术业有专攻——AI系统主控CPU英特尔至强6新品处理器浅析
2025/06/19 17:02AI云资讯12140
一、至强6与NVIDIA GPU协同的硬件基础

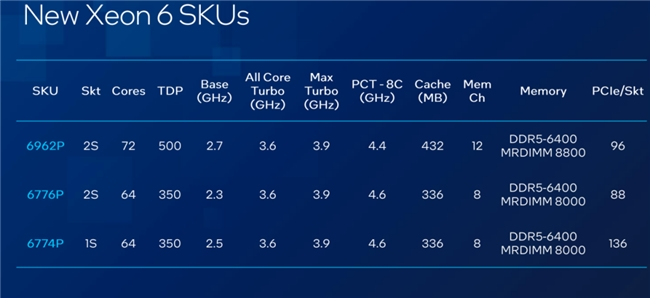
在 AI 异构计算架构中,英特尔至强6处理器作为主控CPU可以与NVIDIA最新GPU 很好地协同。根据英伟达官网信息,目前其DGX B300系统选择至强6776P作为唯一主控CPU,采用双路配置,通过UPI总线实现CPU间互连。这8个GPU通过NVLink高速互连,是性能比较高端的DGX,为训练等应用而设计。
作为主控CPU,它和GPU协同工作,而这个系统的性能受到诸多因素的影响,这里列出的是最主要的因素,包括I/O、核心性能、内存(包括带宽和容量)、CPU上的预处理或卸载(offload)能力、整体CPU系统的RAS,以及各种硬件的外形设计等。这些都会影响整个AI系统的端到端性能,因此AI系统通常比较复杂。

这一设计的性能提升要点在于:
1.业界领先的I/O通道和内存能力
AP平台的双路至强6最多可以提供192条PCIe 5.0通道,也就是可以每路提供96条通道,相比上一代提升20%,内存通道也可以高达12个。直接匹配多GPU的高速接入需求,避免因通道不足导致的带宽瓶颈。
在SP平台上,英特尔还提供了一个差异化的产品,就是在单个CPU插槽上提供了更丰富的I/O资源(Rich I/O one socket),总共有136根的PCIe通道,持单插槽连接多块加速卡与存储设备,适用于边缘端“预处理+推理”一体化场景。同时,其高带宽内存可容纳更大模型参数,提升训练效率。在推理场景中,灵活的核心配置确保资源高效利用,满足多样化需求。
2.核心性能优化
至强6区别于上一代产品的关键技术突破是Priority Core Turbo(PCT),其技术本质是通过 Speed Select(SST)将单路CPU核心划分为两组:最多8个高频核心(PCT 核心)与剩余低频核心。在DGX B300场景中,这一技术直接服务于 “CPU 驱动 GPU” 的典型需求,实现高频核心的精准调度:当 GPU 需要快速获取预处理数据(如从内存读取原始数据并完成清洗、特征工程)时,8个PCT核心可睿频至4.6GHz(传统64核SKU最大睿频为3.9GHz),相比全核睿频(3.6GHz)提升28%。这一特性缩短了数据从CPU到GPU的传输延迟。
3.资源分配的灵活性
PCT核心数量可通过BIOS或 SST-TF工具动态配置,客户可根据实际负载调整——客户在使用时可以根据需要选择8个、6个、4个或2个PCT核心。例如推理场景中若仅需4块GPU工作,可配置4个PCT 核心对应驱动,避免资源浪费。与上一代 Max Turbo 技术的差异在于:PCT允许全核在线(无需半数核心休眠),且维持相同 TDP(350W)与散热设计,确保硬件兼容性,降低客户部署成本。
4.更强的内存架构兼容性
更高的内存带宽对于AI工作负载至关重要,因为AI的工作流程是一个完整的数据处理管道,而非单一环节。在这一过程中,CPU首先负责预处理,从内存中读取数据并进行初步处理,随后将数据传输至GPU。比如,至强6支持8通道到12通道的DDR5-6400内存,还支持MRDIMMs,能提供更高的30%带宽。
在LLM的生成式推理(如文本续写)中,自注意力机制需为每个已处理的Token生成并存储键(Key)和值(Value)矩阵,即KV Cache。KV Cache避免了在解码阶段重复计算历史Token的注意力状态,但会随序列长度线性增长,占用大量GPU显存,需要卸载到下一级存储中。对于CXL内存来说,有一个典型用例是KV Cache的卸载,通过用CXL内存去替代SSD,这样KV Cache的访问速度显著增快,从而提升了性能。
5.RAS和数据预处理
在企业级 AI 训练场景中,系统可靠性直接影响算力利用率与TCO。至强6的RAS 体系覆盖全硬件链路,可以通过RAS特性来可以提高I/O的稳定性、内存系统稳定性、UPI链路稳定性、CPU及平台稳定性。CPU卸载则是针对MoE(混合专家)模型的另一种优化方式。目前市场上已有诸多关于通过AMX矩阵技术将部分MoE模型中的专家层卸载至至强处理器的案例。
二、为何是至强6776P?
NVIDIA DGX B300选择的双路至强 6776P 的核心价值在于业界领先的I/O能力、领先的内存带宽、大内存容量、领先的RAS能力已经为特定AI负载优化的PCT产品。
其4.6GHz的睿频能力显著加速数据处理,PCT核心以4.6GHz频率加速数据预处理(如文本分词、图像解码),通过高速 PCIe 通道将数据传输至GPU,形成 “CPU 预处理→GPU 计算”的流水线作业。这款处理器拥有单路88条PCIe通道,双路则达到176条。
英伟达选择了2 DPC架构(每颗CPU提供8通道内存,每通道2个DIMM)进行配置,双路系统可搭载32根DIMM,内存最大容量达8TB。
综述:开放生态的实际意义
至强6的核心优势在于开放性与兼容性。客户硬件选择自由,可以根据成本动态切换,避免被单一供应商锁定。在软件生态兼容层面,至强6也完全支持主流 AI 框架(如 TensorFlow、PyTorch)与云原生技术,无需重新开发适配层,降低技术迁移成本。
从英伟达的选择逻辑看,DGX B300 采用至强6应该并非单一性能导向,而是综合考量了生态开放性、成本可控性与技术成熟度 —— 至强 6 作为量产级产品,其稳定性与供应链可靠性已通过大规模数据中心验证。
至强6在搭配NVIDIA GPU场景中的价值,本质上源于其对“CPU 角色”的清晰定位:核心数量或睿频频率,都是围绕 GPU 协同需求而定,根据用户的不同需求,也可以选择不同的CPU型号。在关键路径(如高频数据传输、大内存容量、系统稳定性)上,至强6可以实现精准优化。对于企业客户而言,这意味着在 AI 基础设施建设中,可通过标准化硬件获取可预期的性能提升,同时避免为冗余功能支付额外成本。这种 “需求导向型” 技术路线,或许正是其成为英伟达首选主控 CPU 的核心原因。
相关文章
- 扩产、提质、稳交付,英特尔代工为AI算力供给“加码”
- 英特尔推出航天系统级芯片Starfire:搭载8核心、18A制程技术,可耐受125℃高温
- 英特尔拟推出14A2节点,采用双面供电技术,提供更成熟的制程工艺
- 轻盈随行,性能越级!英特尔酷睿 Ultra 5 325+4Xe 激活轻薄本新潜力
- 马斯克的TeraFab招揽英特尔18年资深老将出任代工经理,主导550亿美元芯片制造项目
- 三星准备用1.4纳米工艺技术挑战英特尔和台积电,目标在2029年量产
- 英特尔18A-P风险试产:散热提升最高40%,性能功耗双双优化
- 全面进化!搭载英特尔锐炫G3 Extreme,微星CLAW 8 EX AI+掌机2026首发开卖
- 忆联×英特尔×新华三:以“存算协同“破局AI智算性能瓶颈
- 前SK海力士CEO李锡熙重返英特尔,出任晶圆代工与先进封装技术的执行副总裁
- 苹果将与英特尔合作,设计和制造M7芯片和下一代iPhone芯片
- 异构算力底座与大小脑融合:英特尔如何加速物理AI与具身智能的规模化落地
- 英特尔宋继强:以CPU为核心的异构算力,推动智能体和物理AI演进
- 英特尔制程双线推进:Intel 18A良率稳步爬坡,Intel 14A目标2029年量产
- 花旗银行报告称,台积电在AI领域的主导地位不会受到英特尔威胁
- 苹果的下一代MacBook和iPhone芯片或将采用英特尔的18A-P和14A工艺技术制造
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


