OLR2021|第六届“东方语种识别竞赛”圆满落幕,网易、蚂蚁集团同获双料冠军
2022/01/19 16:03AI云资讯11824
由厦门大学、清华大学、海天瑞声、西北工业大学及昆山杜克大学联合主办的第六届的“东方语种识别竞赛”(OLR2021)于2022年1月14日公布结果并召开线上研讨会,标志着本次竞赛圆满结束。

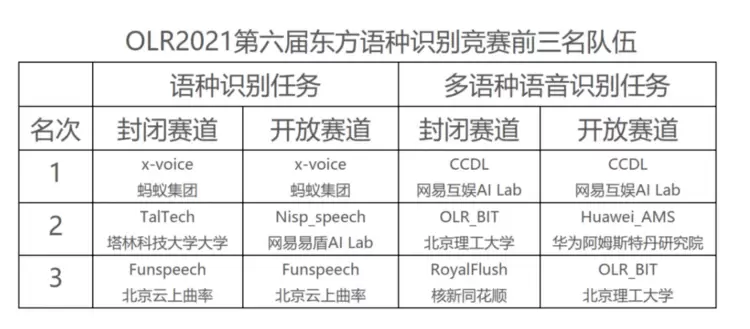
本次竞赛关注语种识别和多语种语音识别两个任务,每种任务又包括固定数据和开放数据两个赛道。经过激烈竞争,来自蚂蚁集团的X-Voice代表队获语种识别两个赛道的双料冠军,来自网易互娱AILab的CCDL代表队获多语种语音识别两个赛道双料冠军。取得优异成绩的团队还包括:来自爱沙尼亚塔林科技大学的TalTech代表队,来自北京云上曲率科技有限公司的funspeech代表队,来自网易(杭州) 易盾 AI Lab的nisp_speech代表队,来自北京理工大学的OLR_BIT代表队,来自核新同花顺网络信息股份有限公司的RoyalFlush代表队,来自华为阿姆斯特丹研究院的Huawei_AMS代表队。关于竞赛更多信息可由竞赛官网(http://olr.cslt.org)获取。
在1月14日的研讨会上,清华大学的王东老师对东方语种识别竞赛发展和定位进行了介绍;本届竞赛的组织者,厦门大学的洪青阳老师对本届比赛进行了总结;来自海天瑞声的市场部总监张楉林对OLR赛事的数据集进行了介绍,来自昆山杜克大学的李明老师和来自西北工业大学的张晓雷老师对竞赛获奖者进行了颁奖,参赛队伍代表介绍了各自的比赛系统。

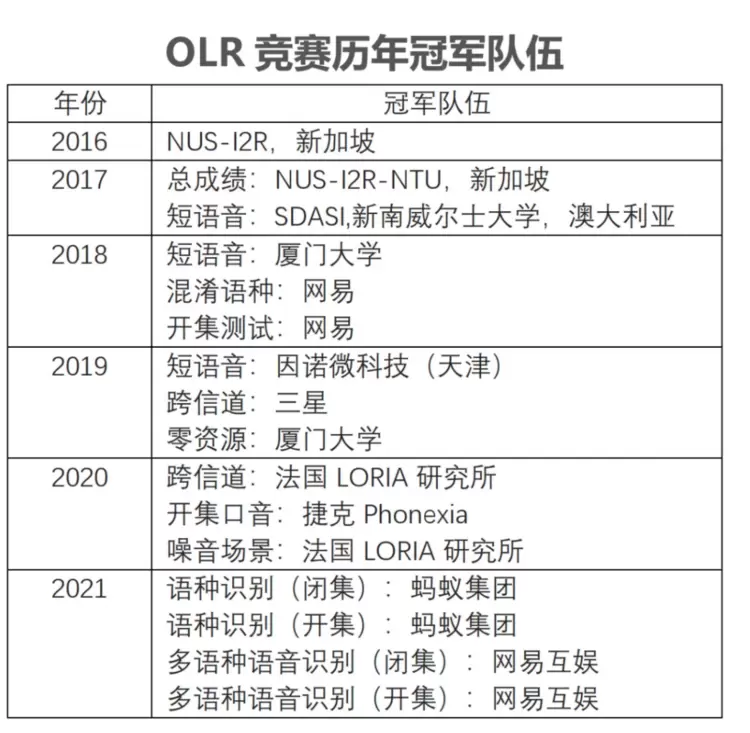
东方语种识别竞赛关注多语种环境下的语言复杂性,目前已经成功举办六届。在此之前,新加坡NUS, I2R, NTU, 新南威尔士大学,厦门大学,网易,三星,因诺微科技(天津),法国LORIA研究所,捷克Phonexia等大学、研究机构和公司曾斩获冠军。
相关文章
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


