Soul App开源SoulX-Duplug模块,探索更自然的全双工语音交互路径
2026-05-08 14:19:01AI云资讯2199
近期,Soul App AI团队联合上海交通大学X-LANCE Lab与西北工业大学ASLP@NPU团队,共同开源全双工语音对话控制模块SoulX-Duplug,并同步推出评测基准SoulX-Duplug-Eval。该项目围绕实时语音交互中的关键控制问题展开,为完善现有语音系统提供了全新的实践路径。

当前主流语音对话系统多采用半双工模式运行,用户无法在系统回应过程中进行打断,系统也难以表达附和或短暂停顿等自然行为。相比之下,全双工语音对话系统允许系统在生成回复的同时持续接收用户输入,使交互过程更接近人与人之间的自然对话。然而,现有全双工方案往往将语言生成与交互控制紧密绑定在同一模型中,这种设计虽然简化了结构,但也带来了训练难度高、数据依赖强以及系统扩展性受限等问题。在工业实践中,常见的做法是通过语音活动检测(VAD)、语音识别(ASR)以及轮次检测等模块进行组合,但多模块级联也会引入响应延迟与信息割裂等问题。
在此背景下,SoulApp团队的设计SoulX-Duplug能在单一模型框架中同时完成语音活动检测、流式语音识别以及对话状态预测三项任务,通过统一建模减少模块之间的信息损耗。在持续音频输入的条件下,模型能够实时解析语音内容,并动态判断当前对话状态,从而支持更加流畅的全双工交互。
在具体实现上,SoulX-Duplug采用GLM-4-Voice speech tokenizer,以12.5Hz的频率提取离散语音token,并通过160毫秒的处理窗口进行流式交替生成。Soul App团队的这一设计使模型能够在较低延迟下完成语音识别与状态判断。与此同时,系统定义了五类核心状态token,包括用户静默、有效语音输入、附和行为、语义完成以及语义未完成等,对对话过程中的关键节点进行结构化描述,从而提升系统对复杂交互情境的理解能力。
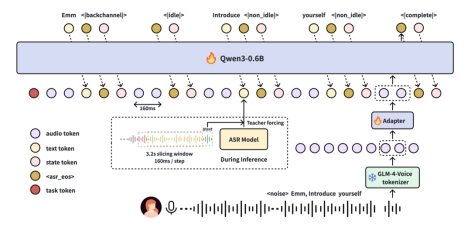
在方法设计上,SoulX-Duplug引入文本引导的流式状态预测机制。与仅依赖声学特征的传统方法不同,该模块通过结合语音识别结果,使模型在判断语音活动的同时具备语义理解能力。在训练过程中,系统以交替预测的方式生成音频token、识别文本以及状态token,使语义信息直接参与对话控制判断。这种方式不仅提升了对用户意图的识别精度,也为实现语义感知的语音活动检测提供了技术路径。
围绕模型训练与部署,SoulX-Duplug采用三阶段训练策略,依次完成非流式语音识别预训练、流式场景适配以及对话状态预测微调。在实际推理阶段,系统支持接入外部高效语音识别模块,从而在保证性能的同时提升部署灵活性。这种“训练与推理解耦”的策略,使模块既具备端到端能力,又能够适配不同系统架构。
在性能验证方面,SoulApp研究团队基于SoulX-Duplug构建了完整的全双工语音对话系统,并在中英文双语的Full-Duplex-Bench基准上进行评测。该评测覆盖轮次切换、停顿处理、用户附和以及用户打断等多种关键场景。实验结果显示,系统在整体对话管理能力上表现稳定,在响应延迟方面同样具备优势,体现出该模块在复杂交互环境中的实用价值。
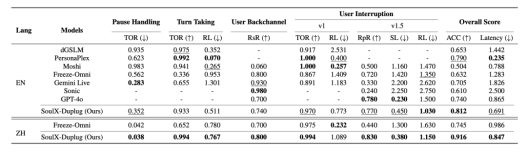
在实际部署条件下,SoulX-Duplug作为独立模块的平均延迟约为250毫秒,接近其理论延迟240毫秒,明显优于传统基于VAD方案约500毫秒的水平,也超过部分同类模块约343毫秒的表现。这一结果表明,在保证语义理解能力的前提下,该方案能够有效控制系统延迟,为实时语音交互提供更具可行性的技术路径。
通过开源SoulX-Duplug及其评测体系,Soul App将全双工语音对话中的关键控制能力进行模块化拆解,并以流式状态预测为核心实现路径,为行业提供了一种兼顾性能与扩展性的解决方案。
相关文章
- 聚焦情绪连接,Soul App 创始人团队探索社交新路径
- Soul 创始人张璐团队完善AI治理机制,多维度守护社交生态
- Soul 创始人张璐团队推动AI社交治理升级,筑牢社交安全屏障
- Soul App 创始人团队披露生态治理成果,AI治理拦截违规内容477万条
- Soul App 创始人团队公布Q1生态安全成果:AI赋能清朗社交环境建设
- 东方财经专访Soul创始人张璐团队:近十年深耕,AI让社交回归真实连接
- Soul App发布SoulX-LiveAct开源模型,优化实时数字人生成技术
- Soul App发布开源模型SoulX-LiveAct,解决数字人长视频生成难题
- Soul App开源SoulX-Duplug模块,探索更自然的全双工语音交互路径
- Soul App联合高校开源SoulX-Duplug,推动全双工语音对话能力落地
- Soul App发布年轻人五一出行图鉴,洞察Z世代假期出行偏好
- 五一出行新风向|Soul App读懂Z世代出行选择逻辑
- 从线上到线下,Soul App以“情绪酒馆”丰富社交体验
- Soul App开源SoulX-FlashHead,让实时数字人技术从机房走向个人工作站
- Soul App开源SoulX-FlashHead,轻量化模型推动实时数字人技术迈向消费级终端
- Soul App联名DASH LAND活动开启,探索社交真实感与边界感
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


