析对于舆情分析、对话理解等诸多下游任务具有重要的意义,是当前众多研究机构和研究者着力解决的重要挑战。BMRC模型的提出是对这一NLP关键问题的有效探索和推进。
未来,容联云将进一步联合南开大学将该成果应用于容联云AI kernel云梯平台。AI kernel云梯平台是一个面向企业和集成开发商,提供自学习平台、bot对话能力以及NLP原子能力等的AI能力平台。平台支持一键式构建、训练和发布AI模型,基于沉淀的多种可复用的AI模型,帮助企业更快构建各类场景需求的智能化产品。
为了更好的将通讯与AI结合,赋能客服与联络中心产业智能化升级,2018年以来,容联云人工智能实验室不断在语音语义等领域加大研究与投入,并持续将研究成果产品化、工程化,通过技术与产品创新驱动产业智能化升级。
相关文章
- 容联云与中国联通达成战略合作,共拓全域互联新蓝海
- 容联云智能体入选IDC《中国金融行业生成式AI市场概览》
- CIFS直击|容联云:AI Agent正重塑金融数智化工作流
- 两会报道丨容联云孙昌勋:构建AI业务引擎,助推产业级智能体高质量发展
- 容联云以AI+金融实践,入选「大模型厂商全景报告」核心阵列
- 容联云白皮书 | 赋能世界500强:AI驱动客户体验升级的底层逻辑
- 践行国家“人工智能+”战略,容联云助力某消金“客服智能体”落地
- 容联云入选沙利文《2025人工智能全景图》,彰显AI Agent领军实力
- 容联云携手信通院,启动“智能体服务生态共创计划”
- 全年停机<5分钟,容联云为头部财险打造“5个9”高可用联络中心
- 容联云携手长江证券,打造证券大模型质检AI Agent标杆
- 收入飙升15倍,容联云洞察代理挖出金融会话中的千万沉默资产
- 智能体标杆,容联云大模型应用入选2025AI Agent产业图谱
- 深度耦合银行业务,容联云打造基于DeepSeek的6大场景实践
- 容联云大模型应用再获认可,上榜中国最具商业潜力AI应用
- 容联云孔淼:金融数智化深水区,从数字化工具到业务变革提效
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布


