天衍实验室“纠偏方法”论文入选NeurIPS-2020 ,帮助用户躲避海量雷同信息
2020-12-01 14:04:07AI云资讯1140
在我们浏览各大网站和APP时,受推荐系统影响,大量相似产品反复出现的情况屡见不鲜,这不仅会产生视觉疲劳,而且很难让我们做出理性的判断和购买决策。究其原因,主要是目前主流的推荐系统采用的都是大数据模型筛查方式,会产生较大的路径依赖。
对此,腾讯天衍实验室近期另辟蹊径推出推荐系统纠偏方法,与传统方法相比,该方法无需执行随机流量实验以进行无偏估计,大大减小了无偏推荐算法的训练成本,降低了系统的路径依赖。目前,腾讯已经就研究成果发表论文《Information-theoretic counterfactual learning from missing-not-at-random feedback》,且成功入选NeurIPS-2020。
传统推荐系统易导致路径依赖 致使推荐质量下降
作为现代互联网领域的重点研究方向,推荐系统具有相当高的商业价值。推荐系统模型需要在大量的候选项目中(通常为广告、商品、短视频等)寻找到用户所喜爱的,从而提高曝光率或者点击广告收入。
传统推荐系统研究一般着眼于设计更好的特征交叉方法以提高CTR预估的准确性,从而给出更好的排序结果,提高广告收入。通常,用户看到的物品是推荐系统挑选出来的,它们在系统中产生了存储记录,推荐模型在该记录上进行离线更新。然而已有的研究显示,这种推荐方式会产生路径依赖,即模型会在得到曝光的项目上严重高估其对每个用户的偏好程度,而会在未得到曝光的项目中低估其对每个用户的偏好程度。长此以往,推荐结果的多样性将会急剧降低,从而危害推荐的质量和用户留存度。
如下图所示,橙色表示来源于MNAR数据的用户评分分布,蓝色表示MAR的评分。可以看到,MNAR上用户的评分要大大偏高,多集中在5分,而MAR的数据较为平均的分布在1到5分之间。随着时间推进,MNAR的评分分布会越来越集中,加大和MAR评分的差距。
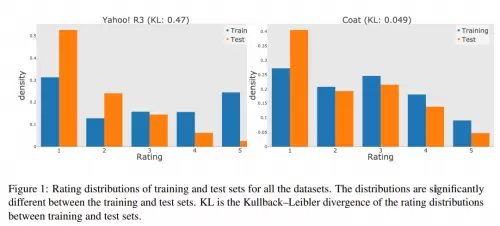
图 1 随机缺失数据和非随机缺失数据上用户反馈的偏差
为了解决这个问题,传统方法多基于inverse propensity score (IPS) 来对在MNAR数据上进行模型训练的目标函数进行加权纠偏。这类方法需要相当数量的随机试验 (Randomized Controlled Trials, RCTs),即随机地将项目推荐给用户以获得反馈,从而得到一个无偏的点击率的估计。而另外,IPS方法需要收集一定数量的RCTs,即对用户展示相当数量的随机项目来收集反馈,从经济效益上来说,会造成大量的收入上的损失。而且,这种施加权重的方法也使得训练的方差增大,有时候反而会对结果造成副影响。
借鉴信息理论构建模型 推荐系统纠偏方法呈现创新优势
腾讯天衍实验室借鉴了信息论中的理论来构建模型。模型的原始输入会先经过一个编码器 (Encoder) 得到表示 (Representation),随后经过解码器 (Decoder) 将表示解码成为最终的预测结果。此后,目标函数分为两部分:输入和表示之间的互信息,表示和输入目标之间的互信息。在优化这个目标函数时,腾讯天衍实验室团队采用了尽可能携带更多的目标信息和压缩输入信息的方法。
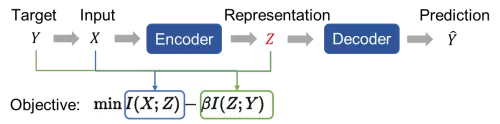
图 2 信息瓶颈的流程和定义形式
首先把原始的输入 (在此处是user-item对) 分为事实域 (factual) 和反事实域 (counterfactual) 。当在counterfactual中发现无法得到用户对项目的反馈,无法对模型进行监督学习时,选择将该问题用信息瓶颈建模,由此得到一个无需反馈也可以在counterfactual上进行学习的目标函数。
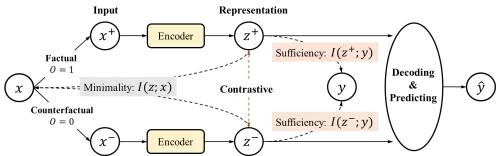
图 3 基于信息瓶颈理论的反事实学习框架流程图
factual和counterfactual的事件分别是和,相对应的表示为和。在此基础上将原有的互信息项拆分,并引入一个超参数,可以得到一个新的考虑counterfactual的信息瓶颈:
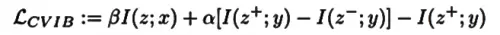
这一新的瓶颈将原有的项拆分成了两个域的对比项加上factual的信息项。源于上式中的互信息项无法直接优化,在将其经过进一步拆解变为可优化的形式后,最终的目标函数形式为:
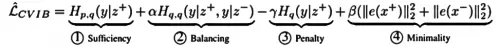
这一目标函数具有很广泛的适用范围,领域内绝大部分的模型均可以适用该目标函数来进行模型纠偏而无需对现有模型结构进行修改,比如MF模型等。
为验证其应用潜力,腾讯天衍实验室使用领域内的benchmark Yahoo R3! 和 Coat 公开数据集进行测试,使用MNAR的数据作为训练数据,使用MAR作为测试数据,从而能有效反映不同方法对于推荐模型的纠偏效果,最终实验结果如下表所示。
表格 1 实验结果(AUC和MSE指标)
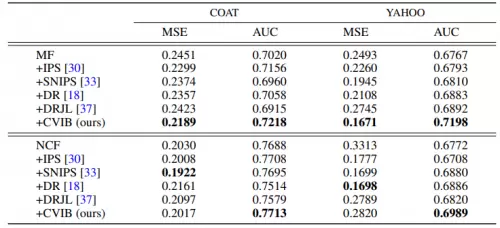
表格 2 实验结果 (nDCG指标)
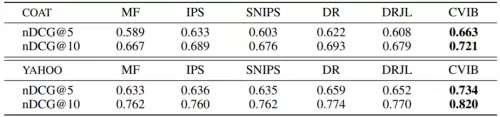
在模型的鲁棒性测试中,该方法表现出较强的稳健性。对超参数变化敏感性不强,非常适用于实际场景的部署。相比于传统推荐系统,这种基于信息理论的推荐系统纠偏方法呈现出几大创新点:其一,基于信息论和反事实理论学习方法,无需执行线上随机流量试验,节省了大量训练成本;其二,模型参数鲁棒性较好,适合工业场景实际部署;其三,目标函数具有很广泛的适用范围,领域内绝大部分的模型均可以适用该目标函数来进行模型纠偏,而无需对现有模型结构进行修改,兼容性较强。
商业应用无处不在 推荐系统纠偏方法重拾内容多样性
放眼当下,推荐系统的商业应用无处不在,不少主流APP都应用到了推荐系统。例如,旅游出行类中,携程、去哪儿等会推荐机票、酒店等;外卖平台类中,饿了么、美团等会推荐饭店;电商购物类中,京东、淘宝、亚马逊等会推荐“可能喜欢”的物品;新闻资讯类中,今日头条、腾讯新闻等会推送用户感兴趣的新闻....几乎所有APP或网站都在应用推荐系统。
腾讯天衍实验室作为腾讯布局医疗领域背后的技术提供者,主要专注于医疗健康领域的AI算法研究及落地,并且不断研究与拓展AI医疗技术发展的边界。目前,腾讯天衍实验室主要将算法能力输出到微信支付九宫格的腾讯健康小程序、QQ浏览器、微信搜一搜等。例如在疫情期间,天衍实验室运用AI大数据技术,通过腾讯健康疫情问答推荐版块,为用户带来关于疫情的多方面的内容和咨询服务,而不仅仅关注用户个人和集体偏好,基于信息理论模型,快速进行模型训练对推荐系统进行纠偏,极大的节省了时间和经济成本。
同时,在腾讯觅影的AI导辅诊平台上,日常的医疗资讯推荐上也应用了该方法为用户推荐相关内容,大大提升了推荐内容的多样性和公平性,同时也增强了用户体验。比如对于患有糖尿病的患者,其日常关注的内容可能都与糖尿病相关,如果不对推荐系统进行纠偏,系统会越来越倾向于推荐糖尿病相关内容给到用户,而经过系统纠偏之后,还会给患者推荐一些运动、睡眠等其他健康知识,帮助用户更加全面的了解自身健康。可以见得,推荐系统纠偏方法具有非常广泛的应用价值,未来,腾讯天衍实验室还将继续扩大其应用范围,以期为用户提供更优质的服务。
相关文章
- 腾讯云与阶跃星辰达成战略合作,共塑大模型时代智能座舱新体验
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- TINNOVE梧桐科技与腾讯音乐共建座舱AI“声学创新实验室”正式挂牌
- 腾讯公司与浙江大学达成深度合作,共建联合实验室培育硬核技术人才
- 腾讯会议发布“天籁智联”协议,面向硬件生态伙伴全面开放
- 腾讯音乐与长安汽车打造首个座舱AI声学技术研发中心 推动车载音频体验迈向生态协同
- 腾讯云与赞同科技深化金融科技合作——技术研讨凝共识 装机实操促落地
- 从Agent 浪潮到组织变革,腾讯云携手业界专家共探OpenClaw时代的安全边界与企业进化
- 腾讯云TVP走进招商局,共探具身智能与 Agent 协同演进新路径
- 新经济企业TOP500连续六年发布,腾讯五年蝉联榜首、比亚迪首进前三
- 腾讯云发布ADP Agent Portal:企业级智能体统一纳管、高效运营
- 腾讯云与聚水潭战略合作 助力电商SaaS全链路智能化与全球化升级
- 大模型智能体行业元年来临,腾讯/阿里/微美全息集体锁定AI+Agent高增长赛道!
- QQ开启AI社区运营新时代,腾讯频道Skill正式上线
- 网络媒体论坛郑州启幕,腾讯以AI为纽带,共建向上向善数字生态
- 腾讯云吴运声:构建实用、可靠、易管的企业级Agent平台,让AI人人可用
人工智能企业
更多>>



人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench


