英伟达AI再创全球最快模型训练速度,助力超级计算无处不在
2021/07/01 14:46AI云资讯11142
全球最快AI模型训练速度
MLPerf是由学术界、研究实验室和业界人士组成的人工智慧领袖联盟,基于“打造公平、实用基准”的使命,为硬体、软体和服务的训练与推断效能提供中立评估,且全部在预定条件下执行。该基准测试基于当今最常用的AI工作负载和场景,涵盖计算机视觉、自然语言处理、推荐系统、强化学习等。
此前,英伟达生态系统一直在测试中表现出不俗的成绩,例如在2020年7月底公布的第三轮MLPerf榜单中英伟达A100 Tensor Core GPU 在全部八项基准测试中展现了最快性能。在实现总体最快的大规模解决方案方面,利用HDR InfiniBand实现多个DGX A100系统互联的服务器集群DGX SuperPOD系统也同样创造了业内最优性能。
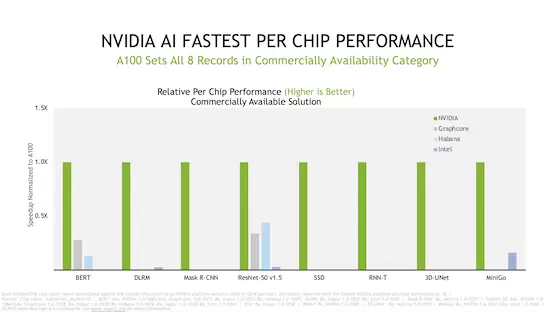
本次MLCommons的新一轮赛事,是英伟达生态系统第四次参加MLPerf训练测试。在芯片对比中,英伟达及其合作伙伴在最新商用解决方案测试的所有八项基准测试中都创造了纪录。
测试中,七家公司对至少十几款市售系统进行了测试,由英伟达AI助力的系统超过了75%,除英伟达外,还包括了戴尔、富士通、技嘉、浪潮、联想、宁畅、超微等。仅有Google、Graphcore、Habana、英特尔、鹏程科技使用其它系统。其中英伟达及合作伙伴或采用了NVIDIA A100 GPU,或计划为在线实例、服务器和PCIe卡采用NVIDIA A100 GPU,以及包括近40款NVIDIA认证系统。
实现这一成绩背后的原因在于,尽管A100 Tensor Core GPU在去年已经雄霸MLPerf测试,英伟达工程师又使其在GPU、系统、网络和AI软件方面继续实现了进步。例如,通过全新的使用CUDA Graphs启动完整神经网络模型的方法,能够解决过去测试中的CPU瓶颈;另在大规模测试中使用的是NVIDIA SHARP,整合网络交换机内的多项通信工作,从而减少网络流量和等待CPU的时间。
助力超级计算无处不在
相较上一轮测试成绩,英伟达将性能整体提升了2.1倍,另通过多次测试结果综合来看,英伟达在两年半的时间内将性能提高了多达6.5倍。性能的快速增长,也为客户在拓展人工智能的全新落地领域提供了更多可能。
此前,在AI应用案例中,棋类的深度学习、图形类别识别、物体重量辨识、物体高度辨识、自然语言处理等已经被广泛应用,测试项中的MiniGo、MaskR-CNN、SSD等也呼应了上述的应用需求。如今在MLPerf测试中加入的RNN-T、3D-UNet测试,也预示着行业对于如语音辨识、生物医学图像方面的全新需求。英伟达及合伙伙伴在八项测试中的创纪录表现,也意味着在实际的人工智能应用中,能够带来更高的效率。
目前,德国癌症研究中心就与英伟达展开合作,将3D-UNet等创新技术引入医疗市场,来实现生物医学图像上的功能。这一合作也证明了MLPerf的测试结果能够给IT机构和开发者以极大的参考,来找到合适的解决方案,以加速特定项目和应用。本次测试中,英伟达AI在3D-UNet上的性能表现甚至是第二名的6倍之多。

人工智能的训练无疑是一项超级计算级别的挑战,而英伟达正在让这一能力变得无处不在。根据全球前500的超级计算机榜单显示,基于NVIDIA DGX SuperPOD的Selene是全球最快的商用AI超级计算机。而榜单上的其他十几台系统也均基于NVIDIA DGX SuperPOD架构。
此外,特斯拉构建的来获得自动驾驶模型的AI超级计算机系统,也选择英伟达的硬件架构作为自动驾驶与辅助驾驶深度学习训练超级电脑AUTOMOTIVE的关键元件。该系统共具备720个节点,每个节点拥有8块NVIDIA A100 Tensor Core GPU,共计5760块。
不久前,微软也宣布由NVIDIA A100 Tensor Core GPU驱动的Azure ND A100 v4云GPU实例全面上市。这些虚拟机(VM)针对的是拥有高性能和高要求工作负载的客户,如人工智能(AI)和机器学习(ML)工作负载。
甚至,英伟达还和美国国家能源研究科学计算中心打造了世界上最快的AI超级计算机,这款名为Perlmutter的超级计算机拥有6144个NVIDIA A100 Tensor Core GPU,从而可以负责拼接有史以来最大的可见宇宙3D地图以及其他项目。以往,研究人员准备一年的星系数据发布需要几周或几个月时间,而通过在英伟达助力下的Perlmutter仅需要几天就能完成任务。
相关文章
- 英伟达与微软牵头成立开放AI安全联盟,OpenAI、谷歌及Anthropic均未加入
- 英伟达缩减Vera Rubin芯片内存配置,因HBM4成本高涨将占单机架总成本29%
- 英伟达图形研究亮相SIGGRAPH 2026:21项突破性技术加速仿真与物理AI
- SpaceX向富士康下了520亿美元的巨额订单,采购搭载英伟达GB300芯片的AI服务器机架
- 英伟达Rubin全液冷时代,川润股份“算力液冷+绿色能源”全链条闭环服务卡位千亿赛道
- AMD EPYC Venice处理器到2027年将以675万颗的出货量超越英伟达Vera CPU
- 英伟达称其AI数据中心采用高温运行设计,可大幅减少用水量
- 英伟达抢建物理AI算力工厂,微美全息(WIMI.US)锚定芯片赛道掀起GPU热潮!
- 云工场科技加快多元智算布局,构建 AMD、沐曦、英伟达协同算力体系
- 数据中心耗电远超电网负荷,迫使英伟达与谷歌在2026年第三季度前启动800V直流电架构改造
- 苹果在新版Siri上作出妥协:依靠英伟达B200 GPU加密技术,防止谷歌窃取用户数据
- 英伟达发布RTX Spark芯片,高调杀入PC市场
- 维谛(Vertiv)将在COMPUTEX展示首个面向英伟达NVIDIA Omniverse DSX Blueprint的全融合物理基础设施数字孪生能力
- AI驱动量子计算风口已至!英伟达/微美全息抢占高地锁定量子生态席位!
- 英伟达首席财务官调侃竞争对手因存储芯片短缺措手不及
- SpaceXAI宣布将向Anthropic开放搭载22万张英伟达GPU的巨像一号超级计算机
AI企业
更多>>




AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


