AICon2021 | 腾讯优图鄢科:以AI技术助力内容安全 促进互联网环境健康发展
2021-12-01 12:12:48AI云资讯2830
近年来,伴随着深度学习技术的成熟以及计算机算力的增长,人工智能技术在各行业的业务场景中实现了快速的普及和落地。在人工智能技术进一步落地实践的背景下,将会为行业带来什么样的变革与技术创新,成为了大家共同关心的问题。
11月25至26日,以“AI商业化下的技术演进”为主要研讨方向的AICon全球人工智能与机器学习技术大会北京站顺利召开。据了解,AICon北京站设置了“人工智能前沿技术”、“计算机视觉实践”、“智能金融技术与业务结合”、“认知智能的前沿探索”等14 个技术专题,并邀请了50余位行业资深专家,分享最新 AI 技术创新和应用实践。
本次大会,腾讯优图实验室内容审核算法负责人鄢科受邀出席了“计算机视觉实践”技术专题的研讨,并通过《腾讯优图在视觉内容理解领域的研究与实践》的主题演讲,分享了腾讯优图在内容安全领域中的研究成果和应用实例,提供了技术创新和落地实践的经验和思路。
01 视觉内容理解在内容安全领域中的技术特点和挑战
随着互联网的高速发展,网络内容不论是呈现形式还是信息体量都迎来了爆发式的增长。而在这些增长的背后,也隐藏着海量的色情、血腥等不良和有害信息,不仅危害互联网平台的内容生态,更可能导致安全问题。在内容安全问题不断加剧的背景下,AI、大数据等信息技术能够辅助传统人工审核,在内容安全领域中发挥了重要作用。
基于此,腾讯优图依托在视觉AI技术上的研究成果,打造了包含涉黄、广告、违法违规等在内的、一站式内容安全的解决方案。凭借支持一体化接入、需求定制化、详实的标签体系和自动化训练平台等优势,该解决方案能够在社区、UGC、直播、点播等场景中辅助人审,从而提高内容安全审核的效率。
而在推动视觉AI技术落地业务场景的过程中,腾讯优图也归纳和总结了视觉内容理解的技术特点和挑战:
首先,内容安全审核被广泛应用在海内外不同国家的各个行业和业务之中,不同业务的审核场景千差万别;以游戏直播场景为例,该场景一般是二次元模态的游戏画面,但由于海外手机的像素质量和国内不一样,很多都是一些模糊不清低质图像,场景多样严重考验AI算法的稳定性和泛化能力。
其次,针对于同一个内容,不同客户的标准定义差别很大,针对客户需求制定能够实现全覆盖的标签和标准体系,对技术完备提出了较高的要求。
最后,多样化的内容审核场景也要求方案具备多标签识别、目标检测、画面细粒度、OCR等技术,无法通过一个简单的技术点或是通用模型解决所有问题,对模型能力的精细化和快速优化也提出了较高的要求。
02 腾讯优图实验室在视觉内容理解场景的主要研究方向
目前,腾讯优图在内容安全领域主要的研究方向主要包括细粒度识别、多标签识别、目标检测、目标定位、对象供给、图像描述等六个方向。
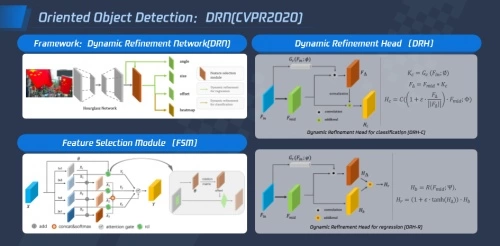
1)目标检测:目标检测在内容理解领域中非常重要,包含通用物体检测、特殊场景/商品检测、遥感图象、旋转目标检测等技术方向。其中,腾讯优图在旋转目标检测进行了深入研究,提出了DRN(动态修正网络)来提升检测效果的方法。
通过在FSM(特征选择模块)中设计自适应感受调整模块的方式,模型能够根据目标的形状旋转角度进行自适应调整,从而缓解单一感受点与多目标的矛盾。
此外,针对分类和回归任务,腾讯优图设计了DRHC(动态修正分类器)与DRHR(动态修正回归器),让模型能够同时学习样本敏感和fintune之外的、与样本无关的一般性知识,并通过预训练的方式赋予模型样本一致性调整的能力。
最后,统一的DRN能够让模型通过端到端的方式学习旋转目标检测任务,同时基于AnchorFree算法,DRN也能对解决密集排列目标场景下的目标重合、混淆的问题进行较好的处理。
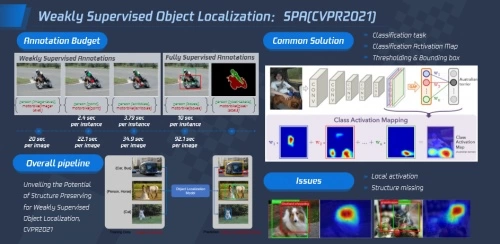
2)目标定位:人、车、物的检测工作所要求的标准检测的框和目标标注的成本都很高,而在细分场景检测时需要标注的比较精细,从而提升了标注的难度和成本。为了提高标注的效率并降低成本,腾讯优图在弱监督和定位方面进行深入研究,并提出了目标结构保持是弱监督定位关键问题的观点。
大多数弱监督目标检测主要是依据分类网络输出响应、空间正则约束来入手,通过提取一系列提升网络的响应区域去覆盖目标更多区域的。这种方法一般都会采用分类结构,而这样做则会让模型丢失目标结构信息;同时,无限制的类别响应特征图往往会出现局部提高响应导致模型分类出现一些误判,不利于模型准确定位到目标的位置。
为解决以上问题,腾讯优图首先设定了受限激活模块缓解模型结构信息的损失问题,并重新定义了高阶相似性,使自相关图生成模块显著提高了目标定位的精度;之后,通过计算每个特征位置在类别相应性质图上的方差分布得出粗略的伪mask,以此来区分前背景;然后对类别响应特征图进行归一化,利用提出来的受限激活损失函数来引导模型关注目标前景的区域,组成受限激活模块;最后利用受限激活模块进行训练,在前向inference推理的过程中,高阶自相关图就会增强图片的表达和后处理,让可视化图更加清晰、定位更加准确。
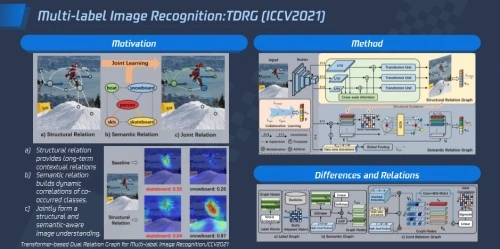
3)多标签识别:多标签识别是内容理解和内容审核的场景中非常通用的技术问题。之前很多技术都是采用RNN或者GCN来网络结构来处理标签之间的共性依赖问题,这种方法没有考虑到标签共性依赖,导致系统无法有效分辨出标签及临近标签之间的关系,大大降低了图片识别的准确度。
为此,腾讯优图提出了“除共性依赖以外,空间依赖也是理想多标签预设的重要因素”这一观点,在考虑共性依赖的基础上引入了空间依赖的建模,通过构建一种基于Transfomer的双目互补关系学习框架,让模型同时学习空间依赖和共性依赖。具体而言,即在空间依赖上使用跨尺度的Transfomer建模,对CNN提取到的一些特征经过跨尺度增强后得到空间信息更加清晰的图像特征,然后利用共享权重的Transfomer群来建模空间,在建模过程中的空间依赖则根据空间关联提升类别响应。
针对于共性依赖只需要进行内别、感知约束和空间关联引导,基于图神经网络联合GCA,联合建模动态语义关联,最后整合两种互补关系进行协同学习得到给鲁棒的多变性预测,进一步提升图片识别的准确性。
此外,通过标签的value来为图像标签引入文本语义信息的方式,用图像标签做表征的方法也能取得很好的效果:将视觉的fintune和文本fintune直接用Transfomer建模,能够让多模态融合多标签的识别方法,相较于纯标签的语义信息的效果有着显著提升。
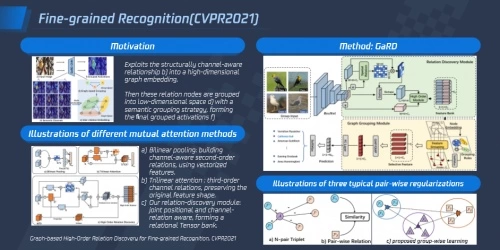
4)细粒度识别:过往的细粒度识别主要是使用通道间高阶特征获取可区别性的表达,但这种做法一般都会忽略空间位置关系的和不同语义之间的相互关系,在复杂背景或内间距比较小的场景中误判的情况较多。基于此类问题,腾讯优图曾提出了通过挖掘特征间的空间关系和语义关系来建模高阶关系,再对其中一些相似关系进行合并、保留区别性高的特征的解决方案。
相较于三元的线性关系建模,该方案的关系模块能够在考虑空间关联的基础上,构建更加丰富的语义关联;同时,通过图神经网络学习高阶特征中图层不同节点间的关系,并根据关系的三元规则对高阶关系进行分组加权,在对相似特征进行合并后,能够在实现降维的同时保证比较高的特征;最后,在训练过程中采取类别均衡采样策略学习,来确保特征分布更加准确。
然后这样的解决方案还是存在时间消耗过多和因深层扰动导致工作效果不稳定的问题。对此腾讯优图提出了利用显著性区域的对抗自动编码器生成噪音的解决方法,让时效性问题和对抗生成网络不稳定的问题同时得到了解决,在不同数据集的识别上都能取得比较好的识别效果。
03 腾讯优图视觉内容理解的实际应用案例
目前,腾讯优图视觉内容理解的实际应用场景包括ACG敏感内容识别和图像情感倾向分析等多类。
1)ACG敏感内容识别:在内容安全领域中,由于ACG场景中多种风格之间的差异化较大,导致通用模型在动画、漫画和游戏领域中的内容识别能力相对较弱,容易出现大量的误判。为解决此类问题,腾讯优图首先在统计原域和目标域间的特征分布后,使用MMD来缩短两个特征分布间的距离,实现分布约束;然后通过渐进式学习策略让模型在迁徙过程中优先选择与原域相近的样本,有效降低了模型迁徙的难度;最后通过半监督实现了通用模型的迅速迭代,生成针对ACG场景识别的专用审核模型。
在实际应用中,使用了渐进式学习策略的专用审核模型相较于直接迁徙的模型,召回率至少提升了17%~30%,极大程度上提升了ACG内容审核工作的效率和效果。
2)图像情感倾向分析:现阶段的内容审核工作中,审核系统对于出现人民币、暴力等敏感元素的图片都会做召回处理。但实际场景中,大量出现人民币元素的图片是正常的,这无形中为人审环节增加了很多工作负担。
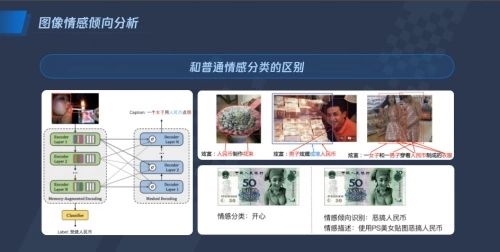
为此,腾讯优图提出了图像情感倾向分析和一般的倾向分类,模拟人的主观感觉对图像进行识别和分析,如果一张图中出现了大量人民币和一个人,并且这个人表现出开心的状态,那么这张图的情感倾向就是正向的,无需召回;但如果一张图中出现了恶搞人民币的场景,那么这张图的情感倾向就是负向的,需要召回并进行再审核。
相关文章
- SOTA达成!腾讯优图D-Search算法登顶国际AI权威榜单
- PRCV2025大会顺利召开,腾讯优图携前沿科技成果亮相现场
- 腾讯优图携Youtu-Agent开源项目亮相上海创智学院首届TechFest大会
- 拿下SOTA!腾讯优图联合厦门大学提出AIGI生成图像检测新方法
- Interspeech 2025 | 腾讯优图实验室4篇论文入选,涵盖超声波活体检测、神经语音编解码、语音合成等方向
- ICCV 2025 | 腾讯优图实验室大模型8篇论文入选,涵盖风格化人脸识别、AI生成图像检测、多模态大语言模型等方向
- 最高10倍加速!北京大学联合腾讯优图实验室将 GQA 改造成 MLA形式
- ACL 2025 | 腾讯优图实验室大模型4篇论文入选,涵盖智能体、角色扮演、自动推理等方向
- 超越ControlNet!腾讯优图实验室联合复旦大学提出AI生图新框架,解决多条件生成难题
- 喜报!腾讯优图联合项目获CSIG科技进步奖一等奖
- PRCV 2021 | 视觉AI飞速发展,腾讯优图分享内容理解新实践
- AAAI2022腾讯优图14篇论文入选,含语义分割、图像着色、人脸安全、弱监督目标定位、场景文本识别等前沿领域
- AICon2021 | 腾讯优图鄢科:以AI技术助力内容安全 促进互联网环境健康发展
- 腾讯优图人脸安全能力再获认可!优图专家入选“护脸计划”专家委员会
- 腾讯优图斩获ICCV2021 LVIS Challenge Workshop冠军及最佳创新奖
- CCAI 2021 | 腾讯优图汪铖杰:用AI生成更优更新的内容
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


